Morphologically Symmetric Reinforcement Learning for Ambidextrous Bimanual Manipulation | PDF
论文动机
论文想模仿人类的双手合作的案例,比如可以在简单的事上轻易地对称左右手所做的事但是在复杂的事情上可以专注于一只手的精细动作。先前的研究基本都是研究机器人腿部而少有研究手部的对称。
同时,通过RL进行双臂训练是一个很大的挑战:
- 高维观测和动作空间使得策略学习困难
- 奖励函数可能导致双臂不能同时获得最佳策略
- 精细的双手动作相当于多任务学习,虽然可以为每个子任务定义一个奖励函数但是调参复杂
- RL为sim-to-real的gap和安全问题提出挑战
论文方法
针对以上问题,论文提出了一个双臂灵巧学习的强化学习框架SYMDEX(SYMmetric DEXterity),并总结了以下创新点:
- 形态上包含对称的学习方式
- 可扩大泛化的多臂学习方案(通过把复杂精细任务拆成子任务分别进行强化学习后合成全局策略)
- 完整的sim-to-real转化
论文用马可夫决策过程(MDP)对系统进行建模,并用图论赋予此系统对称性。 论文用POMDP定义了一个元组:
- : 和 MDP 相同
- : 观测空间 (observation space)
- : 观测概率模型 (observation model),即在状态 下执行动作 ,智能体得到观测 的概率 关键区别:
- 在 POMDP 中,智能体 不能直接看到 ,只能通过 得到一个观测 。
- 因此智能体需要维护一个 信念状态 (belief state):即对真实状态 的概率分布 ,并根据贝叶斯法则不断更新。
同时利用图论的等变形和不变性使POMDP具有了对称性。
定义 A.5(-等变和 -不变映射)。设 和 是具有相同对称群 的两个向量空间,分别带有群作用 和 。一个映射 被称为 -等变的,如果它与群作用可交换,使得:
-等变映射的一个特例是 -不变映射,它们与群作用可交换,并且具有平凡的输出群作用 ,使得 对所有 成立。即:
将这个性质代入POMDP中: 定义 B.1(对称 POMDP)。一个 POMDP 具有对称群 ,当状态空间 和动作空间 承认群作用 和 ,且 (奖励函数)都是 -不变的。也就是说,对于每一个 ,,和 ,我们有:
满足方程 (2) 的 POMDP 被约束为具有最优策略和价值函数,它们满足:
也就是利用这个性质,可以给让双臂机器人的任务和动作进行对调,比如论文中举出了一个打蛋的操作,分为拿着碗和打蛋两个子动作,通过群动作来对agent-task对进行变换:
这个公式表示对原始动作进行群对称化操作最后可以得到在另外一个臂上的观测空间的对称,同时对等变的任务策略和观测函数进行变化,导致镜像后的左臂的动作为原环境中右臂动作的对称版本,反之亦然。
同时这个操作适配多agent。
另外一个创新点是论文中提出的等变神经网络,使得策略学习具有对称性
其中就是等变神经网络,是神经网络的参数。 满足
- 置换 agent 轴()
- 置换子任务轴()
- 对几何通道做符号翻转/通道交换
后输出结果完成相应变化
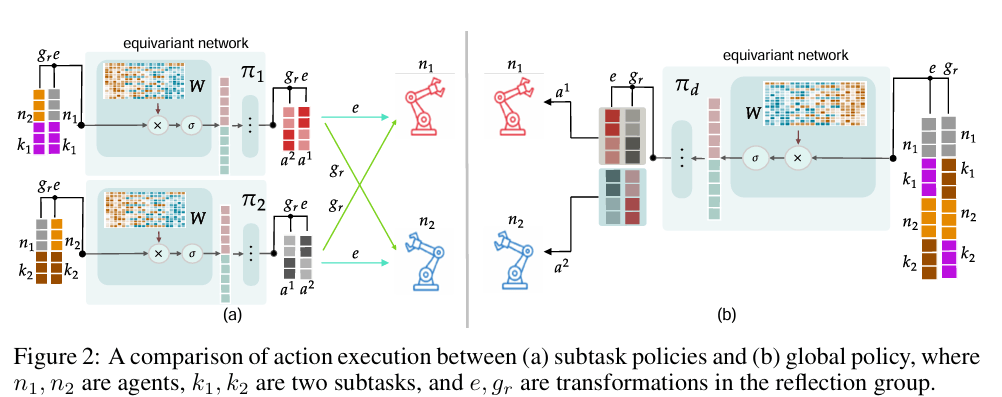
最后对策略遵从teacher-student范式进行蒸馏,获得全局参数。