本文档计划从简单到详细记录在PI05的一个checkpoint上进行训练中遇到的各种问题等。
规划
首先的问题是,任务是什么?训练集哪里来?task的质量决定了训练和方法的价值。由于本次实践的目的是熟悉Lerobot的训练脚本,看有什么潜在的坑,所以采取简单的Libero作为测试项目,并且使用社区开源数据集进行测试。目的是学习掌握
- 配置wandb,观察训练期间的loss等数据
- 打印一个完整 batch 的所有 key、shape、数值范围
- 可视化归一化前后的 action 分布(画直方图)
- 在 forward 里 print flow matching 的 timestep 采样分布
- 比冻结/不冻结 VLM 的训练曲线和 eval 成功率
- 记录不同 checkpoint 步数的 LIBERO 各子任务成功率
- 用相同 checkpoint 不同 prompt 跑推理,观察动作差异
- 修改 num_steps(flow matching 解码步数)看推理速度和质量的 trade-off
遇到的问题
首先就是git clone不了,机房没有外网环境,解决办法是在本机clone一遍后用
-
scp传输
# 本地 → 远程 scp file.txt user@host:/path/to/dest/ # 远程 → 本地 scp user@host:/path/to/file.txt ./local/ # 传输整个目录(加 -r) scp -r my_folder/ user@host:/path/to/dest/ -
rsync传输,更优,支持增量传输
# 同步目录 rsync -avz my_folder/ user@host:/path/to/dest/ # 加 --progress 显示进度 rsync -avz --progress file.txt user@host:/path/ # 可以排除.git文件夹中的pack文件,减少传输时间 rsync -avz --progress ~/lerobot/ A100-36.163.20.107:/mnt/data/linjianqi/lerobot/
搞定后先是下载环境:
conda create -y -n lerobot python=3.10 && conda activate lerobot
pip install -r requirement-ubuntu.txt -i https://mirrors.ivolces.com/pypi/simple
pip install -e ".[pi]"其中由于是安装配置文件,所以要加上-r的参数。同时使用镜像源加速。
使用mihomo获得外网环境
由于使用镜像源太过麻烦,所以打算直接使用clash内核mihomo以CLI形式获得外网环境。
由于没有sudo权限,下载二进制压缩包版本.gz结尾。传到主机后使用
gunzip mihomo-linux-amd64-v1.19.20.gz
chmod +x mihomo-linux-amd64-v1.19.20
mv mihomo-linux-amd64-v1.19.20 mihomo
mkdir -p mihomo-config这几个命令解压,赋予权限,重命名以及创建配置文件夹。再将本机的yaml配置文件上传到服务器。 创建一个tmux 窗口,由于不认识ghostty终端,需要设置环境变量。
export TERM=xterm-256color
tmux new -s lerobot
# tmux a -t lerobot 重新进入section用
/mnt/data/linjianqi/mihomo -d /mnt/data/linjianqi/mihomo-config
# 或
./mihomo -d ./mihomo-config
# 然后修改指令运行的端口
export http_proxy=http://127.0.0.1:7890
export https_proxy=http://127.0.0.1:7890
# 不用时使用指令
unset http_proxy https_proxy即可开启mihomo。
可以使用set -g mouse on来开启鼠标滚动。
(base) /mnt/data/linjianqi$ curl -I https://github.com
HTTP/2 200
date: Sat, 14 Feb 2026 08:39:50 GMT成功。 之后就是正常进行操作了。
对于VSCode,则需要用Ctrl+Shift+P输入Preferences: Open Remote Settings (SSH)后加入
{
"terminal.integrated.env.linux": {
"http_proxy": "http://127.0.0.1:7890",
"https_proxy": "http://127.0.0.1:7890"
}
}如果其他用户占用了改端口,可以在配置文件和export进来的端口中修改再启动。
用以下命令切换节点:
curl -X PUT http://127.0.0.1:19090/proxies/%F0%9F%9A%80%20%E8%8A%82%E7%82%B9%E9%80%89%E6%8B%A9 \
-H "Content-Type: application/json" \
-d '{"name":"🇨🇳 台湾 01"}'
curl --noproxy '*' -X PUT 'http://127.0.0.1:19090/proxies/%E4%B8%80%E4%BA%91%E6%A2%AF%20web01.1yunti.com' \
-H "Content-Type: application/json"
-d '{"name": "[trojan] 台湾 01"}'
配置环境
正常安装即可,首先创建conda环境,此处用3.10版本的Python,然后安装依赖。注意在存储非常紧张的情况下(这貌似还蛮常见的),需要重新指定conda的安装区域和安装缓存。
conda create -n lerobot python=3.10
# 可以通过 -p 指定路径,此时不可指定名字
# 在 data1 创建一个新的缓存目录
mkdir -p /mnt/data1/linjianqi/conda_pkgs
# 修改 conda 配置,把这个路径设为首选缓存路径
conda config --add pkgs_dirs /mnt/data1/linjianqi/conda_pkgs
# 清理缓存
conda clean --all
# 下载
conda create -p /mnt/data1/linjianqi/conda/lerobot python=3.10
# 注意启动环境也要打绝对路径
conda activate /mnt/data1/linjianqi/conda/lerobotpip install -r requirements-ubuntu.txt
安装lerobot依赖,然后使用
pip install -e ".[pi]"安装PI05所需的依赖。
| Checkpoint | 用途 | 模型大小 |
|---|---|---|
lerobot/pi05_base | 基础预训练模型,用于微调到自定义数据集 | ~4B params |
lerobot/pi05_libero_base | 在 LIBERO 上继续预训练的基础模型 | ~4B params |
lerobot/pi05_libero_finetuned | 在 LIBERO 上微调好的模型,可直接评估 | ~4B params |
| 然后用 |
# 用 huggingface-cli 或 hf download
huggingface-cli download lerobot/pi05_base
# 如果不行可以使用国内镜像源
export HF_ENDPOINT=https://hf-mirror.com
hf download lerobot/pi05_base
# 或 git clone
git lfs install
git clone https://huggingface.co/lerobot/pi05_base安装PI05的开源权重
安装wandb
直接使用pip安装然后login即可
pip install wandb
wandb login
进行测试
首先要设置渲染后端,对于无桌面服务器来说是必须的,同时安装在LIBERO上测试所需依赖:
export MUJOCO_GL=egl
pip install -e ".[libero]"其中在配置环境的时候遇到了严重的环境问题,主要出在LIBERO环境冲突,主要原因是下载LIBERO环境的时候没有在pyproject.toml中查看包的版本,而是去谷歌随便搜了个环境下载,这导致了严重的版本冲突,无法启动脚本,见eval.sh 环境版本冲突问题诊断与修复总结。
同时,在使用LIBERO这个评测方案的时候也面临许多问题,包括:
- LIBERO摄像头数量和PI05所需摄像头数量不一致,需要将一个输入摄像头用mask填充
- LIBERO输出键名和PI05接受键名不一致 这是因为pi05_base这个权重自身导致的。如果切换到pi05_libero_finetuned这个权重就可以测出80%左右的成功率了。也就是这次训练的目标是用训练和微调解决这两个问题
| 实际含义 | libero 输出的键名 | pi05 期望的键名 |
|---|---|---|
| 主视角摄像头 | observation.images.image | observation.images.base_0_rgb |
| 手腕摄像头 | observation.images.image2 | observation.images.right_wrist_0_rgb |
然后使用lerobot.eval这个脚本测试会显示bug。
export MUJOCO_GL=egl
lerobot-eval \
--policy.path=lerobot/pi05_base \
--policy.n_action_steps=10 \
--env.type=libero \
--env.task=libero_10 \
--eval.batch_size=1 \
--eval.n_episodes=10 \
--output_dir=./eval_logs/pi05_libero10 \
--env.max_parallel_tasks=1 \Traceback (most recent call last):
File "/mnt/data1/linjianqi/conda/lerobot/bin/lerobot-eval", line 10, in <module>
sys.exit(main())
File "/mnt/data1/linjianqi/lerobot/src/lerobot/scripts/lerobot_eval.py", line 809, in main
eval_main()
File "/mnt/data1/linjianqi/lerobot/src/lerobot/configs/parser.py", line 233, in wrapper_inner
response = fn(cfg, *args, **kwargs)
File "/mnt/data1/linjianqi/lerobot/src/lerobot/scripts/lerobot_eval.py", line 528, in eval_main
policy = make_policy(
File "/mnt/data1/linjianqi/lerobot/src/lerobot/policies/factory.py", line 526, in make_policy
validate_visual_features_consistency(cfg, features)
File "/mnt/data1/linjianqi/lerobot/src/lerobot/policies/utils.py", line 249, in validate_visual_features_consistency
raise_feature_mismatch_error(provided_visuals, expected_visuals)
File "/mnt/data1/linjianqi/lerobot/src/lerobot/policies/utils.py", line 214, in raise_feature_mismatch_error
raise ValueError(
ValueError: Feature mismatch between dataset/environment and policy config.
- Missing features: ['observation.images.base_0_rgb', 'observation.images.left_wrist_0_rgb', 'observation.images.right_wrist_0_rgb']
- Extra features: ['observation.images.image', 'observation.images.image2']
Please ensure your dataset and policy use consistent feature names.
If your dataset uses different observation keys (e.g., cameras named differently), use the `--rename_map` argument, for example:
--rename_map='{"observation.images.left": "observation.images.camera1", "observation.images.top": "observation.images.camera2"}'这会显示键名不一致的问题,采用他推荐的reanem_map则可以成功运行,但是成功率是0%,需要重新训练。
训练及微调
为了实现PI05在LIBERO上的原生支持,首先需要修改模型的config,让其适配LIBERO环境中双摄像头的设置,同时修改摄像头分辨率等配置。
{
"type": "pi05",
"n_obs_steps": 1,
"input_features": {
"observation.images.base_0_rgb": {
"type": "VISUAL",
"shape": [
3,
224,
224
]
},
"observation.images.left_wrist_0_rgb": {
"type": "VISUAL",
"shape": [
3,
224,
224
]
},
"observation.images.right_wrist_0_rgb": {
"type": "VISUAL",
"shape": [
3,
224,
224
]
},
"observation.state": {
"type": "STATE",
"shape": [
32
]
}
},
"output_features": {
"action": {
"type": "ACTION",
"shape": [
32
]
}
},
"device": "mps",
"use_amp": false,
"push_to_hub": true,
"repo_id": null,
"private": null,
"tags": null,
"license": null,
"paligemma_variant": "gemma_2b",
"action_expert_variant": "gemma_300m",
"dtype": "float32",
"chunk_size": 50,
"n_action_steps": 50,
"max_action_dim": 32,
"max_state_dim": 32,
"num_inference_steps": 10,
"time_sampling_beta_alpha": 1.5,
"time_sampling_beta_beta": 1.0,
"min_period": 0.004,
"max_period": 4.0,
"image_resolution": [
224,
224
],
"gradient_checkpointing": false,
"compile_model": false,
"compile_mode": "max-autotune",
"optimizer_lr": 2.5e-05,
"optimizer_betas": [
0.9,
0.95
],
"optimizer_eps": 1e-08,
"optimizer_weight_decay": 0.01,
"optimizer_grad_clip_norm": 1.0,
"scheduler_warmup_steps": 1000,
"scheduler_decay_steps": 30000,
"scheduler_decay_lr": 2.5e-06,
"tokenizer_max_length": 200
}{
"type": "pi05",
"n_obs_steps": 1,
"input_features": {
"observation.images.image": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.images.image2": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.state": {
"type": "STATE",
"shape": [
8
]
}
},
"output_features": {
"action": {
"type": "ACTION",
"shape": [
7
]
}
},
"empty_cameras": 1,
"device": "mps",
"use_amp": false,
"push_to_hub": true,
"repo_id": null,
"private": null,
"tags": null,
"license": null,
"paligemma_variant": "gemma_2b",
"action_expert_variant": "gemma_300m",
"dtype": "float32",
"chunk_size": 50,
"n_action_steps": 10,
"max_action_dim": 32,
"max_state_dim": 32,
"num_inference_steps": 10,
"time_sampling_beta_alpha": 1.5,
"time_sampling_beta_beta": 1.0,
"min_period": 0.004,
"max_period": 4.0,
"image_resolution": [
224,
224
],
"gradient_checkpointing": false,
"compile_model": false,
"compile_mode": "max-autotune",
"optimizer_lr": 2.5e-05,
"optimizer_betas": [
0.9,
0.95
],
"optimizer_eps": 1e-08,
"optimizer_weight_decay": 0.01,
"optimizer_grad_clip_norm": 1.0,
"scheduler_warmup_steps": 1000,
"scheduler_decay_steps": 30000,
"scheduler_decay_lr": 2.5e-06,
"tokenizer_max_length": 200
}上下两个分别是pi05_base和pi05_libero_finetuned两个版本的config文件,可以发现除了输入的视频键值、分辨率不一样,以及有一个"empty_cameras": 1和输入输出的动作维度不一样。
可以直接在train_config中修改这些不同:
{
"dataset": {
"repo_id": "HuggingFaceVLA/libero",
"root": null,
"episodes": null,
"image_transforms": {
"enable": false,
"max_num_transforms": 3,
"random_order": false,
"tfs": {
"brightness": {
"weight": 1.0,
"type": "ColorJitter",
"kwargs": {
"brightness": [
0.8,
1.2
]
}
},
"contrast": {
"weight": 1.0,
"type": "ColorJitter",
"kwargs": {
"contrast": [
0.8,
1.2
]
}
},
"saturation": {
"weight": 1.0,
"type": "ColorJitter",
"kwargs": {
"saturation": [
0.5,
1.5
]
}
},
"hue": {
"weight": 1.0,
"type": "ColorJitter",
"kwargs": {
"hue": [
-0.05,
0.05
]
}
},
"sharpness": {
"weight": 1.0,
"type": "SharpnessJitter",
"kwargs": {
"sharpness": [
0.5,
1.5
]
}
}
}
},
"revision": null,
"use_imagenet_stats": true,
"video_backend": "torchcodec",
"streaming": false
},
"env": null,
"policy": {
"type": "pi05",
"n_obs_steps": 1,
"input_features": {
"observation.images.image": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.images.image2": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.state": {
"type": "STATE",
"shape": [
8
]
},
"observation.images.empty_camera_0": {
"type": "VISUAL",
"shape": [
3,
224,
224
]
}
},
"output_features": {
"action": {
"type": "ACTION",
"shape": [
7
]
}
},
"device": "cuda",
"use_amp": false,
"push_to_hub": true,
"repo_id": "Jianqi-Lin/pi05_libero",
"private": null,
"tags": null,
"license": null,
"pretrained_path": "lerobot/pi05_base",
"paligemma_variant": "gemma_2b",
"action_expert_variant": "gemma_300m",
"dtype": "bfloat16",
"chunk_size": 50,
"n_action_steps": 50,
"max_state_dim": 32,
"max_action_dim": 32,
"num_inference_steps": 10,
"time_sampling_beta_alpha": 1.5,
"time_sampling_beta_beta": 1.0,
"time_sampling_scale": 0.999,
"time_sampling_offset": 0.001,
"min_period": 0.004,
"max_period": 4.0,
"image_resolution": [
224,
224
],
"empty_cameras": 1,
"tokenizer_max_length": 200,
"normalization_mapping": {
"ACTION": "MEAN_STD",
"STATE": "MEAN_STD",
"VISUAL": "IDENTITY"
},
"gradient_checkpointing": true,
"compile_model": true,
"compile_mode": "max-autotune",
"optimizer_lr": 2.5e-05,
"optimizer_betas": [
0.9,
0.95
],
"optimizer_eps": 1e-08,
"optimizer_weight_decay": 0.01,
"optimizer_grad_clip_norm": 1.0,
"scheduler_warmup_steps": 1000,
"scheduler_decay_steps": 6000,
"scheduler_decay_lr": 2.5e-06
},
"output_dir": "/mnt/data1/linjianqi/lerobot/outputs/pi05_libero",
"job_name": "pi05_multi_newest_8_gpu_30_9",
"resume": false,
"seed": 1000,
"num_workers": 4,
"batch_size": 16,
"steps": 6000,
"eval_freq": 20000,
"log_freq": 200,
"save_checkpoint": true,
"save_freq": 2000,
"use_policy_training_preset": true,
"optimizer": {
"type": "adamw",
"lr": 0.0002,
"weight_decay": 0.01,
"grad_clip_norm": 1.0,
"betas": [
0.9,
0.95
],
"eps": 1e-08
},
"scheduler": {
"type": "cosine_decay_with_warmup",
"num_warmup_steps": 8000,
"num_decay_steps": 48000,
"peak_lr": 2.5e-05,
"decay_lr": 2.5e-06
},
"eval": {
"n_episodes": 50,
"batch_size": 50,
"use_async_envs": false
},
"wandb": {
"enable": true,
"disable_artifact": false,
"project": "lerobot",
"entity": null,
"notes": null,
"run_id": "rzfptgzx",
"mode": null
}
}首先看policy部分的配置:
"policy": {
"type": "pi05",
"n_obs_steps": 1,
"input_features": {
"observation.images.image": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.images.image2": {
"type": "VISUAL",
"shape": [
3,
256,
256
]
},
"observation.state": {
"type": "STATE",
"shape": [
8
]
},
"observation.images.empty_camera_0": {
"type": "VISUAL",
"shape": [
3,
224,
224
]
}
},
"output_features": {
"action": {
"type": "ACTION",
"shape": [
7
]
}
},
"device": "cuda",
"use_amp": false,
"push_to_hub": true,
"repo_id": "Jianqi-Lin/pi05_libero",
"private": null,
"tags": null,
"license": null,
"pretrained_path": "lerobot/pi05_base",
"paligemma_variant": "gemma_2b",
"action_expert_variant": "gemma_300m",
"dtype": "bfloat16",
"chunk_size": 50,
"n_action_steps": 50,
"max_state_dim": 32,
"max_action_dim": 32,
"num_inference_steps": 10,
"time_sampling_beta_alpha": 1.5,
"time_sampling_beta_beta": 1.0,
"time_sampling_scale": 0.999,
"time_sampling_offset": 0.001,
"min_period": 0.004,
"max_period": 4.0,
"image_resolution": [
224,
224
],
"empty_cameras": 1,
"tokenizer_max_length": 200,
"normalization_mapping": {
"ACTION": "MEAN_STD",
"STATE": "MEAN_STD",
"VISUAL": "IDENTITY"
},
"gradient_checkpointing": true,
"compile_model": true,
"compile_mode": "max-autotune",
"optimizer_lr": 2.5e-05,
"optimizer_betas": [
0.9,
0.95
],
"optimizer_eps": 1e-08,
"optimizer_weight_decay": 0.01,
"optimizer_grad_clip_norm": 1.0,
"scheduler_warmup_steps": 1000,
"scheduler_decay_steps": 6000,
"scheduler_decay_lr": 2.5e-06
},先是视频的配置和动作状态的配置以及输出维度,使得维度符合要求。同时设置了一个empty_camera,以这个名字开头会自动加上mask,防止影响推理和训练。
剩余的都是一些模型配置,其中"normalization_mapping"是给数据进行预处理的归一化方法。比如说不同的部位可能数据范围有很大的区别,比如关节角度可能是 [-π, π],夹爪可能是 [0, 1]。用归一化化为相对数据使flow matching过程更稳定。
以及dataset部分,主要就是训练集名字,以及图像增强,包含亮度抖动、对比度抖动、饱和度抖动、色调偏移、锐度抖动。这是对训练集的光照条件的随机化,减少sim to real的gap,此处是关闭的。
配置基本就是这些。
训练结果
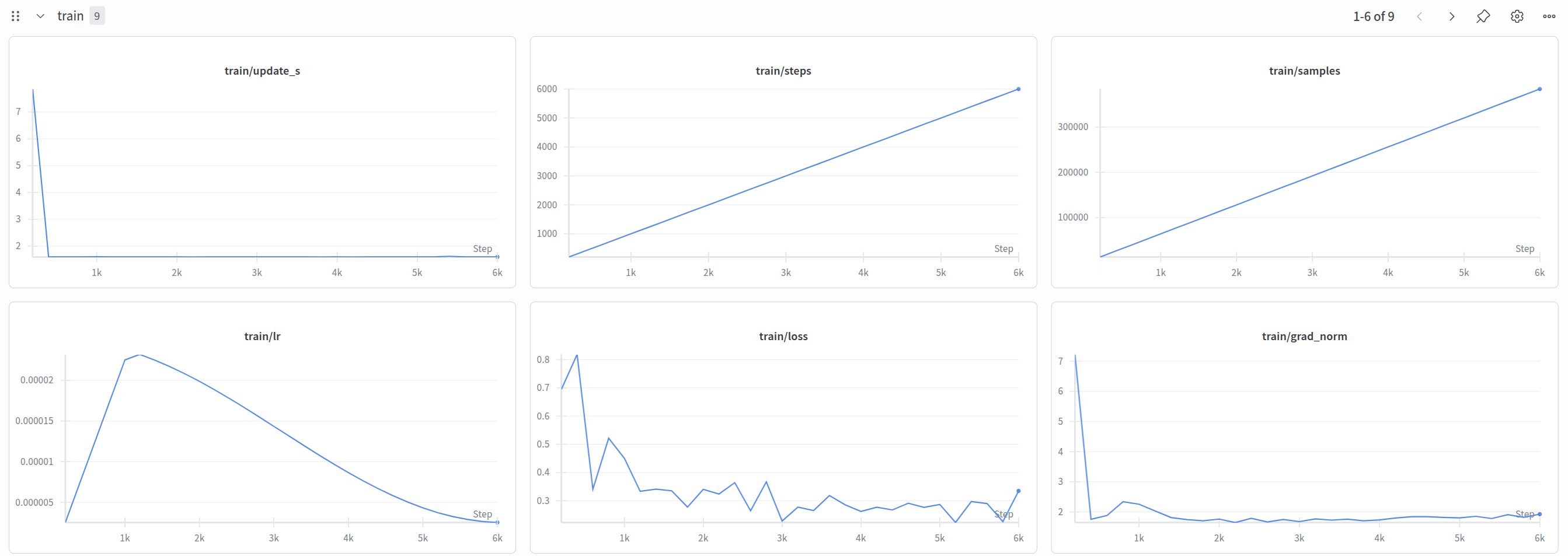
训练曲线比较健康,最后进行了6000步的时候loss是0.33461
1. 训练规模
batch_size: 16 × 2GPU = 有效 batch size 32
配合 steps: 6000,总共看到 128 × 6000 = 768,000 个样本。LIBERO 数据集不大,这意味着数据会被反复遍历多轮。Batch size 影响梯度估计的稳定性——128 对于微调来说算比较大的 batch,梯度噪声小,训练更稳定但探索性也更弱。
2. 学习率策略(最核心)
peak_lr: 2.5e-05 (微调用,比预训练小一个数量级)
decay_lr: 2.5e-06 (最终衰减到的值)
warmup: 1000 steps
decay: 6000 steps (= 总步数,全程都在衰减)
这是典型的保守微调策略:学习率很低,避免破坏预训练权重(catastrophic forgetting)。warmup 占总训练的 1/6,之后 cosine 衰减到 peak 的 1/10。
use_policy_training_preset: true 意味着用的是 policy 内部那套参数(2.5e-5),顶层 optimizer.lr: 0.0002 被忽略了。
3. Action Chunking
chunk_size: 50
n_action_steps: 50
模型一次预测 50 步未来动作,推理时也执行全部 50 步再重新观测。这是一个比较激进的设置(ACT 论文用的是 100 步但只执行部分)。chunk 越大,动作越连贯流畅,但对环境变化的响应越慢。LIBERO 是仿真且任务相对简单,所以能 hold 住大 chunk。
4. Flow Matching 去噪
num_inference_steps: 10
time_sampling_beta_alpha: 1.5
time_sampling_beta_beta: 1.0
推理 10 步去噪是速度和质量的折中(扩散模型常用 50-100 步,flow matching 效率更高)。Beta 分布 α=1.5, β=1.0 使训练时的时间步采样偏向 t 较大的区间,即更多关注去噪早期(从噪声到粗轮廓),这通常对动作质量影响最大。
5. 显存优化
gradient_checkpointing: true → 省显存,慢约20-30%
compile_model: true → torch.compile 加速
compile_mode: "max-autotune" → 最激进的编译优化
dtype: "bfloat16" → 半精度省一半显存
use_amp: false → 不用自动混合精度(因为已经全用bf16了)
这些决定了你能跑多大的 batch。如果关掉 gradient_checkpointing,batch_size 可能要减半。
6. 正则化
weight_decay: 0.01
grad_clip_norm: 1.0
都是比较标准的值。梯度裁剪 1.0 防止 flow matching 训练中偶尔出现的梯度爆炸。
7. 保存和评估策略
save_freq: 2000 → 6000步里存3个checkpoint
eval_freq: 20000 → 大于总步数,意味着训练期间不做eval
不做在线评估是因为 LIBERO 评估需要启动仿真环境跑 50 个 episode(eval.n_episodes: 50),耗时很长。作者选择训练完之后离线评估。
最后通过多GPU训练指令来加快训练
accelerate launch \
--multi_gpu \
--num_processes=2 \
$(which lerobot-train) \
--config_path=./my_train_config.json训练大概花了6个小时完成,最后在LIBERO 10上测得了53%的成功率,确实和社区的92%成功率有区别
可以看到最开始的状态并不是模型问题,而是模型不适应,需要在单臂上进行微调。
至于成功率的gap,由于我和官方都用的是LIBERO的开源数据集,数据集一样,所以应该有差别的是训练的参数。主要差别应该是
- batch size和steps的区别,官方设置的总bs和steps分别是256和30000步,而本次实验设置的bs和steps是32和6000,遍历次数不够,导致成功率有很大差异。
- 官方的学习率设置的大很多
- action horizon也是10而非50
由于老师的建议,我又再次尝试进行训练,尝试复现社区微调的92%准确度。主要从上述几个方向着手:
- 修改
batch_size和steps,让训练更加充分。让steps=36,000,batch_size=32,占用四张卡就是总batch size=128 - 修改学习率,不像微调那样那么小,把学习率放大了一倍,可以更快地收敛
- 修改了衰减步数,不会后期衰减
- 修改了
action_horizon的窗口,缩小为10,不会查看10步后的差异
按照这个训练配置训练,得到训练图:
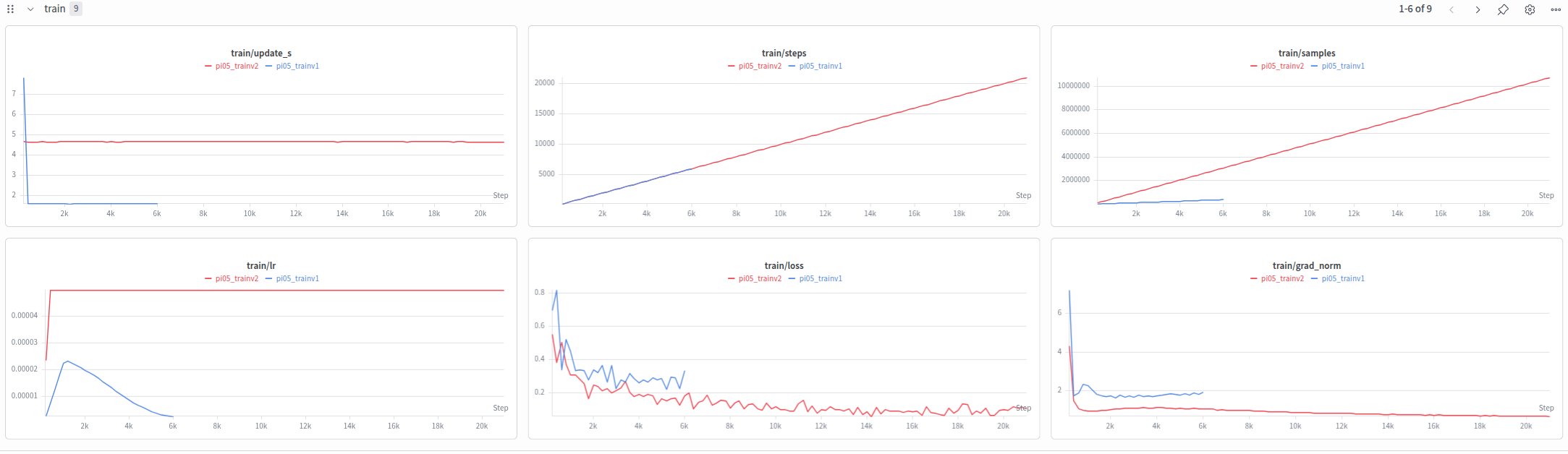 可以发现几点不同:
可以发现几点不同:
- 由于高lr,大 batch + action_horizon 缩小到 10,第二次训练比第一次下降地快速许多,到8k steps后趋于平稳,12k steps后几乎不变。由于action_horizon 从大窗口缩小到 10,意味着模型只需要预测近期动作,任务变简单了,loss 自然更低更稳。可以考虑在把
decay_steps设置为12k steps时,这样lr就会在12k steps左右开始衰减,进一步学习。 - update time由于batch size的差异和多卡的差异,v1大致为1.5秒,v2为4.6秒左右。
- train/lr 这是最直接的差异。v2 把学习率翻倍到 ~4.5e-5 并且去掉了后期衰减,所以全程恒定。v1 用了 warmup + cosine decay,峰值只有 ~2e-5,后期衰减到接近 0。v2 的策略让模型全程以较大步幅学习,收敛更快。
- train/grad_norm v2 梯度范数更小更稳定(~1),v1 前期波动大。大 batch(128)天然能平滑梯度估计,减少方差。加上恒定高 lr 让优化轨迹更稳定,不像 v1 小 lr + 小 batch 容易出现梯度尖峰。
最后进行eval,得到最后成功率是95%,比较圆满。