实验动机
目前的机械臂策略缺少迅速准确的技巧,比如抓住高速物体,这同样也是训练多agent协调的方式。 同时MARL为双臂机器人提供了强大的训练框架,使得多臂训练不再是训练多个机械臂的共享参数,而是针对每个机械臂的参数进行训练。
论文方法
论文为双臂抓物技巧训练提出了Heterogeneous(异质的)-Agent Reinforcement Learning方法并采用HAPPO作为优化目标。 论文的主要成果是:
- 训练双臂抓取技巧
- 对抗-合作训练方式
- 用多物体验证
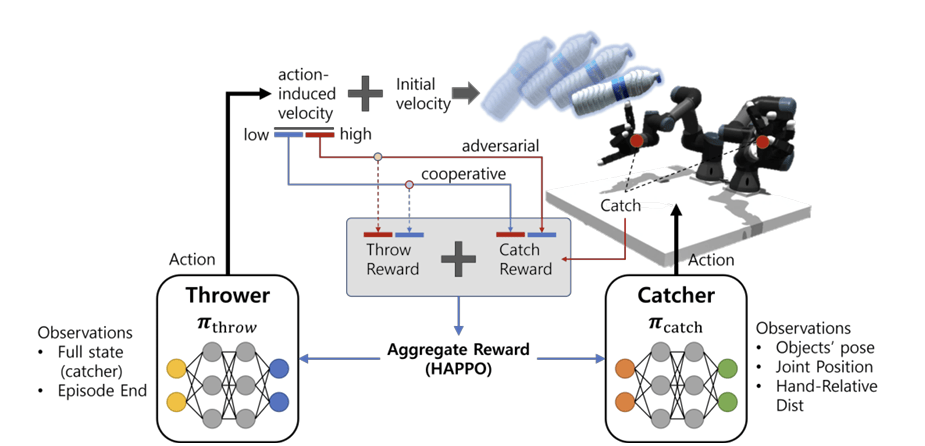
catcher/Thrower agent 文章创新点“异质”就体现于此,两个agent观测空间,动作空间和任务都不相同。 对于catcher,它的观测空间是254维,而thrower的观测空间是所有物体的状态和catcher的状态。前者的动作空间是44维的,后者的动作空间只有6维。 具体而言,thrower的策略是: 系统设计 论文以MAPPO为目标优化: 其中 详细原理见MARL
对抗-奖励奖励函数 通过设计奖励函数,可以使得两个智能体都有效学习到需要学习的策略:
policy 网络架构 两个智能体都采用了[1024, 512, 256]大小的MLP加上ELU作为激活函数,遵从Actor-Critic架构,用PPO在HARL框架内训练。
- 感觉这个研究更像是应用先前研究的实现?大部分算法和优化方式都是先前研究已经提出的