Bellman 公式中总结了对于 With model RL 的基本原则和更新方式,但是现实中的问题通常不能保证有严谨的公式。本笔记想对 model free RL的基本方法和思想进行一些概括和总结,好对后面的Actor Critic等算法打好基础。此处所说的 model 指的是环境模型,即对环境的状态转移概率和奖励机制进行建模。在拥有 Model 的情况下(类似围棋),智能体可以预知执行某个动作后环境会发生怎样的变化(确定性或随机性);而 Model-free RL 则是要在不掌握这些环境动态规律的情况下,直接通过与环境的交互来学习策略。
蒙特卡洛方法
蒙特卡罗方法是所有 model free RL 的基础,因为没有了 Model 预测执行某个动作后会发生,就只能通过通过大量采样取平均来近似期望回报,从而估计 q(s,a)。
Algorithm 5.1: MC Basic (a model-free variant of policy iteration)Initialization: Initial guess π0.Goal: Search for an optimal policy.For the kth iteration (k=0,1,2,…), doFor every state s∈S, doFor every action a∈A(s), doCollect sufficiently many episodes starting from (s,a) by following πkPolicy evaluation:qπk(s,a)≈qk(s,a)=the average return of all the episodes starting from (s,a)Policy improvement:ak∗(s)=argmaxaqk(s,a)πk+1(a∣s)={10if a=ak∗otherwise
可以看到这个方法基本就是 Policy iteration 方程的 model free 方法,显示 Policy evaluation 然后接着 Policy improvement。但是注意原来的 PE 是更新状态 V 状态价值函数,此处改为更新 Q 状态-动作价值函数,这是因为在 PI 这步,model-based 方法是通过该方程求解:
a∗=argamaxs′∑p(s′∣s,a)[r(s,a,s′)+γvπ(s′)]
但是 model free 中,p(s′∣s,a) 是未知的,所以采用对状态-动作奖励函数进行优化。
Collect sufficiently many episodes starting from (s,a) by following πk
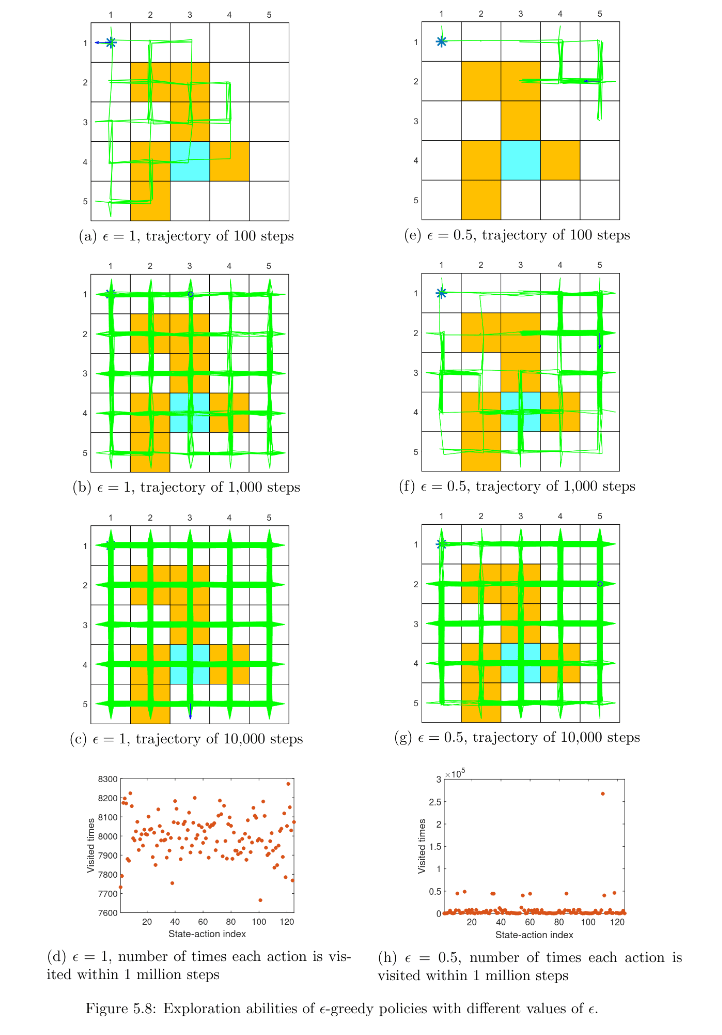
π(a∣s)={1−ε+∣A(s)∣ε∣A(s)∣εfor the greedy action for the other∣A(s)∣−1actions
最后改进为:
Algorithm 5.3: MC ϵ-Greedy (a variant of MC Exploring Starts)Initialization: Initial policy π0(a∣s) and initial value q(s,a) for all (s,a).Returns(s,a)=0 and Num(s,a)=0 for all (s,a).ϵ∈(0,1]Goal: Search for an optimal policy.For each episode, doEpisode generation: Select a starting state-action pair (s0,a0) (the exploring startscondition is not required). Following the current policy, generate an episode of length T:s0,a0,r1,…,sT−1,aT−1,rT.Initialization for each episode: g←0For each step of the episode, t=T−1,T−2,…,0, dog←γg+rt+1Returns(st,at)←Returns(st,at)+gNum(st,at)←Num(st,at)+1Policy evaluation:q(st,at)←Returns(st,at)/Num(st,at)Policy improvement:Let a∗=argmaxaq(st,a) andπ(a∣st)=⎩⎨⎧1−∣A(st)∣∣A(st)∣−1ϵ,∣A(st)∣1ϵ,a=a∗a=a∗
Algorithm 7.1: Optimal policy learning by SarsaInitialization: αt(s,a)=α>0 for all (s,a) and all t.ϵ∈(0,1). Initial q0(s,a) for all (s,a). Initial ϵ-greedy policy π0 derived from q0.Goal: Learn an optimal policy that can lead the agent to the target state from an initial state s0.For each episode, doGenerate a0 at s0 following π0(s0)If st(t=0,1,2,…) is not the target state, doCollect an experience sample (rt+1,st+1,at+1) given (st,at): generate rt+1,st+1by interacting with the environment; generate at+1 following πt(st+1).Update q-value for (st,at):qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γqt(st+1,at+1))]Update policy for st:πt+1(a∣st)=1−∣A(st)∣ϵ(∣A(st)∣−1)if a=argmaxaqt+1(st,a)πt+1(a∣st)=∣A(st)∣ϵotherwisest←st+1,at←at+1
Algorithm 7.2: Optimal policy learning via Q-learning (on-policy version)Initialization: αt(s,a)=α>0 for all (s,a) and all t.ϵ∈(0,1). Initial q0(s,a) for all (s,a). Initial ϵ-greedy policy π0 derived from q0.Goal: Learn an optimal path that can lead the agent to the target state from an initial state s0.For each episode, doIf st(t=0,1,2,…) is not the target state, doCollect the experience sample (at,rt+1,st+1) given st: generate at following πt(st);generate rt+1,st+1 by interacting with the environment.Update q-value for (st,at):qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γmaxaqt(st+1,a))]Update policy for st:πt+1(a∣st)=1−∣A(st)∣ϵ(∣A(st)∣−1)if a=argmaxaqt+1(st,a)πt+1(a∣st)=∣A(st)∣ϵotherwiseAlgorithm 7.3: Optimal policy learning via Q-learning (off-policy version)Initialization: Initial guess q0(s,a) for all (s,a). Behavior policy πb(a∣s) for all (s,a).αt(s,a)=α>0 for all (s,a) and all t.Goal: Learn an optimal target policy πT for all states from the experience samples generated by πb.For each episode {s0,a0,r1,s1,a1,r2,…} generated by πb, doFor each step t=0,1,2,… of the episode, doUpdate q-value for (st,at):qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γmaxaqt(st+1,a))]Update target policy for st:πT,t+1(a∣st)=1if a=argmaxaqt+1(st,a)πT,t+1(a∣st)=0otherwise
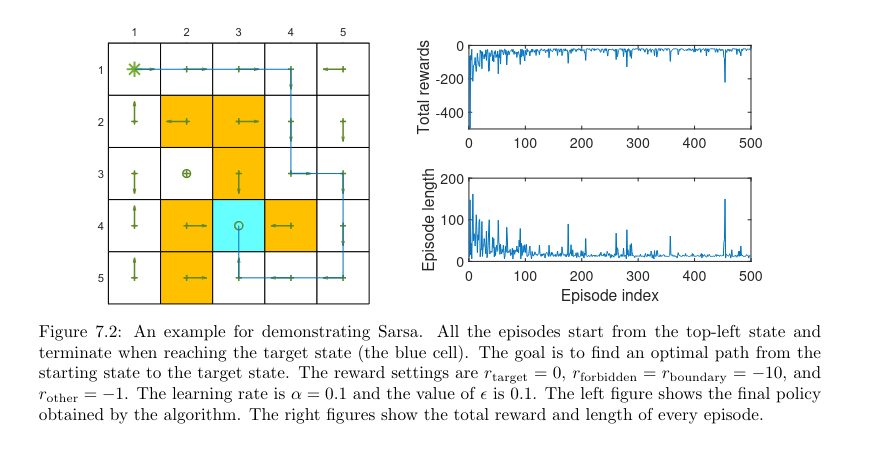 可以看到有几步奖励函数掉的非常厉害,这是因为 -Greedy 选取了次优的动作,导致走向一个很差的轨迹。
可以看到有几步奖励函数掉的非常厉害,这是因为 -Greedy 选取了次优的动作,导致走向一个很差的轨迹。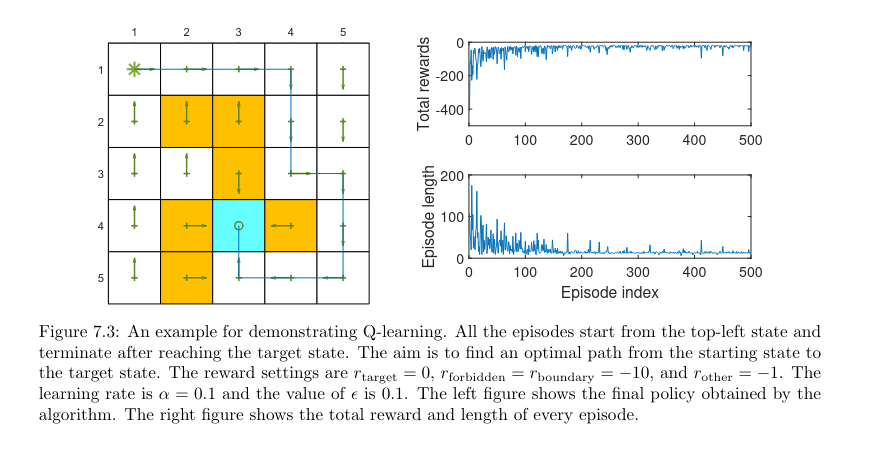 可以看到 Q-learning 没有陡峭的奖励曲线崩溃,不像 Sarsa,它求得是动作空间中的最优值。
可以看到 Q-learning 没有陡峭的奖励曲线崩溃,不像 Sarsa,它求得是动作空间中的最优值。