Note of Computer System: a Programmer’s perspective.
[!NOTE]
这个笔记是由2015年CMU15-213课程内容slides和网上相关笔记总结而成,目的是在整合各路笔记中巩固自己的知识。主要是消化为主,所以个人产出较少,由于参考了多方资料会出现中英混杂情况。由于课程slide不好整合成md格式,而小土刀的笔记又正好是slide的汉化,所以会以其博客为基底补充。
CSapp是一门很广泛的计算机体系基础课,遍及数据底层表述,汇编代码,调用逻辑,内存结构,链接,异常流控制,并行,线程,虚拟内存和缓存的Index。本课程为程序员观察底层硬件实现提供了新的视角,很好的解释了C等语言中一些特性的原因。而诸如线程,进程等内容则为以后学习OS等课程打好了基础。
主要资料:
Course theme: Abstraction Is Good But Don’t Forget Reality
Great realities from the overview of CSAPP:
- Ints are not Integers, Floats are not Reals
- You’ve Got to Know Assembly
- Memory Matters. Random Access Memory Is an Unphysical Abstraction
- There’s more to performance than asymptotic complexity
- Constant factors matter too!
- And even exact op count does not predict performance
- Easily see 10:1 performance range depending on how code written
- Must optimize at multiple levels: algorithm, data representations, procedures, and loops
- Must understand system to optimize performance
- Computers do more than execute programs
1.Bits, Bytes, and Integers
| C Data Type | Typical 32-bit | Typical 64-bit | x86-64 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| short | 2 | 2 | 2 |
| int | 4 | 4 | 4 |
| long | 4 | 8 | 8 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| long double | - | - | 10/16 |
| pointer | 4 | 8 | 8 |
Boolean Algebra
|
|
Shift Operations
-
Left Shift: x « y
-
Shift bit-vector x left y positions.
Throw away extra bits on left.
Fill with 0’s on right
-
-
Right Shift: x » y
- Logical shift
- Fill with 0’s on left
- Arithmetic shift
- Fill with the most significant bit on the left

- Logical shift
Representation: unsigned and signed
|
|
| \( X \) | B2U(X) | B2T(X) |
|---|---|---|
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | -8 |
| 1001 | 9 | -7 |
| 1010 | 10 | -6 |
| 1011 | 11 | -5 |
| 1100 | 12 | -4 |
| 1101 | 13 | -3 |
| 1110 | 14 | -2 |
| 1111 | 15 | -1 |
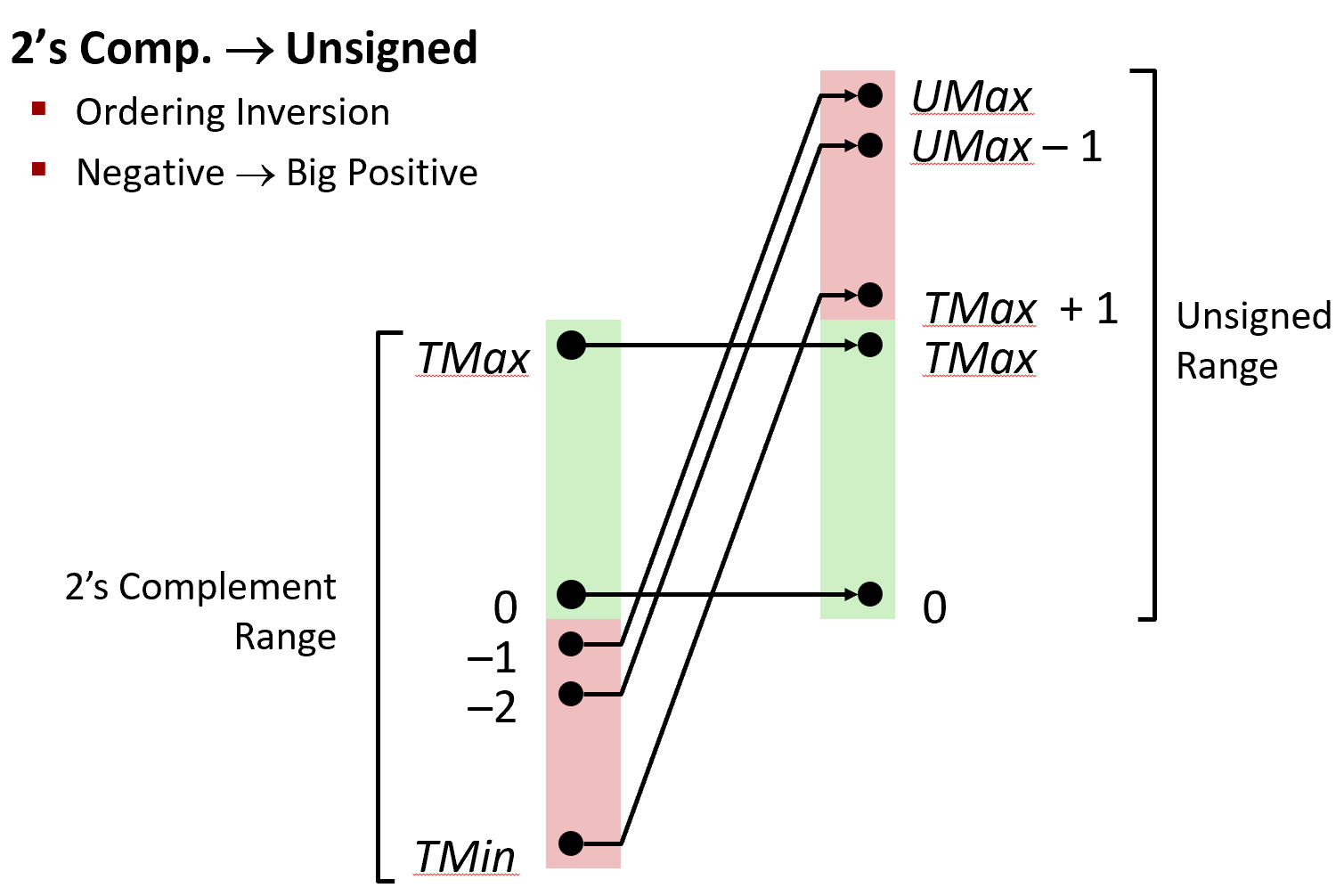
- UMin = 0 即 000…0
- UMax = $2^w−1$ 即 111…1
- TMin = $−2^w−1$ 即 100…0
- TMax = $2^{w-1}-1$ 即 011…1
- Minus 1 即 111…1
For different word size, there can be different outcome.
| w | 8 | 16 | 32 | 64 |
|---|---|---|---|---|
| UMax | 255 | 65,535 | 4,294,967,295 | 18,446,744,073,709,551,615 |
| TMax | 127 | 32,767 | 2,147,483,647 | 9,223,372,036,854,775,807 |
| TMin | -128 | -32,768 | -2,147,483,648 | -9,223,372,036,854,775,808 |
From above we can get 2 important property:
- |TMin| = TMax + 1 (范围并不是对称的)
- UMax = $2\times TMax + 1$
- Signed number and unsigned number have the same encoding for positive number.
- $U2B(x)=B2U^{−1}(x)$
- $T2B(x)=B2T^{−1}(x)$
Conversion, casting
类型扩展与截取具体需要分情况讨论,如:
- 扩展(例如从
short int到int),都可以得到预期的结果- 无符号数:加 0
- 有符号数:加符号位
- 截取(例如
unsigned到unsigned short),对于小的数字可以得到预期的结果- 无符号数:mod 操作
- 有符号数:近似 mod 操作
| decimal | hex | binary |
|---|---|---|
| x=15213 | 3B 6D | 00111011 01101101 |
| bx=15213 | 00 00 3B 6D | 00000000 00000000 00111011 01101101 |
| y=-15213 | C4 93 | 11000100 10010011 |
| iy=-15213 | FF FF C4 93 | 11111111 11111111 11000100 10010011 |

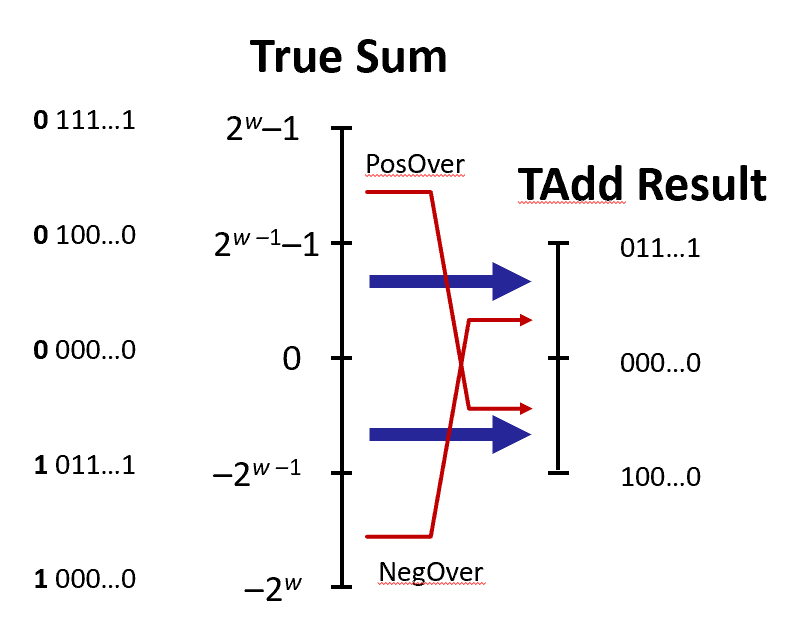
If sum $\geq$ $2^{w-1}$, the result becomes negative, and if sum $\leq \, -2^{w-1}$, the result becomes positive, both at most once.
Shift
Operation:
- u « k gives $u \times 2^k$ for both signed and unsigned
- u » k gives ⌊ u / 2^k ⌋ by using logical shift for unsigned, arithmetic shift by signed.
Byte Ordering Example
- Big Endian: The most significant byte is on the right. Used in IA32, x86
- Little Endian: The most significant byte is on the left. Used in Sun.
2.Float
Float can be represented by a universal formula:
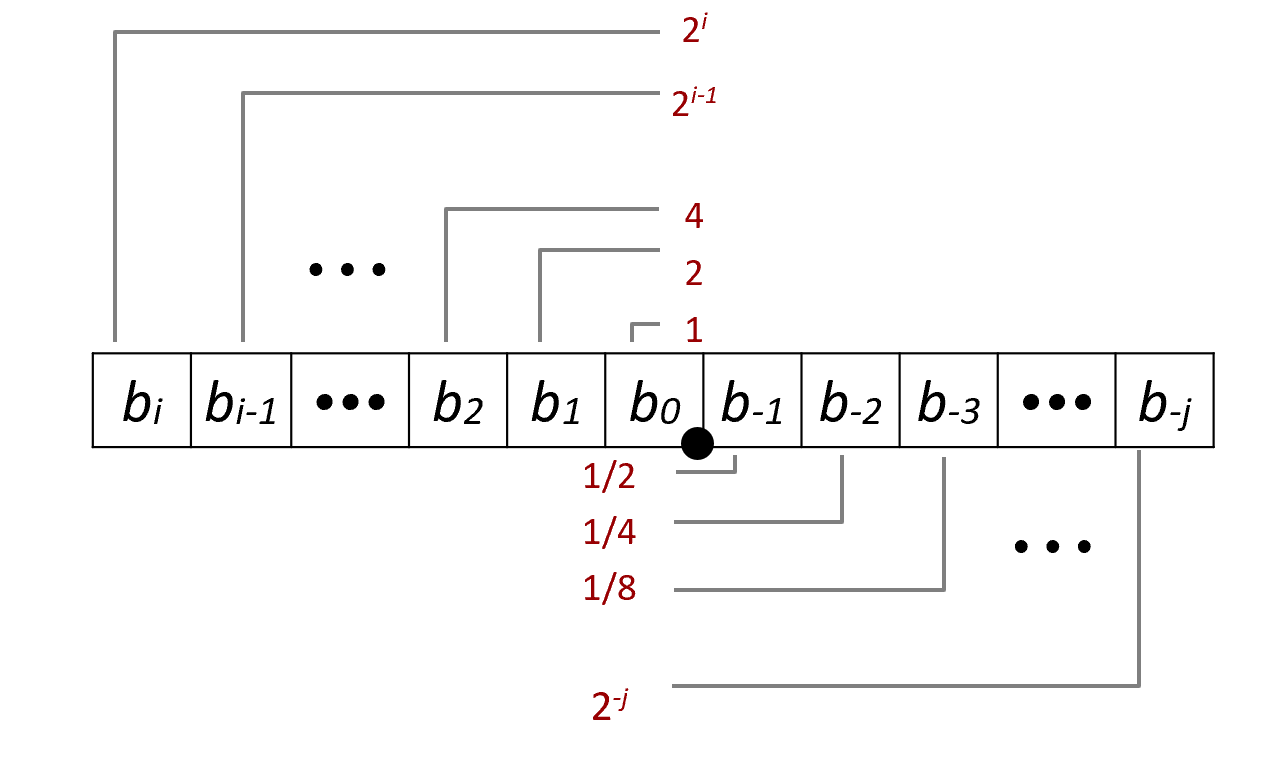 $$
∑_{k=−j}^ib_k×2^k
$$
For instance:
$$
5\,\frac34=101.11_2,\quad2\,\frac78=10.111_2,\quad1\frac7{16}=1.0111_2
$$
$$
∑_{k=−j}^ib_k×2^k
$$
For instance:
$$
5\,\frac34=101.11_2,\quad2\,\frac78=10.111_2,\quad1\frac7{16}=1.0111_2
$$
IEEE floating point
Normalized value:
$$ v=(−1)^sM\times2^E $$The E here is exp with bias: $E = Exp - Bias$, where
-
$Exp$: is the unsigned value encoded by $exp$.
-
$Bias$: with the value of $2^{k-1}-1$, where $k$ is the bits number of $exp$ encodes.
- $float$: 127(Exp: 1…254, E:-126…127)
- $double$: 1023 (Exp:1…2046, E:-1022…1023)
The $Exp$ is encoded this way to ensure it can be compared conveniently.
-
for normalized float, the M part only encode the decimal part following 1.
 $$
152131.0=11101101101101_2=1.1101101101101_2×2^{13}\\
Exp = E + Bias = 13 + 127 = 140 = 10001100_2
$$
$$
152131.0=11101101101101_2=1.1101101101101_2×2^{13}\\
Exp = E + Bias = 13 + 127 = 140 = 10001100_2
$$
|
|
Denormalized Values
When the $exp$ is 0…000, the value is denormalized,
Exponent value: E = 1 – Bias (instead of E = 0 – Bias) to make
Significant coded with implied leading 0: M = $0.xxx…x_2$
- xxx…x: bits of frac
Cases
-
exp = 000…0, frac = 000…0
-
Represents zero value
-
Note distinct values: +0 and –0
- because sign bit can denote positive/negative value
-
-
exp = 000…0, frac ≠ 000…0
- Numbers closest to 0.0
- Equispaced
Special Value
Condition: $exp$ = 111…1.
Case: $exp$ = 111…1, $frac$ = 000…0.
- Represent +$\infty$
- Operation that overflows
- Both positive and negative
Case: $exp$ = 111…1, $frac \ne$ 000…0
- Not-a-number(NaN)
- Represents case when no numeric value can be determined
- E.g. $\sqrt{-1}, \infty-\infty,\infty \times 0$

|
|
Rounding, addition, multiplication
Rounding
对于浮点数的加法和乘法来说,我们可以先计算出准确值,然后转换到合适的精度。在这个过程中,既可能会溢出,也可能需要舍入来满足 frac 的精度。
在二进制中,我们舍入到最近的偶数,即如果出现在中间的情况,舍入之后最右边的值要是偶数,对于十进制数,例子如下:
|
|
对于二进制数也是类似的
|
|
舍入至最近的偶数是因为防止大量舍入都四舍五入导致数值整体偏大,向偶数舍入可平均舍入影响。
$$ (–1)^{s1} M_1 2^{E1} + (-1)^{s2} M_2 2^{E2} $$-
Exact Result: $(–1)^s M 2^E$
-
Sign s, significand M:
- Result of signed align & add
-
Exponent E: E1
-
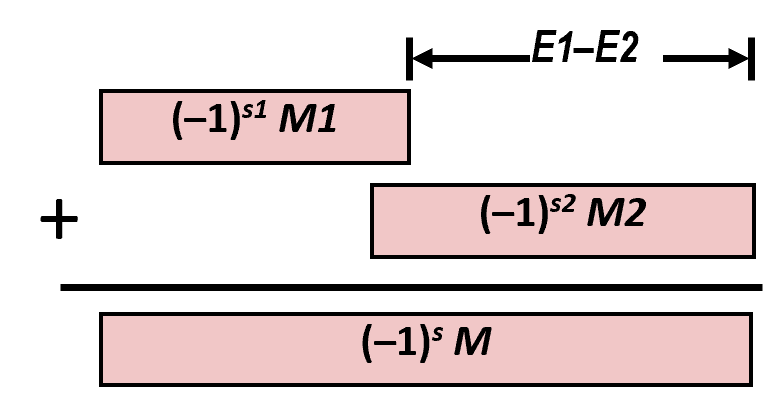
-
Fixing
-
If M ≥ 2, shift M right, increment E
-
if M < 1, shift M left k positions, decrement E by k
-
Overflow if E out of range
-
Round M to fit frac precision
-
基本性质
- 相加可能产生 infinity 或者 NaN
- 满足交换率
- 不满足结合律(因为舍入会造成精度损失,如
(3.14+1e10)-1e10=0,但3.14+(1e10-1e10)=3.14) - 加上 0 等于原来的数
- 除了 infinity 和 NaN,每个元素都有对应的倒数
- 除了 infinity 和 NaN,满足单调性,即 a≥b→a+c≥b+c
结果是 $(−1)^sM^{2E}$,其中 $s=s_1∧s_2,M=M_1×M_2,E=E_1+E_2$
- 如果 M 大于等于 2,那么把 M 右移,并增加 E 的值。
- 如果 E 超出了可以表示的范围,溢出
- 把 M 舍入到 frac 的精度
基本性质
- 相乘可能产生 infinity 或者 NaN
- 满足交换率
- 不满足结合律(因为舍入会造成精度损失)
- 乘以 1 等于原来的数
- 不满足分配率
1e20*(1e20-1e20)=0.0但1e20*1e20-1e20*1e20=NaN - 除了 infinity 和 NaN,满足单调性,即 a≥b→a×c≥a×b
3.Machine code
Code Forms:
- Machine Code: The byte-level programs that a processor executes
- Assembly Code: A text representation of machine code
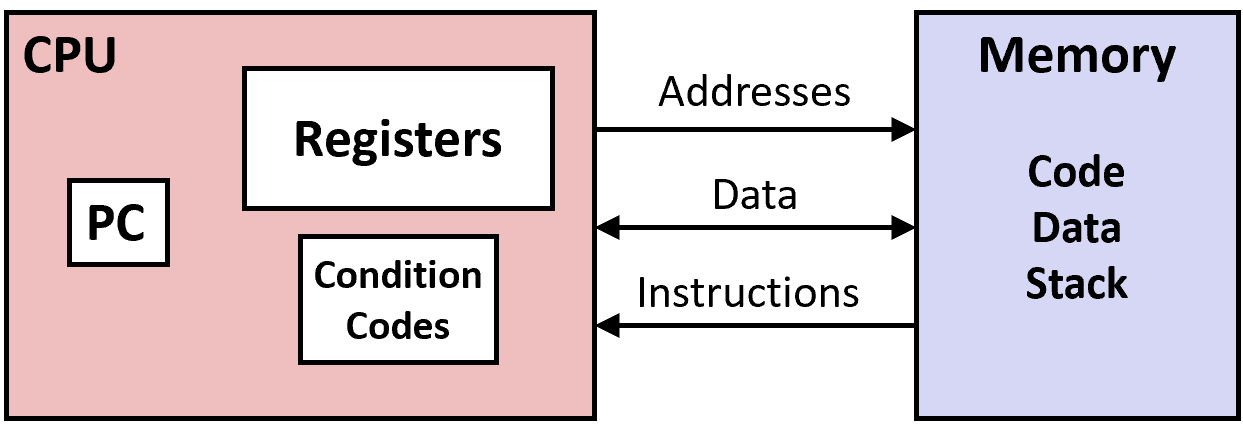
Programmer-Visible State
-
PC: Program counter
-
Address of next instruction
-
Called “RIP” (x86-64)
-
-
Register file
- Heavily used program data
-
Condition codes
-
Store status information about most recent arithmetic or logical operation
-
Used for conditional branching
-
-
Memory
-
Byte addressable array
-
Code and user data
-
Stack to support procedures
-
|
|
|
|
汇编入门(Basic)
前面我们简要了解了一下程序执行的基本过程,也对汇编有了一点点认识,这一节我们从寄存器的相关知识讲起,介绍汇编的基本知识。这部分内容虽然在实际编程中几乎用不到,但是对于后面内容的理解非常重要。
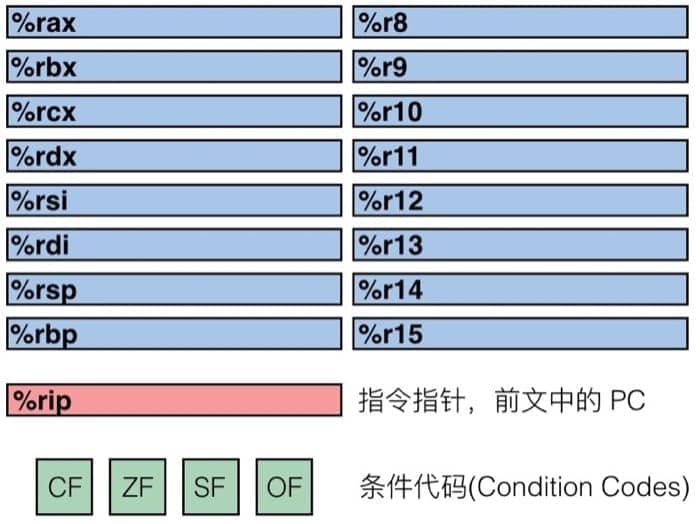
x86-64 架构中的整型寄存器如下图所示(暂时不考虑浮点数的部分)

仔细看看寄存器的分布,我们可以发现有不同的颜色以及不同的寄存器名称,黄色部分是 16 位寄存器,也就是 16 位处理器 8086 的设计,然后绿色部分是 32 位寄存器(这里我是按照比例画的),给 32 位处理器使用,而蓝色部分是为 64 位处理器设计的。这样的设计保证了令人震惊的向下兼容性,几十年前的 x86 代码现在仍然可以运行!
当填入寄存器时,填充32位会重置前32位为0,但是填充更低位数不会改变高阶位数。
前六个寄存器(%rax, %rbx, %rcx, %rdx, %rsi, %rdi)称为通用寄存器(General Purpose Registers, GPRs),通常用于存储数据、指针或函数参数。除了专门的用途之外,它们也可以作为临时存储空间来处理计算任务。x86-64 架构的通用寄存器包括:
-
%rax:累加寄存器
- 主要用于算术运算、返回值存储以及一些特定指令的操作。
- 返回值:调用一个函数时,%rax 通常存储返回值。
- 例如,
mov %rax, %rdi表示将 %rax 寄存器的值移动到 %rdi。
-
%rbx:基址寄存器
- 主要用于存储基地址(在基址寻址模式下),也是函数调用约定中保存的寄存器。
- 在有些操作系统中,%rbx 是一个"被保护的"寄存器,意味着它在函数调用中不会被修改。
-
%rcx:计数寄存器
- 常用于循环计数、位移操作等。
- 在某些指令(如
rep指令)中,%rcx 作为计数器。 - 例如,
mov %rcx, %rax将 %rcx 的值传递给 %rax。
-
%rdx:数据寄存器
- 主要用于乘法、除法等操作。
- 在乘法或除法指令中,%rdx 通常会与 %rax 配合使用(例如,除法时,商存储在 %rax,余数存储在 %rdx)。
-
%rsi:源索引寄存器
- 通常用于存储源数据的地址。
- 在字符串操作(如
movs,stos)或内存复制操作中,%rsi 常作为源操作数寄存器。
-
%rdi:目标索引寄存器
- 通常用于存储目标数据的地址。
- 在函数调用中,%rdi 存储传递给函数的第一个参数。
-
%rsp:栈指针寄存器
- 用于指示栈的顶部。栈是用来存储局部变量、函数返回地址等的内存区域。
- 每当数据被推送到栈上时,%rsp 的值会减少;弹出数据时,%rsp 的值会增加。
-
%rbp:基指针寄存器
- 用于函数调用时存储栈帧的基址,尤其在访问函数参数和局部变量时,它提供一个固定的基地址。
- %rbp 常用作函数调用时栈帧的基指针。
-
%r8 到 %r15:扩展的通用寄存器
- x86-64 架构提供了额外的 8 个 64 位通用寄存器(%r8 到 %r15),用于处理更多的参数传递、临时数据存储等任务。

而 %rsp(%esp) 和 %rbp(%ebp) 则是作为栈指针和基指针来使用的。下面我们通过 movq 这个指令来了解操作数的三种基本类型:立即数(Imm,e.g.$0x4)、寄存器值(Reg)和内存值(Mem)。
对于 movq 指令来说,需要源操作数和目标操作数,源操作数可以是立即数、寄存器值或内存值的任意一种,但目标操作数只能是寄存器值或内存值。指令的具体格式可以这样写 movq [Imm|Reg|Mem], [Reg|Mem],第一个是源操作数,第二个是目标操作数,例如:
movq Imm, Reg->mov $0x5, %rax->temp = 0x5;movq Imm, Mem->mov $0x5, (%rax)->*p = 0x5;movq Reg, Reg->mov %rax, %rdx->temp2 = temp1;movq Reg, Mem->mov %rax, (%rdx)->*p = temp;movq Mem, Reg->mov (%rax), %rdx->temp = *p;
这里有一种情况是不存在的,没有 movq Mem, Mem 这个方式,也就是说,我们没有办法用一条指令完成内存间的数据交换。
上面的例子中有些操作数是带括号的,括号的意思就是寻址,这也分两种情况:
- 普通模式,(R),相当于
Mem[Reg[R]],也就是说寄存器 R 指定内存地址,类似于 C 语言中的指针,语法为:movq (%rcx), %rax也就是说以 %rcx 寄存器中存储的地址去内存里找对应的数据,存到寄存器 %rax 中 - 移位模式,D(R),相当于
Mem[Reg[R]+D],寄存器 R 给出起始的内存地址,然后 D 是偏移量,语法为:movq 8(%rbp),%rdx也就是说以 %rbp 寄存器中存储的地址再加上 8 个偏移量去内存里找对应的数据,存到寄存器 %rdx 中
因为寻址这个内容比较重要,所以多说两句,不然之后接触指针会比较吃力。对于寻址来说,比较通用的格式是 D(Rb, Ri, S) -> Mem[Reg[Rb]+S*Reg[Ri]+D],其中:
D- 常数偏移量Rb- 基寄存器Ri- 索引寄存器,不能是 %rspS- 系数
除此之外,还有如下三种特殊情况
(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]]D(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]+D](Rb, Ri, S)->Mem[Reg[Rb]+S*Reg[Ri]]
我们通过具体的例子来巩固一下,这里假设 %rdx 中的存着 0xf000,%rcx 中存着 0x0100,那么
0x8(%rdx)=0xf000+0x8=0xf008(%rdx, %rcx)=0xf000+0x100=0xf100(%rdx, %rcx, 4)=0xf000+4*0x100=0xf4000x80(, %rdx, 2)=2*0xf000+0x80=0x1e080(, %edx, 2)=(0, %rdx, 2)=0 + 2*0xf000
了解了寻址之后,我们来看看运算指令,这里以 leaq 指令为例子。具体格式为 leaq Src, Dst,其中 Src 是地址的表达式,然后把计算的值存入 Dst 指定的寄存器,也就是说,因为leaq只计算内存地址并不访问它,所以leaq可以将普通数字当作内存计算,类似于 p = &x[i];,也可以计算x + k*y的代数形式。我们来看一个具体的例子,假设一个 C 函数是:
|
|
对应的汇编代码为:
|
|
可以看到是直接对 %rdi 寄存器中存的数据(地址)进行运算,然后赋值给 %rax。最后给出一些常见的算术运算指令,注意参数的顺序,而且对于有符号和无符号数都是一样的,更多的信息可以参考 Intel 官方文档。
需要两个操作数的指令
addq Src, Dest->Dest = Dest + Srcsubq Src, Dest->Dest = Dest - Srcimulq Src, Dest->Dest = Dest * Srcsalq Src, Dest->Dest = Dest << Srcsarq Src, Dest->Dest = Dest >> Srcshrq Src, Dest->Dest = Dest >> Srcxorq Src, Dest->Dest = Dest ^ Srcandq Src, Dest->Dest = Dest & Srcorq Src, Dest->Dest = Dest | Src
需要一个操作数的指令
incq Dest->Dest = Dest + 1decq Dest->Dest = Dest - 1negq Dest->Dest = -Destnotq Dest->Dest = ~Dest
The meaning of different suffixs
-
b(byte):-
Refers to 8-bit operands (1 byte).
-
Example:
addb,subb,movb. -
The
bsuffix indicates that the instruction is operating on 8-bit values.
-
-
w(word):-
Refers to 16-bit operands (2 bytes).
-
Example:
addw,subw,movw. -
The
wsuffix is used when dealing with 16-bit data.
-
-
l(long):-
Refers to 32-bit operands (4 bytes).
-
Example:
addl,subl,movl. -
The
lsuffix is used for 32-bit values (long integers).
-
-
q(quad):-
Refers to 64-bit operands (8 bytes).
-
Example:
addq,subq,movq. -
The
qsuffix is used for 64-bit values (quad-word integers).
-
-
t(ten):-
Sometimes used in 128-bit instructions, like with
movapsfor SIMD operations (Single Instruction, Multiple Data). -
Example:
movapsoraddps, wherepsstands for packed single-precision floating-point operations on 128-bit vectors.
-
流程控制(Control)
我们先来回顾一下 x86-64 处理器中不同的寄存器,这一部分很重要,务必要弄明白
首先要理解的是,寄存器中存储着当前正在执行的程序的相关信息:
- 临时数据存放在 (%rax, …)
- 运行时栈的地址存储在 (%rsp) 中
- 目前的代码控制点存储在 (%rip, …) 中
- 目前测试的状态放在 CF, ZF, SF, OF 中
条件代码(Condition codes)
最后的四个标识位(CF, ZF, SF, OF)就是用来辅助程序的流程控制的,他们基于最近的算术或逻辑操作结果意思是:
- CF: Carry Flag (针对无符号数)
- ZF: Zero Flag
- SF: Sign Flag (针对有符号数)
- OF: Overflow Flag (针对有符号数)
可以看到以上这四个标识位,表示四种不同的状态,举个例子,假如我们有一条诸如 t = a + b 的语句,汇编之后假设用的是 addq Src, Dest,那么根据这个操作结果的不同,会相应设置上面提到的四个标识位,而因为这个是执行类似操作时顺带尽心设置的,称为隐式设置(Implicit Setting),例如:
-
如果两个数相加,在最高位还需要进位(也就是溢出了),那么 CF 标识位就会被设置(unsigned overflow)
-
如果 t 等于 0,那么 ZF 标识位会被设置
-
如果 t 小于 0,那么 SF 标识位会被设置(as signed)
-
如果 2’s complement(signed) 溢出,那么 OF 标识位会被设置为 1
(溢出的情况是
(a>0 && b > 0 && t <0) || (a<0 && b<0 && t>=0))
这就发现了,其实这四个条件代码,是用来标记上一条命令的结果的各种可能的,是自动会进行设置的。注意,使用 leaq 指令的话不会进行设置。
除了隐形设置,还可以进行显式设置(Explicit Setting),具体的方法是使用 cmpq 指令,这里的 q 指的是 64 位的地址。具体来说 cmpq Src2(b), Src1(a) 等同于计算 a-b(注意 a b 顺序是颠倒的),然后利用 a-b 的结果来对应进行条件代码的设置:
-
如果在最高位还需要进位(也就是溢出了),那么 CF 标识位就会被设置(unsigned)
-
a 和 b 相等时,也就是
a-b等于零时,ZF 标识位会被设置 -
如果 a < b,也就是
(a-b)<0时,那么 SF 标识位会被设置(as signed) -
如果 2’s complement(signed) 溢出,那么 OF 标识位会被设置
(溢出的情况是
(a>0 && b > 0 && t <0) || (a<0 && b<0 && t>=0))
另一种进行显式设置的方法是使用 testq 指令,具体来说 testq Src2(b), Src1(a) 等同于计算 a&b并且没有输出地址(注意 a b 顺序是颠倒的),然后利用 a-b 的结果来对应进行条件代码的设置,通常来说会把其中一个操作数作为 mask:
- 当
a&b == 0时,ZF 标识位会被设置 - 当
a&b < 0时,SF 标识位会被设置
有了这四个条件码,就可以通过不同的组合方式,来产生不同的条件判断。
|
|
|
|
| Register | Use(s) |
|---|---|
| %rdi | Argument x |
| %rsi | Argument y |
| %rax | Return value |
条件分支(Conditional Branches)
介绍完了条件代码,就可以来看看具体的跳转了,跳转实际上就是根据条件代码的不同来进行不同的操作。我们先来看一个比较原始的例子(编译器没有进行优化):
|
|
对应的汇编代码如下,这里 %rdi 中保存了参数 x,%rsi 中保存了参数 y,而 %rax 一般用来存储返回值:
|
|
这里我们是要给出两个数的绝对值的差,所以需要判断谁大谁小。考虑到汇编不算特别直观,这里我们用 goto 语句重写一次,基本上就和汇编出来的代码逻辑类似了,方便之后的讲解:
|
|
我们再看另一种条件语句要如何翻译,比如 val = Test ? Then_Expr : Else_Expr;,重写上面的函数就是:val = x>y ? x-y : y-x;
转换成 goto 形式就是:
|
|
但是实际上汇编出来的代码,并不是这样的,会采用另一种方法来加速分支语句的执行。现在我们先来说一说,为什么分支语句会对性能造成很大的影响。
我们知道现在的 CPU 都是依靠流水线工作的,比方说执行一系列操作需要 ABCDE 五个步骤,那么在执行 A 的时候,实际上执行 B 所需的数据会在执行 A 的同时加载到寄存器中,这样运算器执行外 A,就可以立刻执行 B 而无须等待数据载入。如果程序一直是顺序的,那么这个过程就可以一直进行下去,效率会很高。但是一旦遇到分支,那么可能执行完 A 下一步要执行的是 C,但是载入的数据是 B,这时候就要把流水线清空(因为后面载入的东西都错了),然后重新载入 C 所需要的数据,这就带来了很大的性能影响。为此人们常常用『分支预测』这一技术来解决(分支预测是另一个话题这里不展开),但是对于这类只需要判断一次的条件语句来说,其实有更好的方法。
处理器有一条指令支持 if(Test) Dest <- Src 的操作,也就是说可以不用跳转,利用条件代码来进行赋值,于是编译器在可能的时候会把上面的 goto 程序改成如下:
|
|
具体的做法是:反正一共就两个分支,我都算出行不行,然后利用上面的条件指令来进行赋值,这样就完美避免了因为分支可能带来的性能问题(需要清空流水线),像下面这样,同样 %rdi 中保存了参数 x,%rsi 中保存了参数 y,而 %rax 一般用来存储返回值:
|
|
这个方法好是好,但是也有一些情况并不适用于:
- Expensive Computation: 因为会把两个分支的运算都提前算出来,如果这两个值都需要大量计算的话,就得不偿失了,所以需要分支中的计算尽量简单。
- Risky Computations: 另外在涉及指针操作的时候,如
val = p ? *p : 0;,因为两个分支都会被计算,所以可能导致奇怪问题出现 - Computations with side effects: 最后一种就是如果分支中的计算是有副作用的,那么就不能这样弄
val = x > 0 ? x*= 7 : x+= 3;,这种情况下,因为都计算了,那么 x 的值肯定就不是我们想要的了。
循环(Loop)
先来看看并不那么常用的 Do-While 语句以及对应使用 goto 语句进行跳转的版本:
|
|
这个函数计算参数 x 中有多少位是 1,翻译成汇编如下:
|
|
其中 %rdi 中存储的是参数 x,%rax 存储的是返回值。换成更通用的形式如下:
|
|
而对于 While 语句的转换,存在两种形式,对于第一种形式会直接跳到中间,如:
|
|
如果在编译器中开启 -O1 优化,那么会把 While 先翻译成 Do-While,然后再转换成对应的 Goto 版本,因为 Do-While 语句执行起来更快,更符合 CPU 的运算模型。
接着来看看最常用的 For 循环,也可以一步一步转换成 While 的形式,如下
|
|
Switch 语句
最后我们来看看最复杂的 switch 语句,这种类型的语句一次判断会有多种可能的跳转路径(知道 CPU 的分支预测会多抓狂吗)。这里用一个具体的例子来进行讲解:
|
|
这个例子中包含了大部分比较特殊的情况:
- 共享的条件:5 和 6
- fall through:2 也会执行 3 的部分(这个要小心,一般来说不这么搞,如果确定要用,务必写上注释)
- 缺失的条件:4
具体怎么办呢?简单来说,使用跳转表(jtab)(你会发现表的解决方式在很多地方都有用:虚函数,继承甚至动态规划),可能会类似如下汇编代码,这里 %rdi 是参数 x,%rsi 是参数 y,%rdx 是参数 z, %rax 是返回值
|
|
跳转表为
|
|
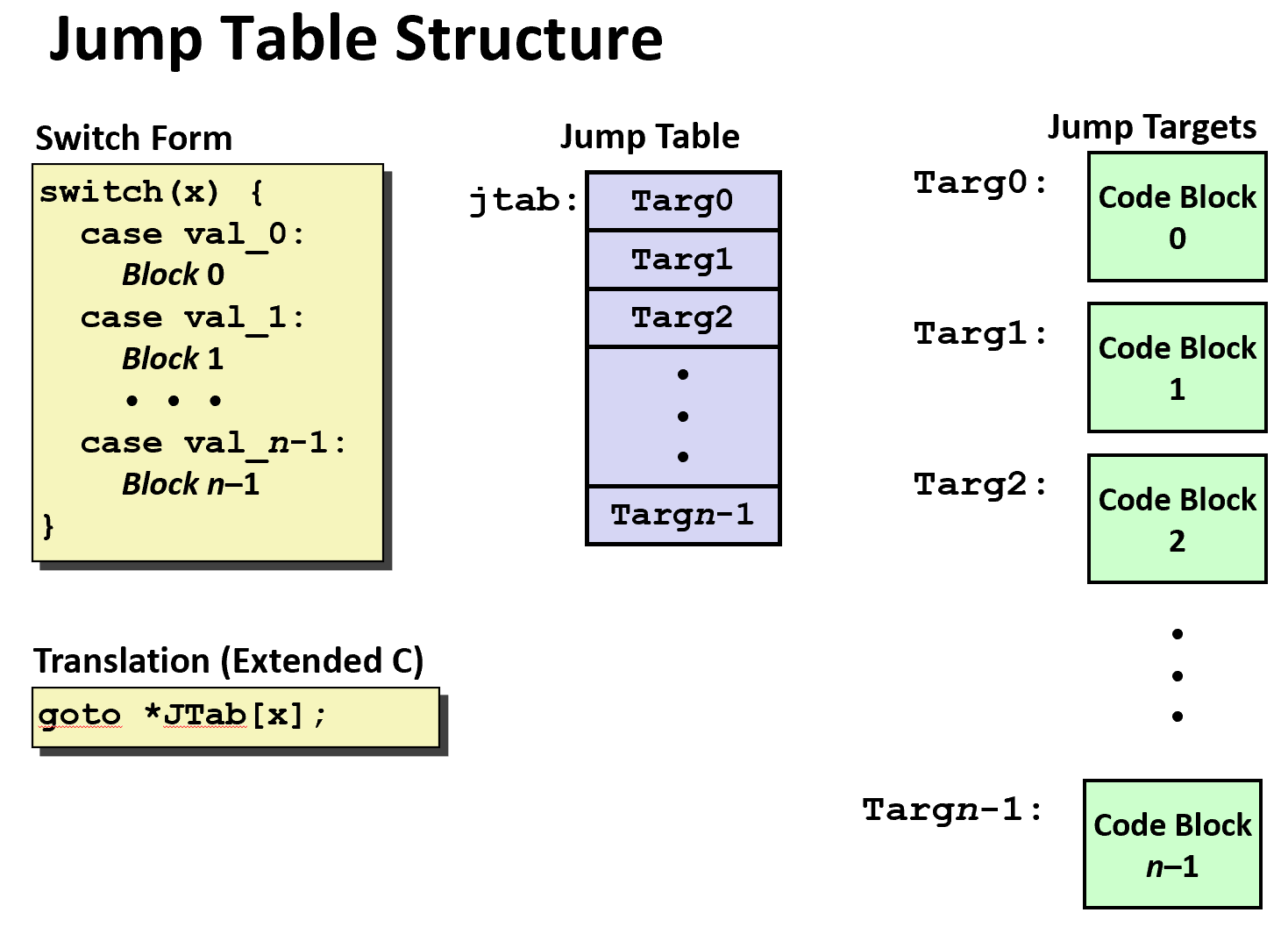
这里需要注意,我们先跟 6 进行比较(因为 6 是最大的),然后利用 ja 指令进行跳转,为什么,因为如果是负数的话,ja 是处理无符号数的,所以负数情况肯定大于 6,于是直接利用 ja 跳转到 default 的分支。
如果存在负数整型,编译器会将整体加上一个偏移值,使之可以只与最大值比较便跳转default。若差值过大则变为决策树。
然后下一句 jmp *.L4(,%rdi, 8) # goto *JTab[x],是一个间接跳转,通过看上面的跳转列表来进行跳转。
比如说,直接跳转 jmp .L8,就直接跳到 .L8 所在的标签,也就是 x = 0
如果是 jmp *.L4(,%rdi,8) 那么就先找到 .L4 然后往后找 8 个字节(或 8 的倍数),于是就是 0~6 的范围。
通过上面的例子,我们可以大概了解处理 switch 语句的方式:大的 switch 语句会用跳转表,具体跳转时可能会用到决策树(if-elseif-elseif-else)
过程调用(Procedures)
上一节中我们学习了机器是如何利用跳转实现流程控制的,这一节我们来看一个更加复杂的机制:过程调用(也就是调用函数)具体在 CPU 和内存中是怎么实现的。理解之后,对于递归会有更加清晰的认识。
在过程调用中主要涉及三个重要的方面:
- 传递控制:包括如何开始执行过程代码,以及如何返回到开始的地方
- 传递数据:包括过程需要的参数以及过程的返回值
- 内存管理:如何在过程执行的时候分配内存,以及在返回之后释放内存
以上这三点,都是凭借机器指令实现的
栈结构(Stack Structure)
在 x86-64 中,所谓的栈,实际上一块内存区域,这个区域的数据进出满足先进后出的原则。所以栈向低内存地址部分增长,是一个上下颠倒的结构,寄存器%rsp保存着最低位的栈顶地址。
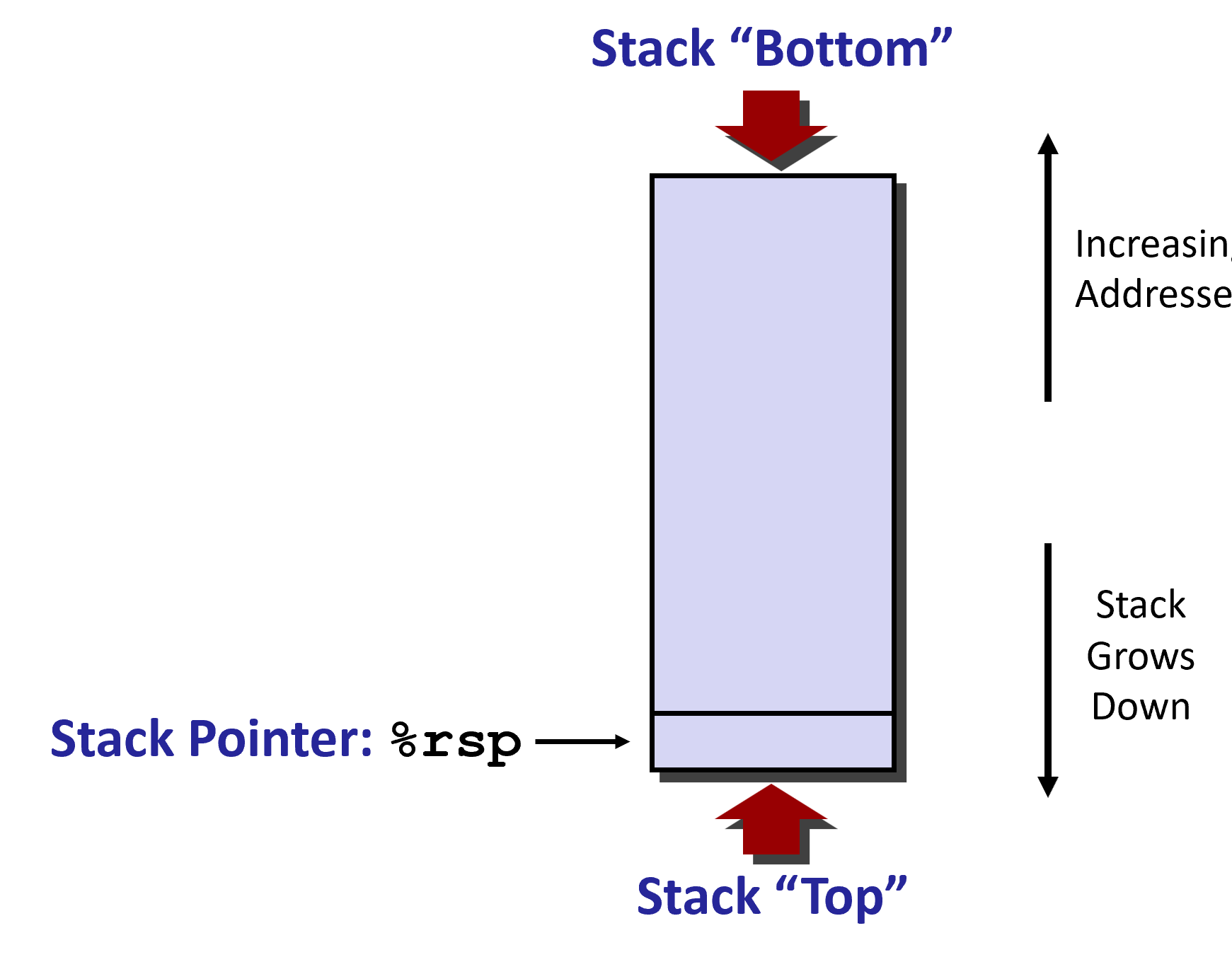
我们假设一开始 %rsp 为红色,对于 push 操作,对应的是 pushq Src 指令,具体会完成下面三个步骤:
- 从地址
Src中取出操作数 - 把 %rsp 中的地址减去 8(也就是到下一个位置)
- 把操作数写入到 %rsp 的新地址中
这个时候 %rsp 就对应下8位。
重来一次,假设一开始 %rsp 为红色,对于 pop 操作,对应的是 popq Dest 指令,具体会完成下面三个步骤:
- 从 %rsp 中存储的地址中读入数据
- 把 %rsp 中的地址增加 8(回到上一个位置)
- 把刚才取出来的值放到
Dest中(这里必须是一个寄存器)
这时候 %rsp 就对应上8位。
调用方式(Calling Conventions)
如果在一段函数中要调用另一个函数用于赋值,栈可用于保存原函数中的变量值。
-
Use stack to support procedure call and return
-
Procedure call: call label
-
Push return address on stack
-
Jump to label
-
-
Return address:
-
Address of the next instruction right after call
-
Example from disassembly
-
-
Procedure return: ret
-
Pop address from stack
-
Jump to address
-
-
|
|
对应的汇编代码为:
|
|
可以看到,过程调用是利用栈来进行的,通过 call label 来进行调用(先把返回地址入栈,然后跳转到对应的 label),返回的地址,将是下一条指令的地址,通过 ret 来进行返回(把地址从栈中弹出,然后跳转到对应地址)
我们『单步调试』来看看具体调用的过程
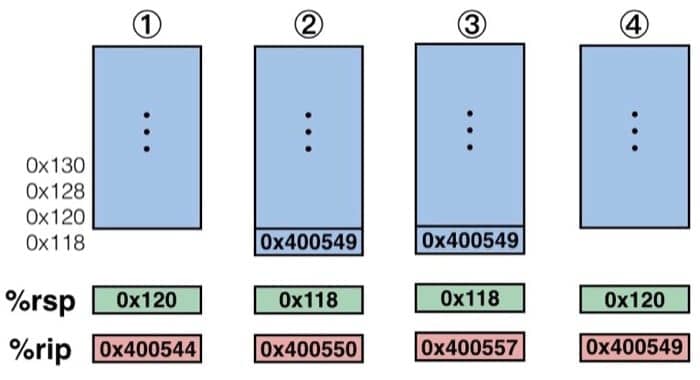
- 在执行到 400544 那一行的时候 %rsp 指向栈顶(存储着栈顶的地址),%rip 指向当前要执行的指令(也就是 400544)
- 在上一步操作完成之后,因为跳转的关系,%rip 指向 mult2 函数开始的地方(也就是 400550),之前的压栈操作也使得栈顶改变(返回值的位置),于是 %rsp 对应进行改变
- 接着执行到了
retq那句,这个时候要做的就是从栈中取出栈顶位置(这样就可以从跳转处继续了),然后对寄存器做对应的修改 - 最后恢复到原来的 multstore 函数中继续执行
Passing data
我们可以发现,函数调用中会利用 %rax 来保存过程调用的返回值,以便程序继续运行的。这就是基本的过程调用的控制流程。
那么过程调用的参数会放在哪里呢?如果参数没有超过六个,那么会放在:%rdi, %rsi, %rdx, %rcx, %r8, %r9 中。如果超过了,会另外放在一个栈中。而返回值会放在 %rax 中。栈只会在需要的时候释放空间。
Managing Local data
-
Languages that support recursion
-
e.g., C, Pascal, Java
-
Code must be [“Reentrant(可重入)”](recursion - What exactly is a reentrant function? - Stack Overflow)
- Multiple simultaneous instantiations of single procedure
-
Need some place to store state of each instantiation
-
Arguments
-
Local variables
-
Return pointer
-
-
-
Stack discipline
-
State for given procedure needed for limited time
- From when called to when return
-
Callee returns before caller does
-
-
Stack allocated in Frames
- state for single procedure instantiation(实例)
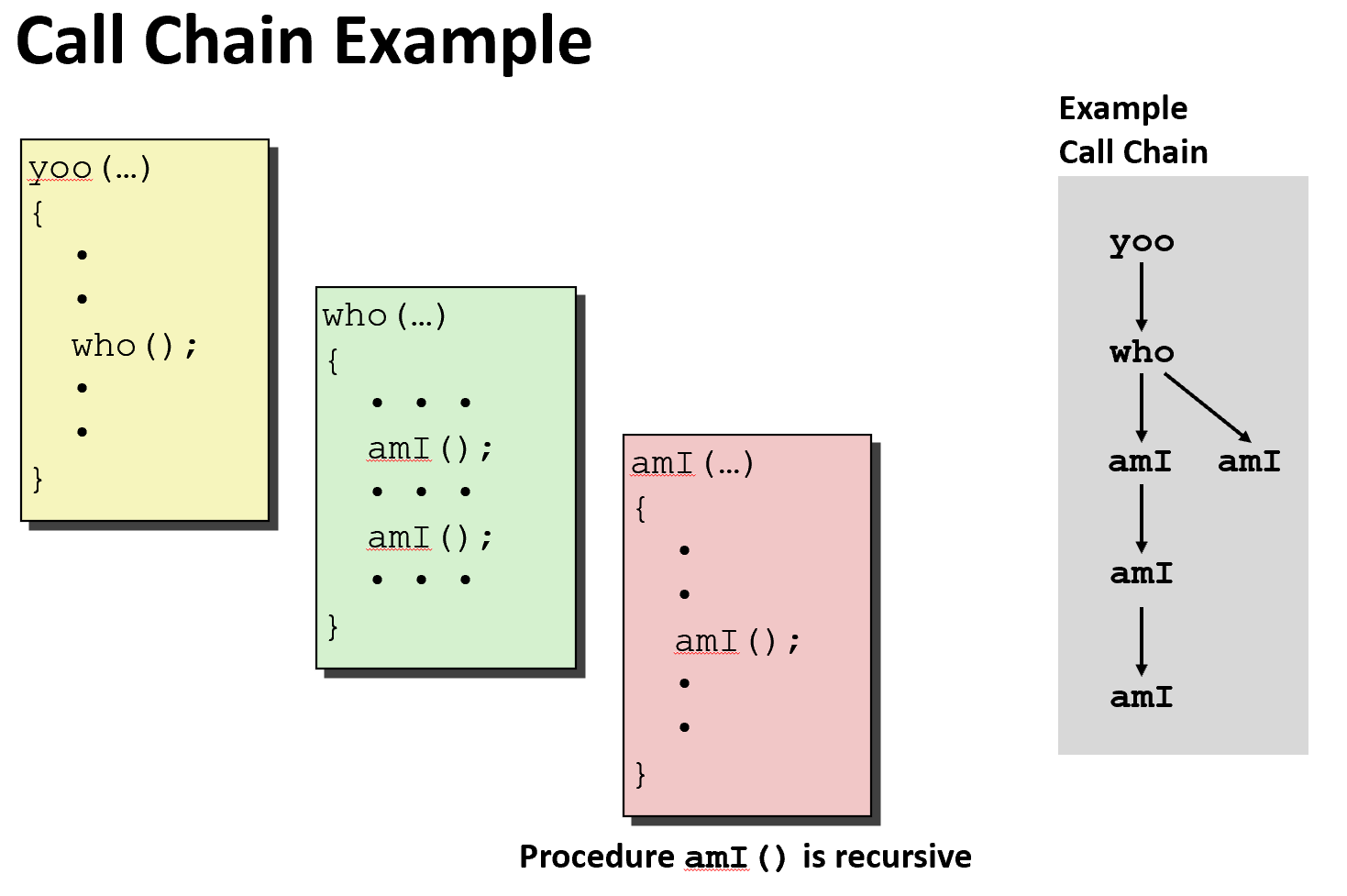
既然是利用栈来进行函数调用,自然而然就可以推广到递归的情况,而对于每个过程调用来说,都会在栈中分配一个帧 Frames。每一个Stack Frame需要
- 返回信息
- 本地存储(如果需要)
- 临时空间(如果需要)
Management
-
Space allocated when enter procedure
-
“Set-up” code
-
Includes push by call instruction
-
-
Deallocated when return
-
“Finish” code
-
Includes pop by ret instruction
-
整一帧会在过程调用的时候进行空间分配,然后在返回时进行回收,在 x86-64/Linux 中,栈帧的结构是固定的,当前的要执行的栈中包括:
- Argument Build: 需要使用的参数
- 如果不能保存在寄存器中,会把一些本地变量放在这里
- 已保存的寄存器上下文
- 老的栈帧的指针(%rbp)(可选)
而调用者的栈帧则包括:
- 返回地址(因为
call指令被压入栈的) - 调用所需的参数
具体如下图所示:
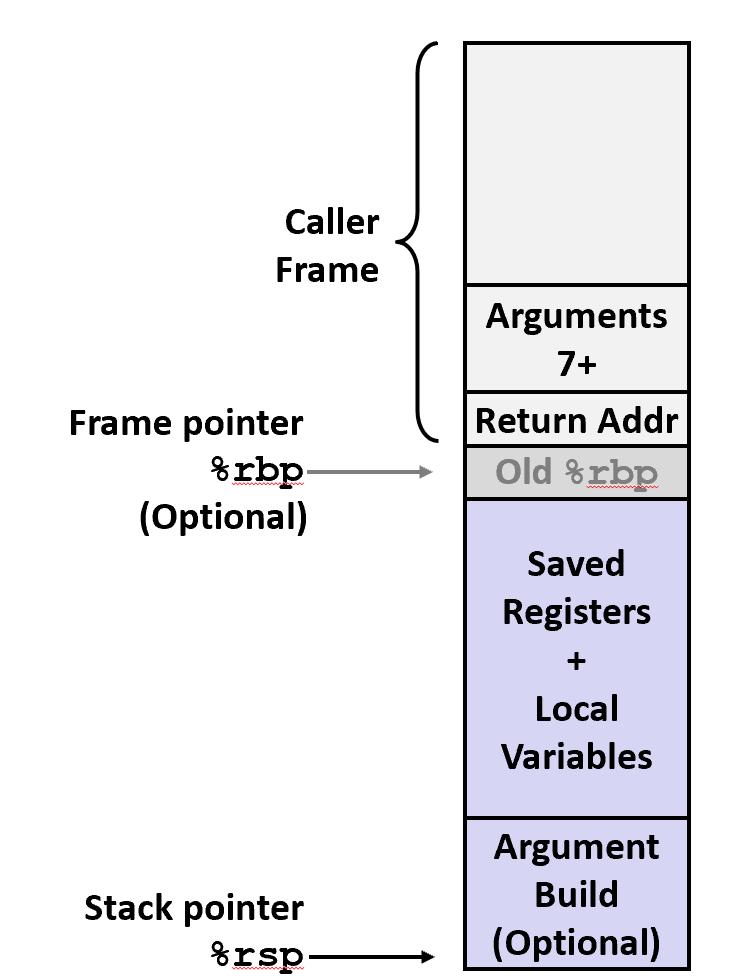
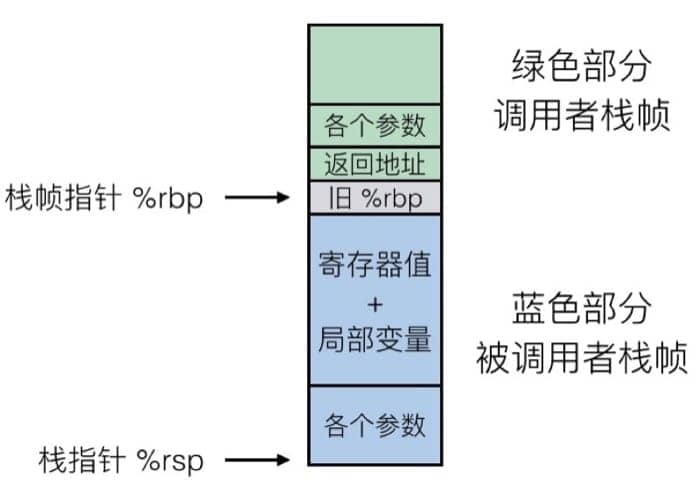
Caller-Callee: Register used for tempoary storage
|
|
yoo is the caller, who is the callee
- Contents of register
%rdxoverwritten bywho- “Caller Saved”
- Caller saves temporary values in its frame before the call
- Caller-saved registers are used to hold temporary quantities that need not be preserved across calls.
- It is the caller’s responsibility to push these registers onto the stack or copy them somewhere else if it wants to restore this value after a procedure call.
- “Callee Saved”
- Callee-saved registers are used to hold long-lived values that should be preserved across calls.
- Callee restores them before returning to caller
- When the caller makes a procedure call, it can expect that those registers will hold the same value after the callee returns, making it the responsibility of the callee to save them and restore them before returning to the caller. Or to not touch them.
- Wrapping up, If the caller wants to ensure that a value in a caller-saved register is preserved across a function call, it can either push it to the stack or save the value in the callee register.
- “Caller Saved”
To be specific.
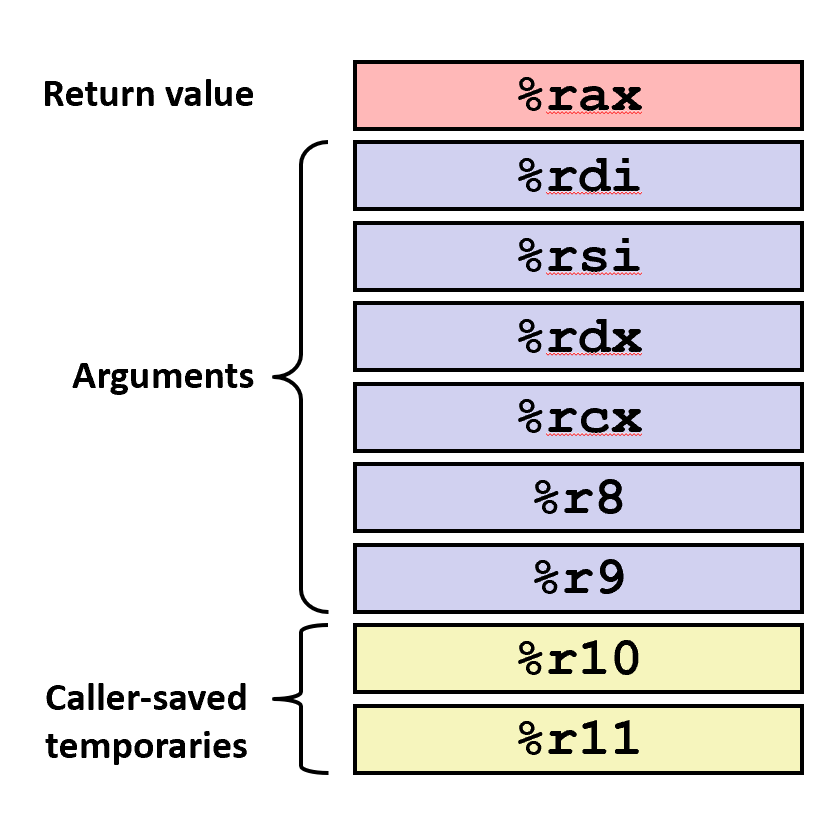
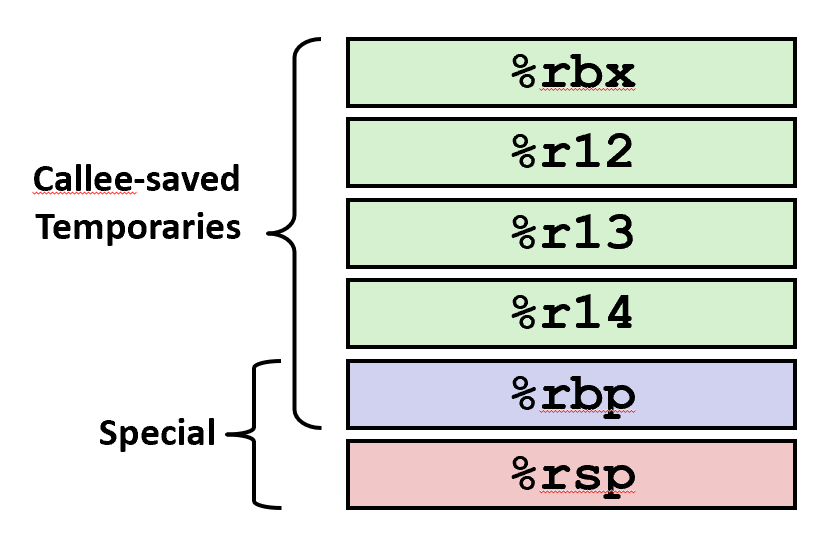
-
%rax
-
Return value
-
Also caller-saved
-
Can be modified by procedure
-
-
%rdi, …, %r9
-
Arguments
-
Also caller-saved
-
Can be modified by procedure
-
-
%r10, r11
-
Caller-saved
-
Can be modified by procedure
-
-
%rbx, %r12, %r13, %r14
-
Callee-saved
-
Callee must save & restore
-
-
%rbp
-
Callee-saved
-
Callee must save & restore
-
May be used as frame pointer
-
Can mix & match
-
-
%rsp
-
Special form of callee save
-
Restored to original value upon exit from procedure
-
递归(Illustration of Recursion)
有了前面的的基础,要理解递归就简单很多了,直接上例子
|
|
对应的汇编代码为:
|
|
实际执行的过程中,会不停进行压栈,直到最后返回,所以递归本身就是一个隐式的栈实现,但是系统一般对于栈的深度有限制(每次一都需要保存当前栈帧的各种数据),所以一般来说会把递归转换成显式栈来进行处理以防溢出。
寄存器保存策略也保证了不同过程不会影响相互的数据。递归调用函数本身和调用其他函数没有本质区别。
数据存储(Data)
上一节我们了解了过程调用是如何用机器代码实现的,这一节我们来看看基本的数据是如何存储在计算机中。
第一讲中我们已经学到,不同的数据类型所需要的字节数是不同的,我们先来回顾一下这个表格:
| 数据类型 | 32 位 | 64 位 | x86-64 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| short | 2 | 2 | 2 |
| int | 4 | 4 | 4 |
| long | 4 | 8 | 8 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| long double | - | - | 10/16 |
| 指针 | 4 | 8 | 8 |
我们举几个具体的例子就一目了然了:
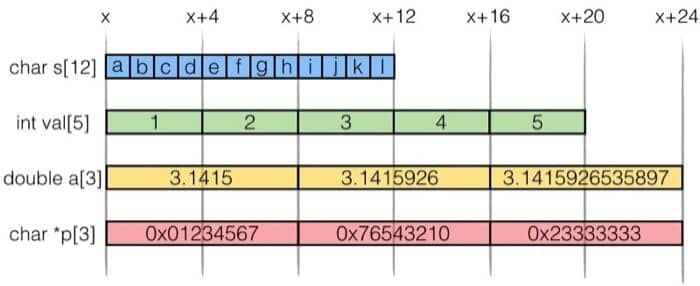
既然是连续的地址空间,就有很多不同的访问方式,比方对于 int val[5] 来说
| 引用方式 | 类型 | 值 |
|---|---|---|
val[4] |
int |
5 |
val |
int * |
x |
val+1 |
int * |
x+4 |
&val[2] |
int * |
x+8 |
val[5] |
int |
?? 越界 |
*(val+1) |
int |
2 |
val+i |
int * |
x + 4i |
Array Loop Example
|
|
|
|
多维数组(Multidimensional (Nested) Arrays)
对于多维的数组,基本形式是 T A[R][C],R 是行,C 是列,如果类型 T 占 K 个字节的话,那么数组所需要的内存是 R*C*K 字节。具体在内存里的排列方式如下:
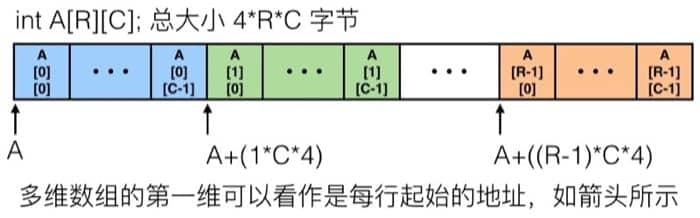
具体访问的方式如下:
|
|
对应的汇编代码为,这里假设 C = 5
|
|
还有另外一种组合数组的方式,不是连续分配,而是存储每个数组的起始地址。与之前连续分配唯一不同之处在于计算元素位置时候不同行对应不连续的起始地址(可能分散在内存的不同部分)。这两种方式在 C 语言中看起来差不多,但对应的汇编代码则完全不同。
-
Array Elements
-
A[i][j] is element of type T, which requires K bytes, long C a row.
-
Address A + i * (C * K) + j * K = A + (i * C + j)** K*
-
结构体(Structures)
结构体是 C 语言中非常常用的一种机制,具体在内存中是如何存放的呢?我们通过具体的例子来进行学习。比如我们有这样一个结构体:
|
|
那么在内存中的排列是

如果我们换一下结构体元素的排列顺序,可能就会出现和我们预想不一样的结果,比如
|
|
因为需要对齐的缘故,所以具体的排列是这样的:
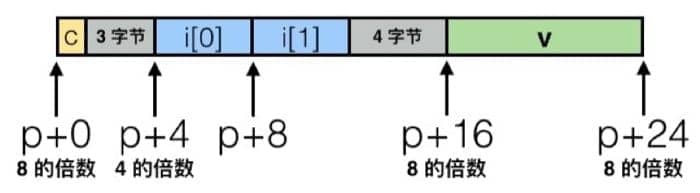
具体对齐的原则是,对于结构体前部的数据,只需要与下一个类型对齐,及在下一个数据字节数的倍数处写入数据。而对于最后一个数据,只需要保证结构体全长是结构体中最大的数据类型的字节数的倍数即可。
为什么要这样呢,因为内存访问通常来说是 4 或者 8 个字节位单位的,不对齐的话访问起来效率不高。具体来看的话,是这样:
- 1 字节:char, …
- 没有地址的限制
- 2 字节:short, …
- 地址最低的 1 比特必须是
0
- 地址最低的 1 比特必须是
- 4 字节:int, float, …
- 地址最低的 2 比特必须是
00
- 地址最低的 2 比特必须是
- 8 字节:double, long, char *, …
- 地址最低的 3 比特必须是
000
- 地址最低的 3 比特必须是
- 16 字节:long double (GCC on Linux)
- 地址最低的 4 比特必须是
0000
- 地址最低的 4 比特必须是
对于一个结构体来说,所占据的内存空间必须是最大的类型所需字节的倍数,所以可能需要占据更多的空间,比如:
|
|

根据这种特点,在设计结构体的时候可以采用一些技巧。例如,要把大的数据类型放到前面,加入我们有两个结构体:
|
|
对应的排列是:

这样我们就通过不同的排列,节约了 4 个字节空间,如果这个结构体要被复制很多次,这也是很可观的内存优化。
Advanced Topics
内存分布&缓冲区溢出(Memory Layout&Buffer Overflow)
这一节是机器代码的最后一部分,主要说说由缓冲区溢出引起的攻防大战。我们先来看看程序在内存中是如何组织的(x86-64 Linux)
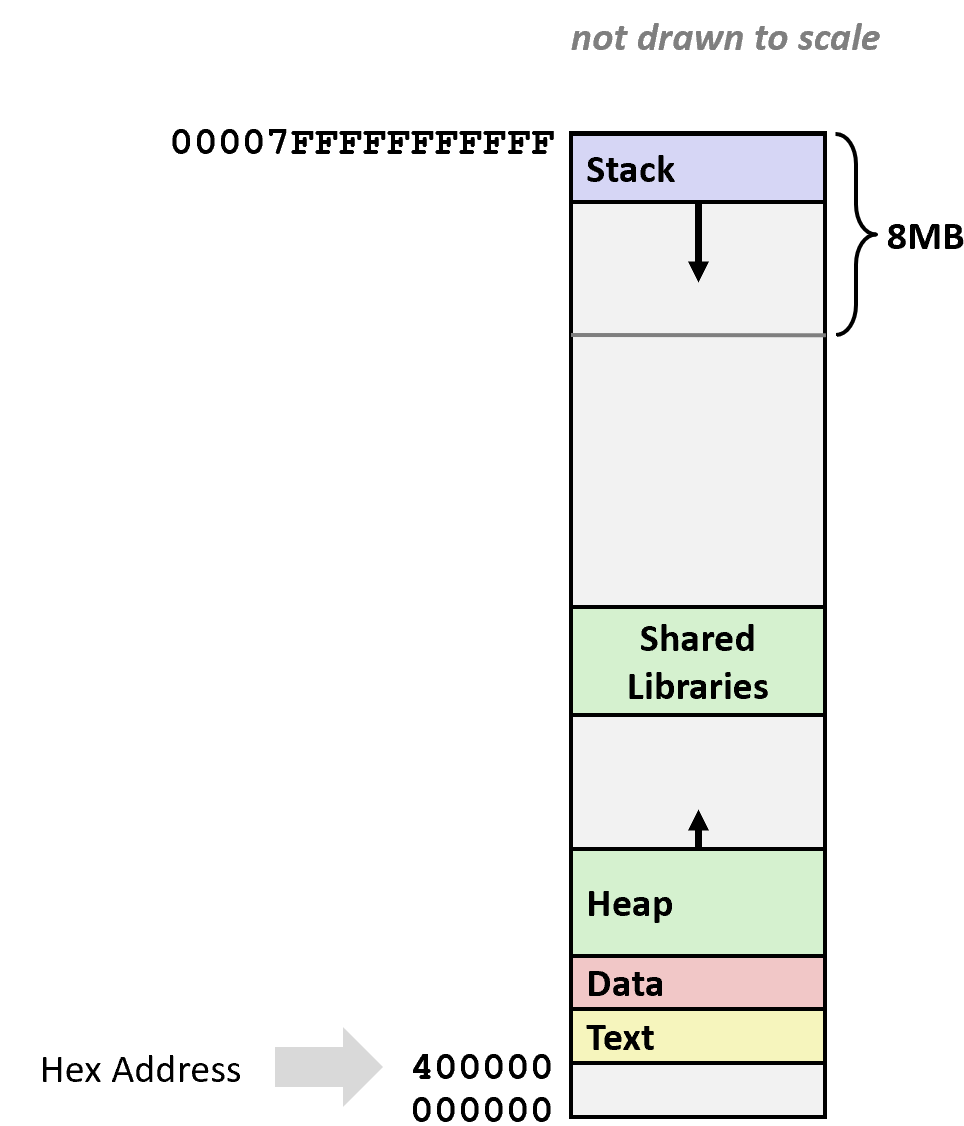
最上面是运行时栈,有 8MB 的大小限制,一般用来保存局部变量。然后是堆,动态的内存分配会在这里处理,例如 malloc(), calloc(), new() 等。然后是数据,指的是静态分配的数据,比如说全局变量,静态变量,常量字符串。最后是共享库等可执行的机器指令,这一部分是只读的。
可以见到,栈在最上面,也就是说,栈再往上就是另一个程序的内存范围了,这种时候我们就可以通过这种方式修改内存的其他部分了。
举个例子
|
|
不同的 i 可能的执行结果是:
fun(0)-> 3.14fun(1)-> 3.14fun(2)-> 3.1399998664856fun(3)-> 2.00000061035156fun(4)-> 3.14fun(6)-> Segmentation fault
之所以会产生这种错误,是因为访问内存的时候跨过了数组本身的界限修改了 d 的值。你没看错,这是个大问题!如果不检查输入字符串的长度,就很容易出现这种问题,尤其是针对在栈上有界限的字符数组。
在 Unix 中,gets() 函数的实现是这样的:
|
|
可以看到并没有去检测最多能读入多少字符(于是很容易出问题),类似的情况还在 strcpy, strcat, scanf, fscanf, sscanf 中出现。比如说
|
|
我们来测试一下这个函数,可能的结果是:
|
|
为什么明明在 echo() 中声明 buf 为 4 个 char,居然一开始输入这么多都没问题?我们到汇编代码里去看看:
|
|
我们看 4006cf 这一行,可以发现实际上给 %rsp 分配了 0x18 的空间,所以可以容纳不止 4 个 char。
在调用 gets 函数之前(第 4006d6 行),内存中栈帧示意图为:
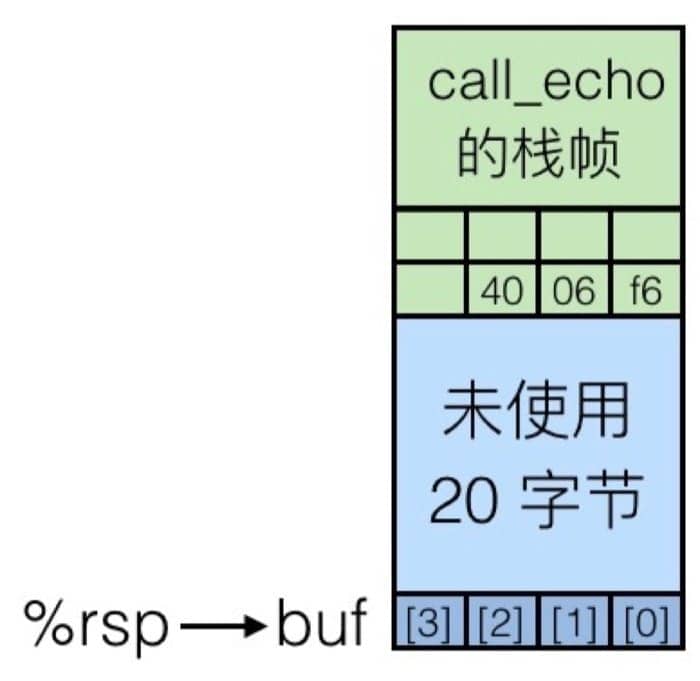
结合上面代码可以看到,call_echo 栈帧中保存着调用之前执行指令的地址 4006f6,用于返回之后继续执行。我们输入字符串 01234567890123456789012 之后,栈帧中缓冲区被填充,如下:
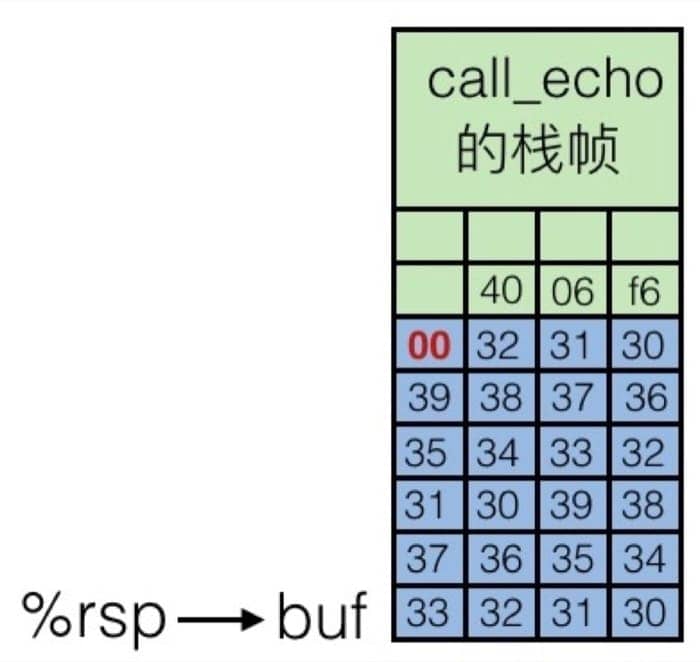
虽然缓冲区溢出了,但是并没有损害当前的状态,程序还是可以继续运行(也就是没有出现段错误),但是如果再多一点的话,也就是输入 0123456789012345678901234,内存中的情况是这样的:
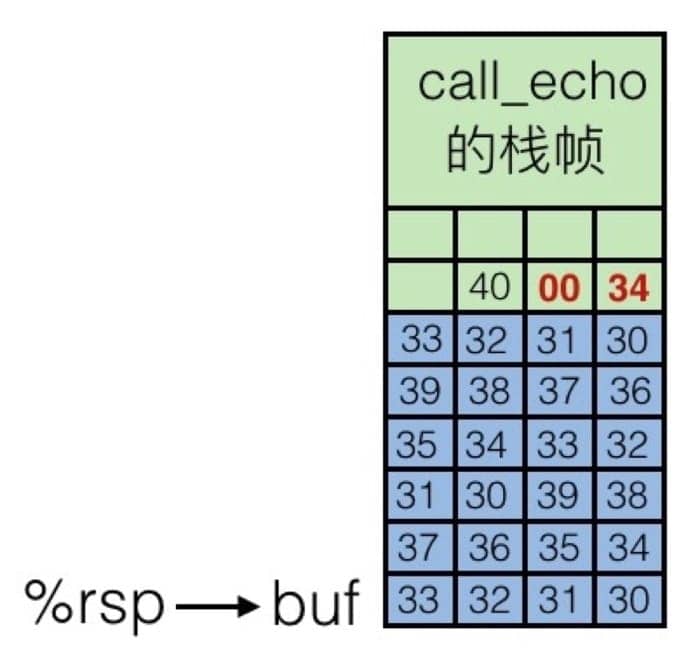
就把返回地址给覆盖掉了,当 echo 执行完成要回到 call_echo 函数时,就跳转到 0x400034 这个内容未知的地址中了。也就是说,通过缓冲区溢出,我们可以在程序返回时跳转到任何我们想要跳转到的地方!攻击者可以利用这种方式来执行恶意代码!
那么我们现在来看看,怎么处理缓冲区溢出攻击,有几种方式:
- 好好写代码,尽量不让缓冲区异常
|
|
-
fgets instead of gets
-
strncpy instead of strcpy
-
Don’t use scanf with %s conversion specification
-
Use fgets to read the string
-
Or use %ns where n is a suitable integer
-
-
程序容易出问题,那么提供系统层级的保护
-
In traditional x86, can mark region of memory as either “read-only” or “writeable”
- Can execute anything readable
-
X86-64 added explicit “execute” permission
-
Stack marked as non-executable
-
-
编译器也可以来个认证(stack canaries)
|
|
但是,除了缓冲区溢出,还有另一种攻击的方式,称为返回导向编程。可以利用修改已有的代码,来绕过系统和编译器的保护机制,攻击者控制堆栈调用以劫持程序控制流并执行针对性的机器语言指令序列(称为Gadgets)。每一段 gadget 通常结束于 return 指令,并位于共享库代码中的子程序。系列调用这些代码,攻击者可以在拥有更简单攻击防范的程序内执行任意操作。
具体利用缓冲区进行攻击的例子,会在【读厚 CSAPP】III Attack Lab 中进行讲解,这里不再赘述。
GDB from CSAPP 3.10
- run
OBJDUMPto get a disassembled version of the programme - set breakpoints near points of interest in the programme.
- if breakpoint is hit, the programme will halt and return control control to th euser. From breakpoint, we can examine different registers and memory locations in various formats. We can also single-step the programme, running just a few instructions a time, or we can proceed to the next breakpoint.

|
|
这些命令在 / 后面的后缀(如 2x、2d、s、g、20c)指定了查看内存的方式和数量。具体来说:
-
第一个数字(如
2、20)指定要查看的单位数量。 -
第二个字母(如
x、d、s、g、c)指定单位类型和显示格式,其中:-
c/d/x分别代表以字符 / 十进制 / 十六进制格式显示内存内容。 -
s代表以字符串格式显示内存内容。 -
b/h/w/g分别代表以 1 / 2 / 4 / 8 字节为单位(unit)显示内存内容。当使用
x/b、x/h、x/w、x/g时,unit会保留对应改变,直到你再次使用这些命令。
-
4.程序优化(Code Optimization)
前面了解了许多机器代码以及程序执行机制的相关知识,这一节我们来学习如何利用这些性质来优化代码。
- 用好编译器的不同参数设定
- 写对编译器友好的代码,尤其是过程调用和内存引用,时刻注意内层循环
- 根据机器来优化代码,包括利用指令级并行、避免不可以预测的分支以及有效利用缓存
通用技巧
即使是常数项系数的操作,同样可能影响性能。性能的优化是一个多层级的过程:算法、数据表示、过程和循环,都是需要考虑的层次。于是,这就要求我们需要对系统有一定的了解,例如:
- 程序是如何编译和执行的
- 现代处理器和内存是如何工作的
- 如何衡量程序的性能以及找出瓶颈
- 如何保持代码模块化的前提下,提高程序性能
最根源的优化是对编译器的优化,比方说再寄存器分配、代码排序和选择、死代码消除、效率提升等方面,都可以由编译器做一定的辅助工作。
但是因为这毕竟是一个自动的过程,而代码本身可以非常多样,在不能改变程序行为的前提下,很多时候编译器的优化策略是趋于保守的。并且大部分用来优化的信息来自于过程和静态信息,很难充分进行动态优化。
接下来会介绍一些我们自己需要注意的地方,而不是依赖处理器或者编译器来解决。
代码移动
如果一个表达式总是得到同样的结果,最好把它移动到循环外面,这样只需要计算一次。编译器有时候可以自动完成,比如说使用 -O1 优化。一个例子:
|
|
这里 n*i 是重复被计算的,可以放到循环外面
|
|
减少计算强度
用更简单的表达式来完成用时较久的操作,例如 16*x 就可以用 x << 4 代替,一个比较明显的例子是,可以把乘积转化位一系列的加法,如下:
|
|
可以把 n*i 用加法代替,比如:
|
|
公共子表达式
可以重用部分表达式的计算结果,例如:
|
|
可以优化为
|
|
虽然说,现代处理器对乘法也有很好的优化,但是既然可以从 3 次乘法运算减少到只需要 1 次,为什么不这样做呢?蚂蚁再小也是肉嘛。
小心过程调用
我们先来看一段代码,找找有什么问题:
|
|
问题在于,在字符串长度增加的时候,时间复杂度是二次方的!每次循环中都会调用一次 strlen(s),而这个函数本身需要通过遍历字符串来取得长度,因此时间复杂度就成了二次方。
可以怎么优化呢?简单,那么只计算一次就好了:
|
|
为什么编译器不能自动把这个过程调用给移到外面去呢?
前面说过,编译器的策略必须是保守的,因为过程调用之后所发生的事情是不可控的,所以不能直接改变代码逻辑,比方说,假如 strlen 这个函数改变了字符串 s 的长度,那么每次都需要重新计算。如果移出去的话,就会导致问题。
所以很多时候只能靠程序员自己进行代码优化。
注意内存问题
接下来我们看另一段代码及其汇编代码
|
|
对应的汇编代码为
|
|
可以看到在汇编中,每次都会把 b[i] 存进去再读出来,为什么编译器会有这么奇怪的做法呢?因为有可能这里的 a 和 b 指向的是同一块内存地址,那么每次更新,都会使得值发生变化。但是中间过程是什么,实际上是没有必要存储起来的,所以我们引入一个临时变量,这样就可以消除内存引用的问题。
|
|
对应的汇编代码为
|
|
可以看到,加入了临时变量后,解决了奇怪的内存问题,生成的汇编代码干净了许多。
处理条件分支
这个问题,如果不是对处理器执行指令的机制有一定了解的话,可能会难以理解。
现代处理器普遍采用超标量设计,也就是基于流水线来进行指令的处理,也就是说,当执行当前指令时,接下来要执行的几条指令已经进入流水线的处理流程了。
这个很重要,对于顺序执行来说,不会有任何问题,但是对于条件分支来说,在跳转指令时可能会改变程序的走向,也就是说,之前载入的指令可能是无效的。这个时候就只能清空流水线,然后重新进行载入。为了减少清空流水线所带来的性能损失,处理器内部会采用称为『分支预测』的技术。
比方说在一个循环中,根据预测,可能除了最后一次跳出循环的时候会判断错误之外,其他都是没有问题的。这就可以接受,但是如果处理器不停判断错误的话(比方说代码逻辑写得很奇怪),性能就会得到极大的拖累。
分支问题有些时候会成为最主要的影响性能的因素,但有的时候其实很难避免。
5.The Memory Hierarchy&Cache Memories
The Memory Hierarchy see 【读薄 CSAPP】叁 内存与缓存 | 小土刀 3.0
Cache Memory
-
Cold (compulsory) miss
- Cold misses occur because the cache is empty.
-
Conflict miss
-
Most caches limit blocks at level k+1 to a small subset (sometimes a singleton) of the block positions at level k.
-
E.g. Block i at level k+1 must be placed in block (i mod 4) at level k.
-
Conflict misses occur when the level k cache is large enough, but multiple data objects all map to the same level k block.
-
E.g. Referencing blocks 0, 8, 0, 8, 0, 8, … would miss every time.
-
-
Capacity miss
- Occurs when the set of active cache blocks (working set) is larger than the cache.
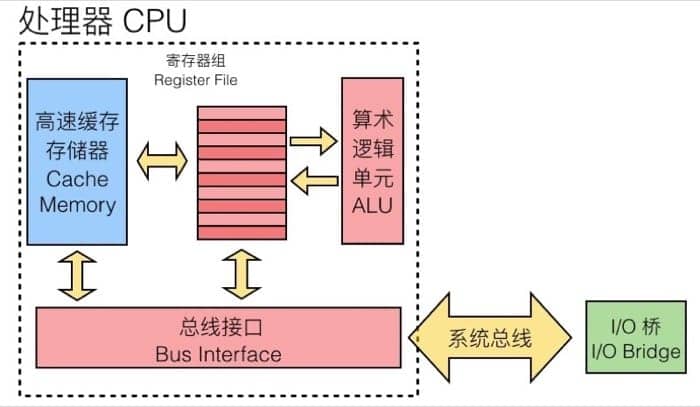
高速缓存存储器(Cache Memory)是 CPU 缓存系统甚至是金字塔式存储体系中最有代表性的缓存机制,前面我们了解了许多概念,这一节我们具体来看看高速缓存存储器是如何工作的。
首先要知道的是,高速缓存存储器是由硬件自动管理的 SRAM 内存,CPU 会首先从这里找数据,其所处的位置如下(蓝色部分):
然后我们需要关注高速缓冲存储器的三个关键组成部分(注意区分大小写):
- S 表示集合(set)数量
- E 表示数据行(line)的数量
- B 表示每个缓存块(block)保存的字节数目
在图上表示出来就是
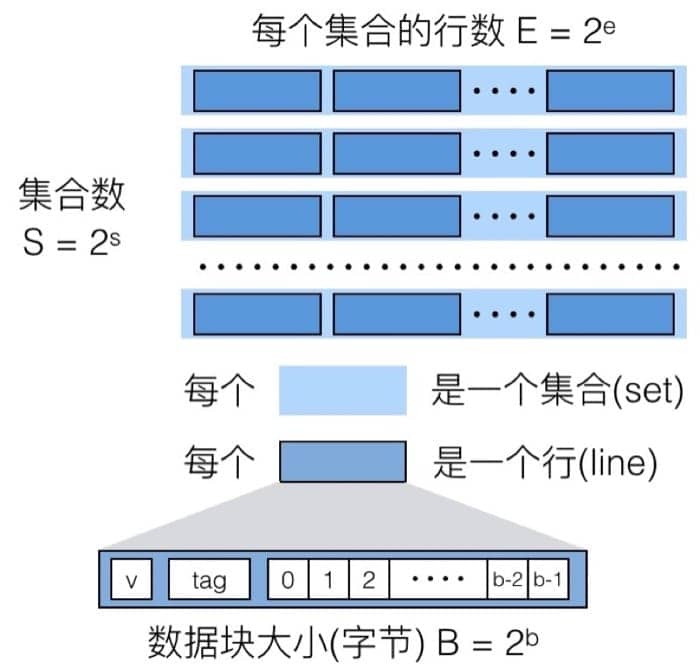 $$
C=S×E×BC=S×E×B
$$
$$
C=S×E×BC=S×E×B
$$实际上可以理解为三种层级关系,对应不同的索引,这样分层的好处在于,通过层级关系简化搜索需要的时间,并且和字节的排布也是一一对应的(之后介绍缓存的时候就体现得更加明显)。
当处理器需要访问一个地址时,会先在高速缓冲存储器中进行查找,查找过程中我们首先在概念上把这个地址划分成三个部分:

读取
具体在从缓存中读取一个地址时,首先我们通过 set index 确定要在哪个 set 中寻找,确定后利用 tag 和同一个 set 中的每个 line 进行比对,找到 tag 相同的那个 line,最后再根据 block offset 确定要从 line 的哪个位置读起(这里的而 line 和 block 是一个意思)。
当 E=1 时,也就是每个 set 只有 1 个 line 的时候,称之为直接映射缓存(Direct Mapped Cache),如下图所示
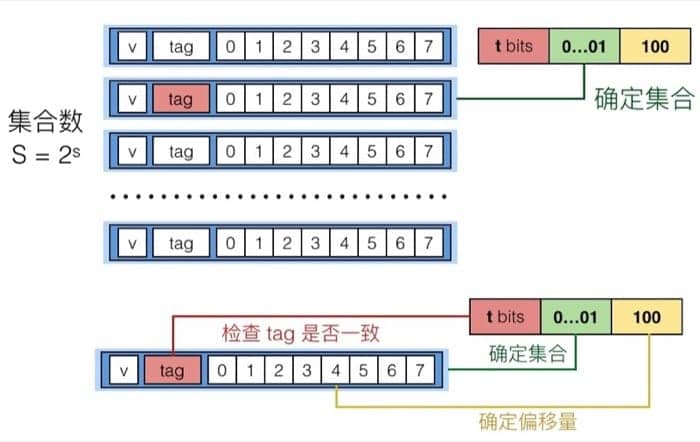
这种情况下,因为每个 set 对应 1 个 line,反过来看,1 个 line 就需要一个 set,所以 set index 的位数就会较多(和之后的多路映射对比)。具体的检索过程就是先通过 set index 确定哪个 set,然后看是否 valid,然后比较那个 set 里唯一 line 的 tag 和地址的 t bits 是否一致,就可以确定是否缓存命中。
命中之后根据 block offset 确定偏移量,因为需要读入一个 int,所以会读入 4 5 6 7 这四个字节(假设缓存是 8 个字节)。如果 tag 不匹配的话,这行会被扔掉并放新的数据进来。
然后我们来看一个具体的例子,假设我们的寻址空间是 M=16 字节,也就是 4 位的地址,对应 B=2, S=4, E=1,我们按照如下顺序进行数据读取:
0 00 0, miss0 00 1, hit0 11 1, miss1 00 0, miss0 00 0, miss
缓存中的具体情况是,这里 x 表示没有任何内容
|
|
缓存的大小如图所示,对应就是有 4 个 set,所以需要 2 位的 set index,所以进行读入的时候,会根据中间两位来确定在哪个 set 中查找,其中 8 和 0,因为中间两位相同,会产生冲突,导致连续 miss,这个问题可以用多路映射来解决。
当 E 大于 1 时,也就是每个 set 有 E 个 line 的时候,称之为 E 路联结缓存。这里每个 set 有两个 line,所以就没有那么多 set,也就是说 set index 可以少一位(集合数量少一倍)。
再简述一下整个过程,先从 set index 确定那个 set,然后看 valid 位,接着利用 t bits 分别和每个 line 的 tag 进行比较,如果匹配则命中,那么返回 4 5 位置的数据,如果不匹配,就需要替换,可以随机替换,也可以用 least recently used(LRU) 来进行替换。
我们再用刚才的例子来看看是否会增加命中率,这里假设我们的寻址空间是 M=16 字节,也就是 4 位的地址,对应 B=2, S=2, E=2,我们按照如下顺序进行数据读取:
0 00 0, miss0 00 1, hit0 11 1, miss1 00 0, miss0 00 0, hit
缓存中的具体情况是,这里 x 表示没有任何内容
|
|
可以看到因为每个 set 有 2 个 line,所以只有 2 个 set,set index 也只需要 1 位了,这个情况下即使 8 和 0 的 set index 一致,因为一个 set 可以容纳两个数据,所以最后一次访问 0,就不会 miss 了。
写入
在整个存储层级中,不同的层级可能会存放同一个数据的不同拷贝(如 L1, L2, L3, 主内存, 硬盘)。如果发生写入命中的时候(也就是要写入的地址在缓存中有),有两种策略:
- Write-through: 命中后更新缓存,同时写入到内存中
- Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
在写入 miss 的时候,同样有两种方式:
- Write-allocate: 载入到缓存中,并更新缓存(如果之后还需要对其操作,这个方式就比较好)
- No-write-allocate: 直接写入到内存中,不载入到缓存
这四种策略通常的搭配是:
- Write-through + No-write-allocate
- Write-back + Write-allocate
其中第一种可以保证绝对的数据一致性,第二种效率会比较高(通常情况下)。
Different Indexing


Due to spatial locality, most data in real-world programs is stored in contiguous memory regions (like arrays or buffers).
This means that when a program accesses memory sequentially, only the lower bits of the address (which indicate the offset within a block) change frequently, while the higher bits (which represent the larger memory block or region) remain constant until a larger step is taken.
So $TTSSBB$ is better than $SSTTBB$ because the former indexing changes its Set index more frequently, resulting to more seperate data and less frequent comflict miss.
Cache lab
- “I” denotes an instruction load, “L” a data load, “S” a data store, and “M” a data modify (i.e., a data load followed by a data store).
- ’load’ stands for accessing the bits within a cache block—if they’re already in the cache, it just reads the relevant portion; if not, the entire block is loaded first before reading out the desired bits.
6.Linking
7.Exceptional Control Flow(异常流控制)
Processors do only one thing:
-
From startup to shutdown, a CPU simply reads and executes (interprets) a sequence of instructions, one at a time
-
This sequence is the CPU’s control flow (or flow of control)
Up to now: two mechanisms for changing control flow:
-
Jumps and branches
-
Call and return
React to changes in program state
但是遇到异常的控制流时,就没办法应对了,所以需要异常流控制。
异常控制流存在于系统的每个层级,最底层的机制称为异常(Exception),用以改变控制流以响应系统事件,通常是由硬件的操作系统共同实现的。更高层次的异常控制流包括进程切换(Process Context Switch)、信号(Signal)和非本地跳转(Nonlocal Jumps),也可以看做是一个从硬件过渡到操作系统,再从操作系统过渡到语言库的过程。进程切换是由硬件计时器和操作系统共同实现的,而信号则只是操作系统层面的概念了,到了非本地跳转就已经是在 C 运行时库中实现的了。
Exceptions and Processes
异常 Exception
这里的异常指的是把控制交给系统内核来响应某些事件(例如处理器状态的变化),其中内核是操作系统常驻内存的一部分,而这类事件包括除以零、数学运算溢出、页错误、I/O 请求完成或用户按下了 ctrl+c 等等系统级别的事件。
具体的过程可以用下图表示:
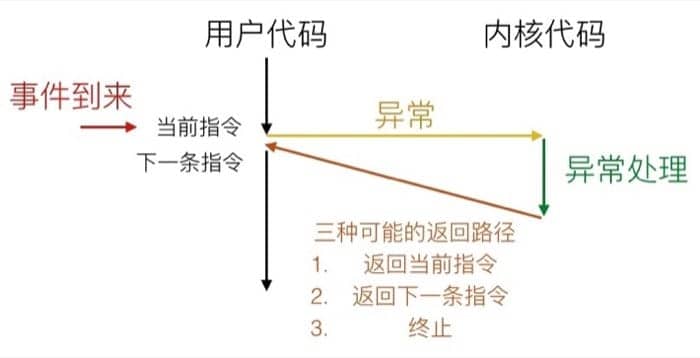
系统会通过异常表(Exception Table)来确定跳转的位置,每种事件都有对应的唯一的异常编号,发生对应异常时就会调用对应的异常处理代码
异步异常(中断)
异步异常(Asynchronous Exception)称之为中断(Interrupt),是由处理器外面发生的事情引起的。对于执行程序来说,这种“中断”的发生完全是异步的,因为不知道什么时候会发生。CPU对其的响应也完全是被动的,但是可以屏蔽掉。这种情况下:
- 需要设置处理器的中断指针(interrupt pin)
- 处理完成后会返回之前控制流中的『下一条』指令
比较常见的中断有两种:
- 计时器中断:计时器中断是由计时器芯片每隔几毫秒触发的,内核用计时器终端来从用户程序手上拿回控制权。
- I/O 中断:I/O 中断类型比较多样,比方说键盘输入了 ctrl-c,网络中一个包接收完毕和硬盘中传输的文件包送达,都会触发这样的中断。
同步异常
同步异常(Synchronous Exception)是因为执行某条指令所导致的事件,分为陷阱(Trap)、故障(Fault)和终止(Abort)三种情况。
| 类型 | 原因 | 行为 | 示例 |
|---|---|---|---|
| 陷阱 | 有意的异常 | 返回到下一条指令 | 系统调用,断点 |
| 故障 | 潜在可恢复的错误 | 返回到当前指令 | 页故障(page faults) |
| 终止 | 不可恢复的错误 | 终止当前程序 | 非法指令 |
这里需要注意三种不同类型的处理方式,比方说陷阱和中断一样,会返回执行『下一条』指令;而故障会重新执行之前触发事件的指令;终止则是直接退出当前的程序。
System Calls
系统调用看起来像是函数调用,但其实是走异常控制流的,在 x86-64 系统中,每个系统调用都有一个唯一的 ID,如
| 编号 | 名称 | 描述 |
|---|---|---|
| 0 | read |
读取文件 |
| 1 | write |
写入文件 |
| 2 | open |
打开文件 |
| 3 | close |
关闭文件 |
| 4 | stat |
获取文件信息 |
| 57 | fork |
创建进程 |
| 59 | execve |
执行一个程序 |
| 60 | _exit |
关闭进程 |
| 62 | kill |
向进程发送信号 |
举个例子,假设用户调用了 open(filename, options),系统实际上会执行 __open 函数,也就是进行系统调用 syscall,如果返回值是负数,则是出错,汇编代码如下:
|
|
对应的示意图是:
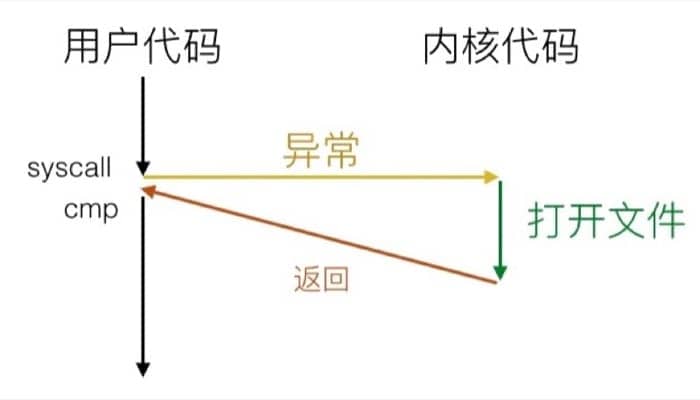
%raxcontains syscall number- Other arguments in
%rdi,%rsi,%rdx,%r10,%r8,%r9 - Return value in
%rax - Negative value is an error corresponding to negative
errno
这里我们以 Page Fault 为例,来说明 Fault 的机制。Page Fault 发生的条件是:
- 用户写入内存位置
- 但该位置目前还不在内存中
比如:
|
|
那么系统会通过 Page Fault 把对应的部分载入到内存中,然后重新执行赋值语句:
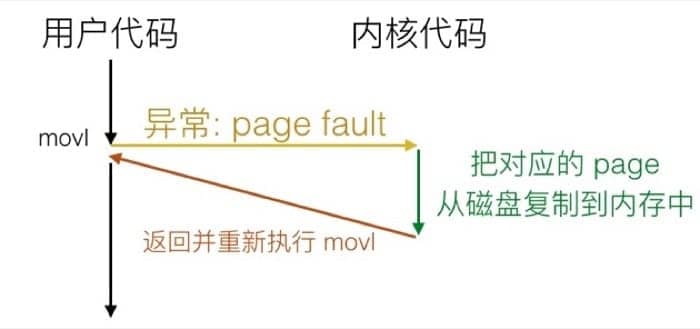
但是如果代码改为这样:
|
|
也就是引用非法地址的时候,整个流程就会变成:
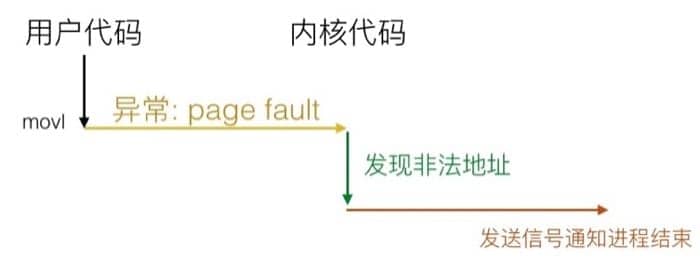
具体来说会像用户进程发送 SIGSEGV 信号,用户进程会以 segmentation fault 的标记退出。
从上面我们就可以看到异常的具体实现是依靠在用户代码和内核代码间切换而实现的,是非常底层的机制。
进程
进程(Processes)是计算机科学中最为重要的思想之一,进程才是程序(指令和数据)的真正运行实例。之所以重要,是因为进程给每个应用提供了两个非常关键的抽象:
-
逻辑控制流
-
Each program seems to have exclusive use of the CPU
-
Provided by kernel mechanism called context switching
-
-
私有地址空间
逻辑控制流通过称为上下文切换(context switching)的内核机制让每个程序都感觉自己在独占处理器。私有地址空间则是通过称为虚拟内存(virtual memory)的机制让每个程序都感觉自己在独占内存。这样的抽象使得具体的进程不需要操心处理器和内存的相关适宜,也保证了在不同情况下运行同样的程序能得到相同的结果。
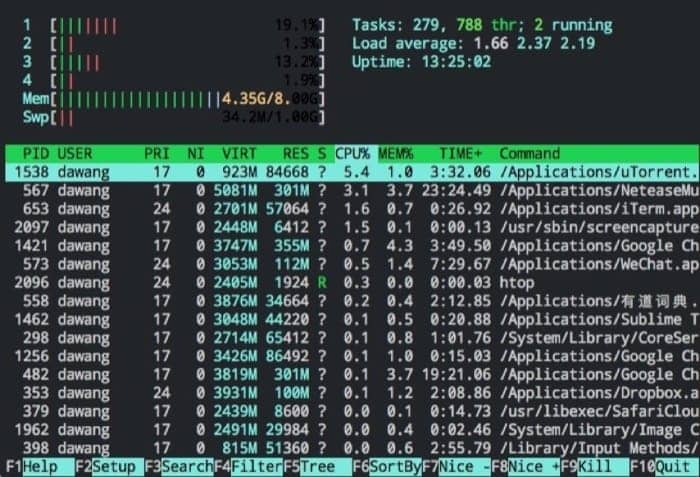
计算机会同时运行多个进程,有前台应用,也后台任务,我们在 Mac 的终端下输入 top(或者更酷炫的 htop),就可以看到如下的进程信息
进程切换 Process Context Switch
这么多进程,具体是如何工作的呢?我们来看看下面的示意图:
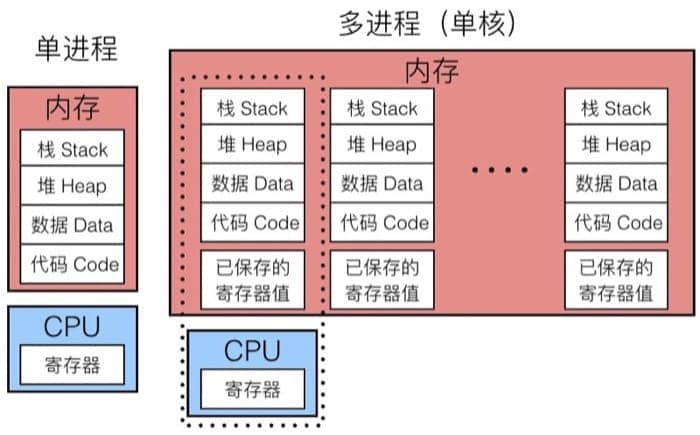
左边是单进程的模型,内存中保存着进程所需的各种信息,因为该进程独占 CPU,所以并不需要保存寄存器值。而在右边的单核多进程模型中,虚线部分可以认为是当前正在执行的进程,因为我们可能会切换到其他进程,所以内存中需要另一块区域来保存当前的寄存器值,以便下次执行的时候进行恢复(也就是所谓的上下文切换)。整个过程中,CPU 交替执行不同的进程,虚拟内存系统会负责管理地址空间,而没有执行的进程的寄存器值会被保存在内存中。切换到另一个进程的时候,会载入已保存的对应于将要执行的进程的寄存器值。
而现代处理器一般有多个核心,所以可以真正同时执行多个进程。这些进程会共享主存以及一部分缓存,具体的调度是由内核控制的,示意图如下:
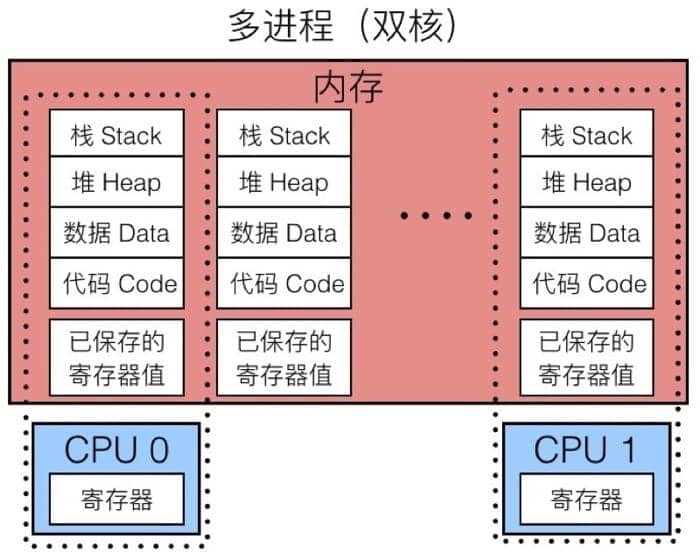
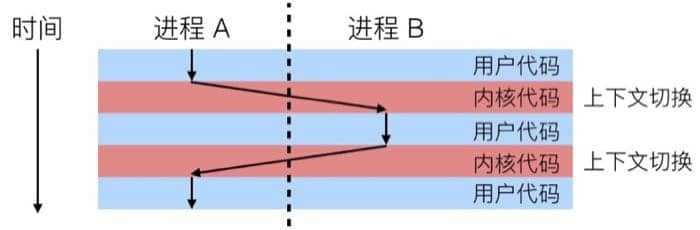
切换进程时,内核(kernel)会负责具体的调度,如下图所示
进程控制 Process Control
系统调用的错误处理
在遇到错误的时候,Linux 系统级函数通常会返回 -1 并且设置 errno 这个全局变量来表示错误的原因。使用的时候记住两个规则:
- 对于每个系统调用都应该检查返回值
- 当然有一些系统调用的返回值为 void,在这里就不适用
例如,对于 fork() 函数,我们应该这么写:
|
|
如果觉得这样写太麻烦,可以利用一个辅助函数:
|
|
我们甚至可以更进一步,把整个 fork() 包装起来,就可以自带错误处理,比如
|
|
调用的时候直接使用 pid = Fork(); 即可(注意这里是大写的 F)
获取进程信息
我们可以用下面两个函数获取进程的相关信息:
pid_t getpid(void)- 返回当前进程的 PIDpid_t getppid(void)- 返回当前进程的父进程的 PID
我们可以认为,进程有三个主要状态:
- 运行 Running
- 正在被执行、正在等待执行或者最终将会被执行
- 停止 Stopped
- 执行被挂起,在进一步通知前不会计划执行
- 终止 Terminated
- 进程被永久停止
另外的两个状态称为新建(new)和就绪(ready),这里不再赘述。
终止进程
在下面三种情况时,进程会被终止:
- 接收到一个终止信号
- 返回到
main - 调用了
exit函数
exit 函数会被调用一次,但从不返回,具体的函数原型是
|
|
创建进程
调用 fork 来创造新进程。这个函数很有趣,执行一次,但是会返回两次,具体的函数原型为
|
|
子进程几乎和父进程一模一样,
- 有相同且独立的虚拟地址空间,
- 有父进程已经打开的文件描述符(file descriptor)
- 有不同的进程 PID
看一个简单的例子
|
|
输出是
|
|
有以下几点需要注意:
- 调用一次,但是会有两个返回值
- 并行执行,不能预计父进程和子进程的执行顺序
- 拥有自己独立的地址空间(也就是变量都是独立的),除此之外其他都相同
- 在父进程和子进程中
stdout是一样的(都会发送到标准输出)
进程图
进程图是一个很好的帮助我们理解进程执行的工具:
- 每个节点代表一条执行的语句
- a -> b 表示 a 在 b 前面执行
- 边可以用当前变量的值来标记
printf节点可以用输出来进行标记- 每个图由一个入度为 0 的节点作为起始
对于进程图来说,只要满足拓扑排序,就是可能的输出。我们还是用刚才的例子来简单示意一下:
|
|
对应的进程图为
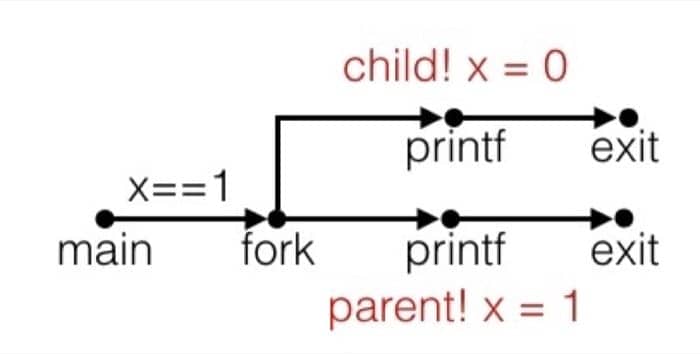
回收子进程
即使主进程已经终止,子进程也还在消耗系统资源,我们称之为『僵尸』。为了『打僵尸』,就可以采用『收割』(Reaping) 的方法。父进程利用 wait 或 waitpid 回收已终止的子进程,然后给系统提供相关信息,kernel 就会把 zombie child process 给删除。
如果父进程不回收子进程的话,通常来说会被 init 进程(pid == 1)回收,所以一般不必显式回收。但是在长期运行的进程中,就需要显式回收(例如 shell 和 server)。
如果想在子进程载入其他的程序,就需要使用 execve 函数,具体可以查看对应的 man page,这里不再深入。
Parent reaps a child by calling the wait function
- int wait(int child_status)
- Suspends current process until one of its children terminates
- Return value is the pid of the child process that terminated
- If child_status != NULL, then the integer it points to will be set to a value that indicates reason the child terminated and the exit status.
waitpid: Waiting for a Specific Process
- pid_t waitpid(pid_t pid, int & status, int option)
- Suspends current process until specific process terminates. Various options (see textbook)
execve: Loading and Running Programs
- int execve(char *filename, char *argv[], char *envp[])
- Loads and runs in the current process:
- Executable file filename. Can be object file or script file beginning with #!interpreter (e.g., #!/bin/bash)
- …with argument list argv
- By convention argv**[0]==filename**
- …and environment variable list envp
- name=value” strings (e.g., USER=droh)
- Loads and runs in the current process:
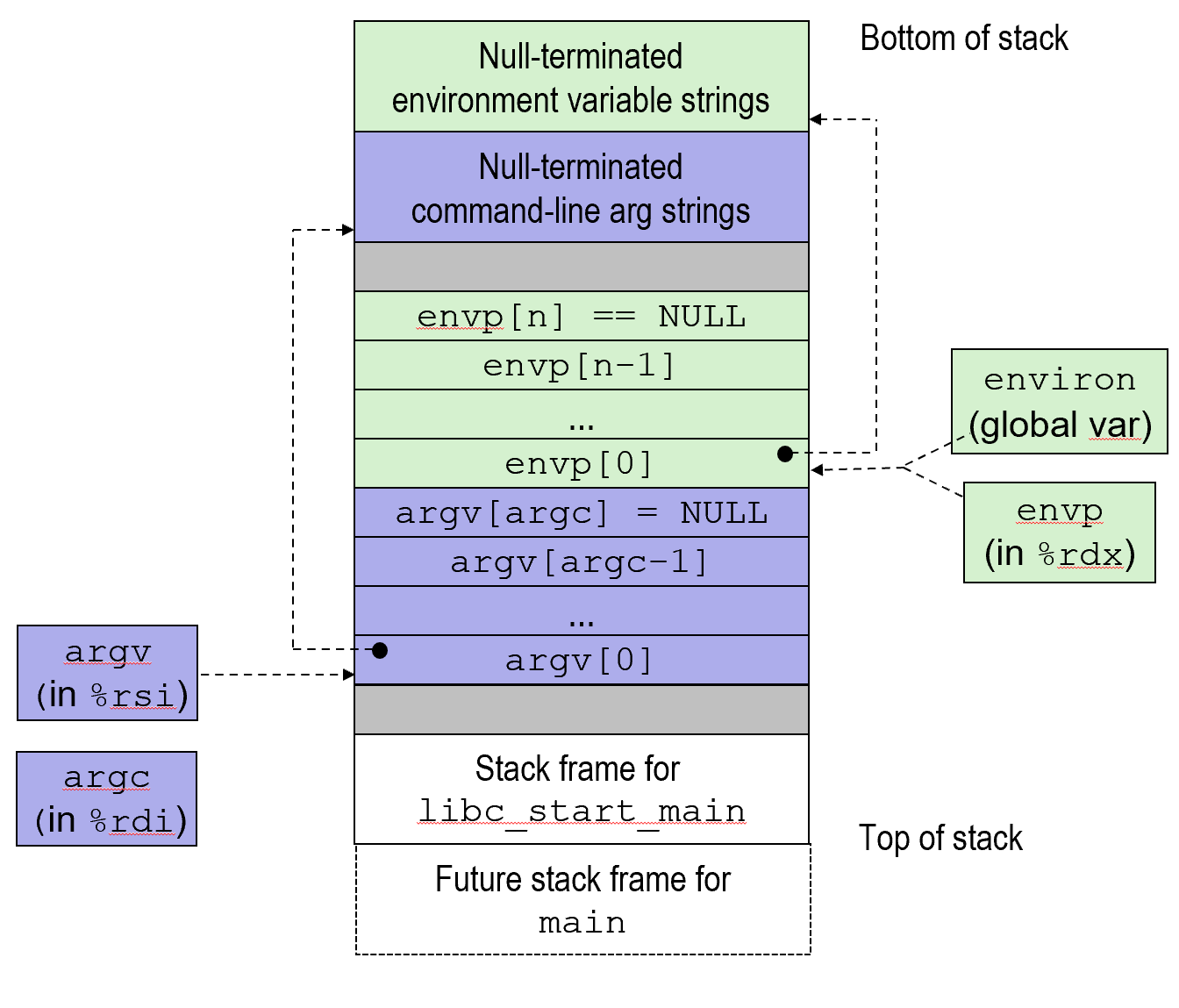
Structure of the stack when a new program starts
信号 Signal
Linux 的进程树,可以通过 pstree 命令查看,如下图所示:
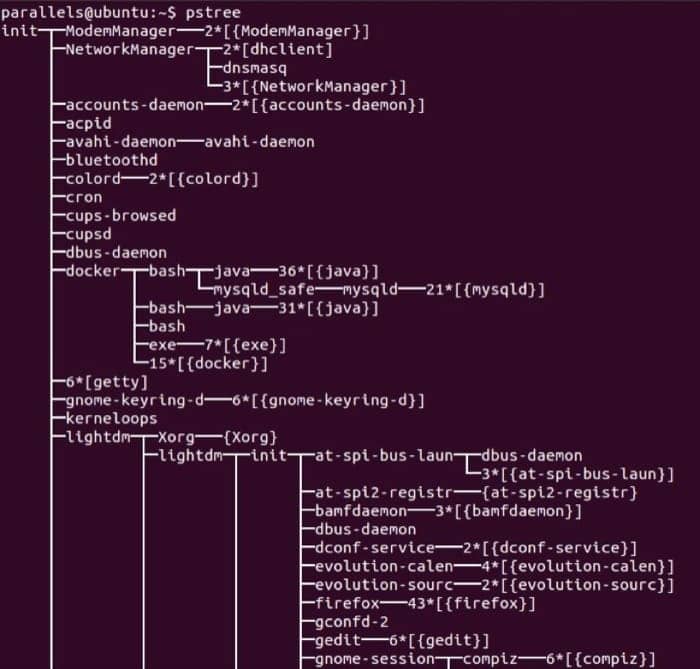
对于前台进程来说,我们可以在其执行完成后进行回收,而对于后台进程来说,因为不能确定具体执行完成的时间,所以终止之后就成为了僵尸进程,无法被回收并因此造成内存泄露。
这怎么办呢?同样可以利用异常控制流,当后台进程完成时,内核会中断常规执行并通知我们,具体的通知机制就是『信号』(signal)。
- Akin to exceptions and interrupts
- Sent from the kernel (sometimes at the request of another process) to a process
- Signal type is identified by small integer ID’s (1-30)
- Only information in a signal is its ID and the fact that it arrived
信号是 Unix、类 Unix 以及其他 POSIX 兼容的操作系统中进程间通讯的一种有限制的方式。它是一种异步的通知机制,用来提醒进程一个事件已经发生。当一个信号发送给一个进程,操作系统中断了进程正常的控制流程,此时,任何非原子操作都将被中断。如果进程定义了信号的处理函数,那么它将被执行,否则就执行默认的处理函数。
这样看来,信号其实是类似于异常和中断的,是由内核(在其他进程的请求下)向当前进程发出的。信号的类型由 1-30 的整数定义,信号所能携带的信息极少,一是对应的编号,二就是信号到达这个事实。下面是几个比较常用的信号的编号及简介:
| 编号 | 名称 | 默认动作 | 对应事件 |
|---|---|---|---|
| 2 | SIGINT | 终止 | 用户输入 ctrl+c |
| 9 | SIGKILL | 终止 | 终止程序(不能重写或忽略) |
| 11 | SIGSEGV | 终止且 Dump | 段冲突 Segmentation violation |
| 14 | SIGALRM | 终止 | 时间信号 |
| 17 | SIGCHLD | 忽略 | 子进程停止或终止 |
内核通过给目标进程发送信号,来更新目标进程的状态,具体的场景为:
- 内核检测到了如除以零(SIGFPE)或子进程终止(SIGCHLD)的系统事件
- 另一个进程调用了
kill指令来请求内核发送信号给指定的进程
目标进程接收到信号后,内核会强制要求进程对于信号做出响应,可以有几种不同的操作:
- 忽略这个型号
- 终止进程
- 捕获信号,执行信号处理器(signal handler),类似于异步中断中的异常处理器(exception handler)
具体的过程如下:
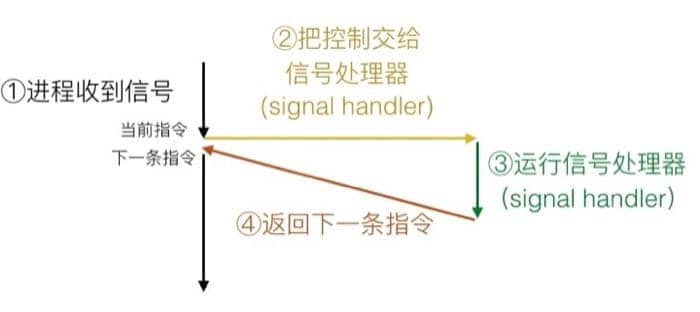
如果信号已被发送但是未被接收,那么处于等待状态(pending),同类型的信号至多只会有一个待处理信号(pending signal),一定要注意这个特性,因为内部实现机制不可能提供较复杂的数据结构,所以信号的接收并不是一个队列。比如说进程有一个 SIGCHLD 信号处于等待状态,那么之后进来的 SIGCHLD 信号都会被直接扔掉。
当然,进程也可以阻塞特定信号的接收,但信号的发送并不受控制,所以被阻塞的信号仍然可以被发送,不过直到进程取消阻塞该信号之后才会被接收。内核用等待(pending)位向量和阻塞(blocked)位向量来维护每个进程的信号相关状态。
进程组
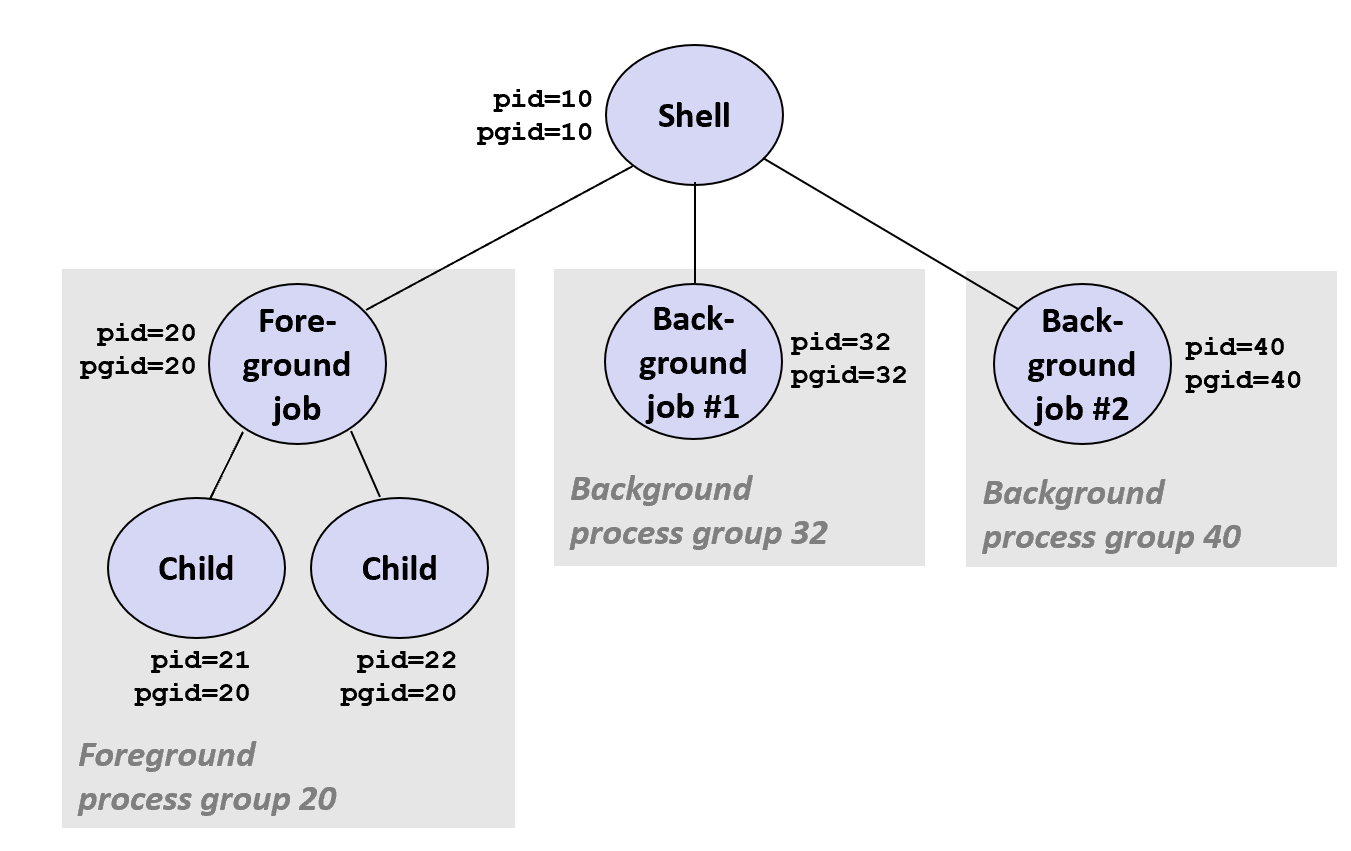
Every process belongs to exactly one process group.每个进程都只属于一个进程组,从前面的进程树状图中我们也能大概了解一二,想要了解相关信息,一般使用如下函数:
getpgrp()- 返回当前进程的进程组setpgid()- 设置一个进程的进程组
我们可以据此指定一个进程组或者一个单独的进程,比方说可以通过 kill 应用来发送信号,流入
|
|
这里可以看到,第一个命令只会杀掉编号为 24818 的进程,但是第二个命令,因为有两个进程都属于进程组 24817,所以会杀掉进程组中的每个进程。
我们也可以通过键盘让内核向每个前台进程发送 SIGINT(SIGTSTP) 信号
- SIGINT -
ctrl+c默认终止进程 - SIGTSTP -
ctrl+z默认挂起进程
下面是一个简单的例子
|
|
STAT 部分的第一个字母的意思
- S: 睡眠 sleeping
- T: 停止 stopped
- R: 运行 running
第二个字母的意思:
- s: 会话管理者 session leader
- +: 前台进程组
更多信息可以查看 man ps
如果想要发送信号,可以使用 kill 函数,下面是一个简单的示例,父进程通过发送 SIGINT 信号来终止正在无限循环的子进程。
|
|
接收信号
所有的上下文切换都是通过调用某个异常处理器(exception handler)完成的,内核会计算对易于某个进程 p 的 pnb 值:pnb = pending & ~blocked
-
如果
pnb == 0,那么就把控制交给进程 p 的逻辑流中的下一条指令 -
如果
1pnb != 0- 选择
pnb中最小的非零位 k,并强制进程 p 接收信号 k - 接收到信号之后,进程 p 会执行对应的动作
- 对
pnb中所有的非零位进行这个操作 - 最后把控制交给进程 p 的逻辑流中的下一条指令
- 选择
每个信号类型都有一个预定义的『默认动作』,可能是以下的情况:
- 终止进程
- 终止进程并 dump core
- 停止进程,收到
SIGCONT信号之后重启 - 忽略信号
signal 函数可以修改默认的动作,函数原型为 handler_t *signal(int signum, handler_t *handler)。我们通过一个简单的例子来感受下,这里我们屏蔽了 SIGINT 函数,即使按下 ctrl+c 也不会终止
|
|
信号处理器的工作流程可以认为是和当前用户进程『并发』的同一个『伪』进程,示意如下:
注:并行与并发的区别
计算机虽然只有一个 CPU,但操作系统能够将程序的执行单位细化,然后分开执行,从而实现伪并行执行。这种伪并行执行称为并发(concurrent)。使用多个 CPU 真的同时执行称为并行(parallel)
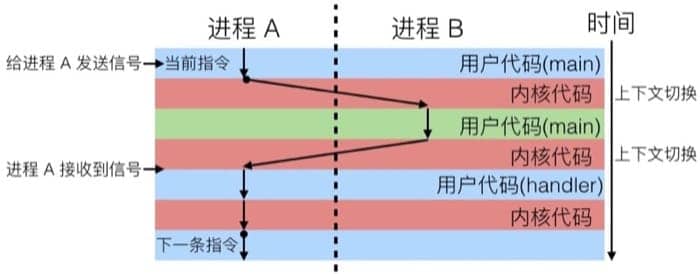
还有一个需要注意的是,信号处理器也可以被其他的信号处理器中断,控制流如下图所示:
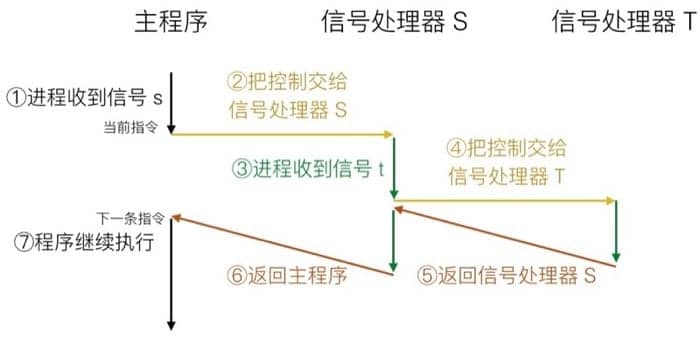
阻塞信号
我们知道,内核会阻塞与当前在处理的信号同类型的其他正待等待的信号,也就是说,一个 SIGINT 信号处理器是不能被另一个 SIGINT 信号中断的。
如果想要显式阻塞,就需要使用 sigprocmask 函数了,以及其他一些辅助函数:
sigemptyset- 创建空集sigfillset- 把所有的信号都添加到集合中(因为信号数目不多)sigaddset- 添加指定信号到集合中sigdelset- 删除集合中的指定信号
我们可以用下面这段代码来临时阻塞特定的信号:
|
|
安全处理信号
信号处理器的设计并不简单,因为它们和主程序并行且共享相同的全局数据结构,尤其要注意因为并行访问可能导致的数据损坏的问题,这里提供一些基本的指南(后面的课程会详细介绍)
- 规则 1:信号处理器越简单越好
- 例如:设置一个全局的标记,并返回
- 规则 2:信号处理器中只调用异步且信号安全(async-signal-safe)的函数
- 诸如
printf,sprintf,malloc和exit都是不安全的!
- 诸如
- 规则 3:在进入和退出的时候保存和恢复
errno- 这样信号处理器就不会覆盖原有的
errno值
- 这样信号处理器就不会覆盖原有的
- 规则 4:临时阻塞所有的信号以保证对于共享数据结构的访问
- 防止可能出现的数据损坏
- 规则 5:用
volatile关键字声明全局变量- 这样编译器就不会把它们保存在寄存器中,保证一致性
- 规则 6:用
volatile sig_atomic_t来声明全局标识符(flag)- 这样可以防止出现访问异常
这里提到的异步信号安全(async-signal-safety)指的是如下两类函数:
- 所有的变量都保存在栈帧中的函数
- 不会被信号中断的函数
- 异步且信号安全意为不会因为接受信号而导致数据类型损坏,死锁,内部状态损坏和崩坏。
Posix 标准指定了 117 个异步信号安全(async-signal-safe)的函数(可以通过 man 7 signal 查看)
非本地跳转 Non local Jump
所谓的本地跳转,指的是在一个程序中通过 goto 语句进行流程跳转,尽管不推荐使用goto语句,但在嵌入式系统中为了提高程序的效率,goto语句还是可以使用的。本地跳转的限制在于,我们不能从一个函数跳转到另一个函数中。如果想突破函数的限制,就要使用 setjmp 或 longjmp 来进行非本地跳转了。
-
int setjmp(jmp_buf j)
-
Must be called before longjmp
-
Identifies a return site for a subsequent longjmp
-
Called once, returns one or more times
-
-
void longjmp(jmp_buf j, int i)
-
Meaning:
-
return from the setjmp remembered by jump buffer j again …
-
… this time returning i instead of 0
-
-
Called after setjmp
-
Called once, but never returns
-
setjmp 保存当前程序的堆栈上下文环境(stack context),见[进程图](# 进程图),注意,这个保存的堆栈上下文环境仅在调用 setjmp 的函数内有效,如果调用 setjmp 的函数返回了,这个保存的堆栈上下文环境就失效了。调用 setjmp 的直接返回值为 0。
longjmp 将会恢复由 setjmp 保存的程序堆栈上下文,即程序从调用 setjmp 处重新开始执行,不过此时的 setjmp 的返回值将是由 longjmp 指定的值。注意longjmp 不能指定0为返回值,即使指定了 0,longjmp 也会使 setjmp 返回 1。
我们可以利用这种方式,来跳转到其他的栈帧中,比方说在嵌套函数中,我们可以利用这个快速返回栈底的函数,我们来看如下代码
|
|
对应的跳转过程为:
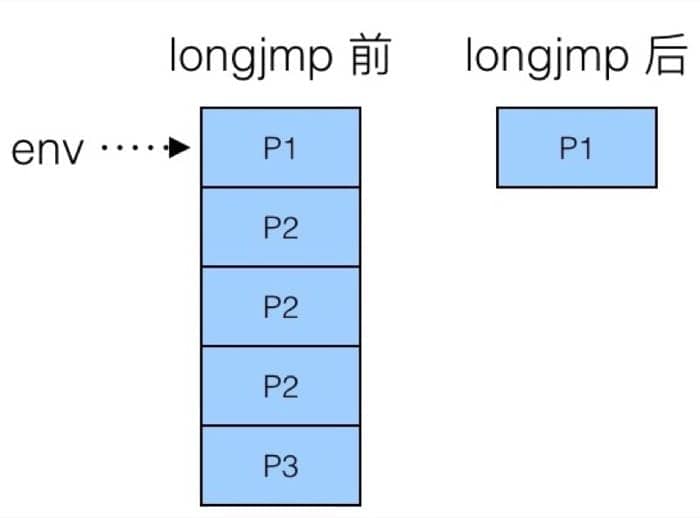
也就是说,我们直接从 P3 跳转回了 P1,但是也有限制,函数必须在栈中(也就是还没完成)才可以进行跳转,下面的例子中,因为 P2 已经返回,所以不能跳转了
|
|
因为 P2 在跳转的时候已经返回,对应的栈帧在内存中已经被清理,所以 P3 中的 longjmp 并不能实现期望的操作。
8.Virtual Memory
从物理内存到虚拟内存
物理地址一般应用在简单的嵌入式微控制器中(汽车、电梯、电子相框等),因为应用的范围有严格的限制,不需要在内存管理中引入过多的复杂度。
物理内存对于愈来愈快的cpu越来越容易空间不足。虚拟内存可以提供对每个进程独立的地址
但是对于计算机(以及其他智能设备)来说,虚拟地址则是必不可少的,通过 MMU(Memory management unit)把虚拟地址(Virtual Address, VA)转换为物理地址(Physical Address, PA),再由此进行实际的数据传输。大致的过程如下图所示
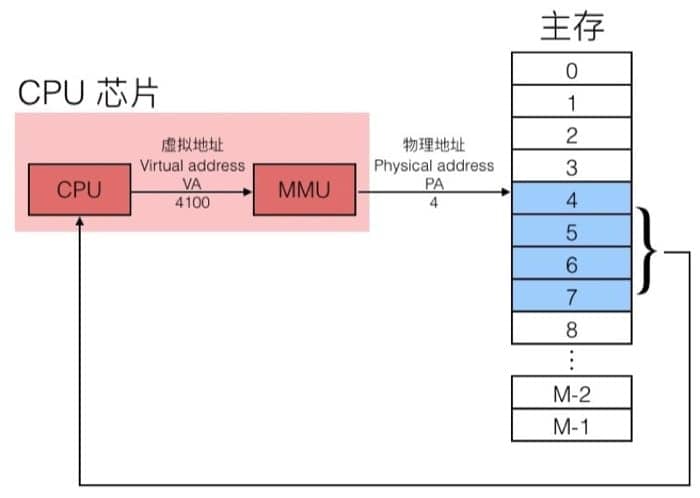
使用虚拟内存主要是基于下面三个考虑:
- 可以更有效率的使用内存:使用 DRAM 当做部分的虚拟地址空间的缓存
- 简化内存管理:每个进程都有统一的线性地址空间
- 隔离地址控件:进程之间不会相互影响;用户程序不能访问内核信息和代码
虚拟内存的三个角色
作为缓存工具
概念上来说,虚拟内存就是存储在磁盘上的 N 个连续字节的数组。这个数组的部分内容,会缓存在 DRAM 中,在 DRAM 中的每个缓存块(cache block)就称为页(page),如下图所示:
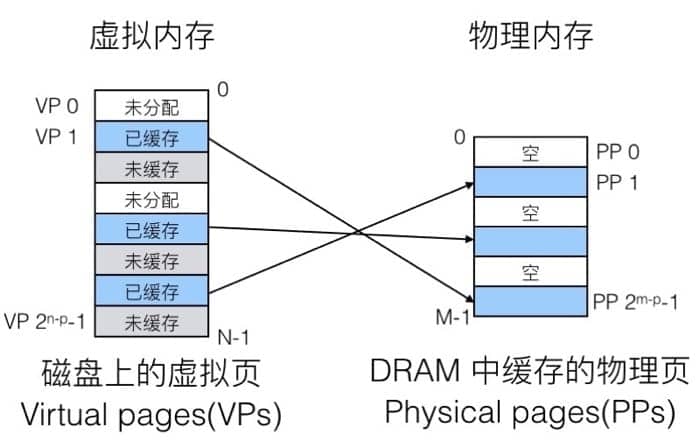
大致的思路和之前的 cache memory 是类似的,就是利用 DRAM 比较快的特性,把最常用的数据换缓存起来。如果要访问磁盘的话,大约会比访问 DRAM 慢一万倍,所以我们的目标就是尽可能从 DRAM 中拿数据。为此,我们需要:
- 更大的页尺寸(page size):通常是 4KB,有的时候可以达到 4MB
- 全相联(Fully associative):每一个虚拟页(virual page)可以放在任意的物理页(physical page)中,没有限制。
- 映射函数非常复杂,所以没有办法用硬件实现,通常使用 Write-back 而非 Write-through 机制
- Write-through: 命中后更新缓存,同时写入到内存中
- Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
具体怎么做呢?通过页表(page table)。每个页表实际上是一个数组,数组中的每个元素称为页表项(PTE, page table entry),每个页表项负责把虚拟页映射到物理页上。在 DRAM 中,每个进程都有自己的页表,具体如下
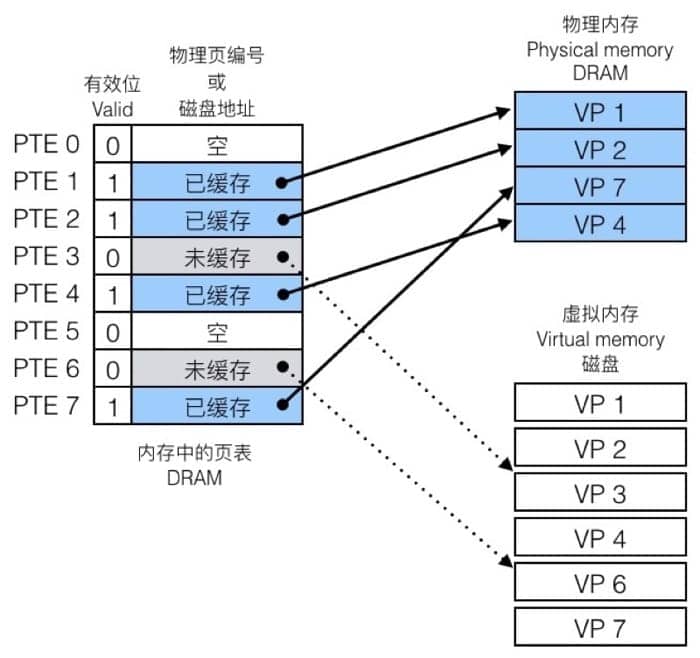
因为有一个表可以查询,就会遇到两种情况,一种是命中(Page Hit),另一种则是未命中(Page Fault)。
命中的时候,即访问到页表中蓝色条目的地址时,因为在 DRAM 中有对应的数据,可以直接访问。
不命中的时候,即访问到 page table 中灰色条目的时候,因为在 DRAM 中并没有对应的数据,所以需要执行一系列操作(从磁盘复制到 DRAM 中),具体为:
- 触发 Page fault,也就是一个异常
- Page fault handler 会选择 DRAM 中需要被置换的 page,并把数据从磁盘复制到 DRAM 中
- 重新执行访问指令,这时候就会是 page hit
复制过程中的等待时间称为 demand paging。
仔细留意上面的页表,会发现有一个条目是 null,也就是没有分配。具体的分配过程(比方说声明了一个大数组),就是让该条目指向虚拟内存(在磁盘上)的某个页,但并不复制到 DRAM,只有当出现 page fault 的时候才需要拷贝数据。
看起来『多此一举』,但是由于局部性原理,虚拟内存其实是非常高效的机制,这一部分最后提到了工作集(working set)[1]的概念,比较简单,这里不再赘述。
作为内存管理工具
前面提到,每个进程都有自己的虚拟地址空间,这样一来,对于进程来说,它们看到的就是简单的线性空间(但实际上在物理内存中可能是间隔、支离破碎的),具体的映射过程可以用下图表示:
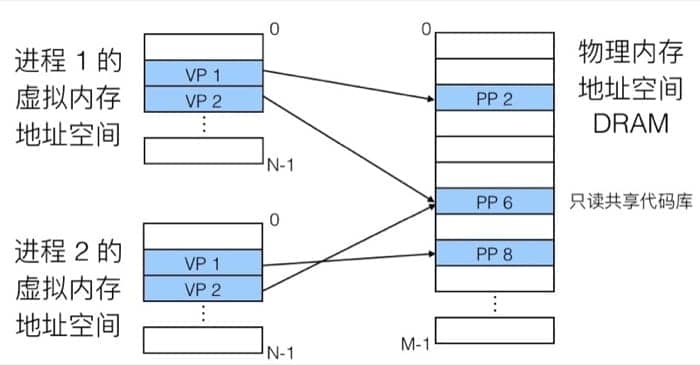
在内存分配中没有太多限制,每个虚拟页都可以被映射到任何的物理页上。这样也带来一个好处,如果两个进程间有共享的数据,那么直接指向同一个物理页即可(也就是上图 PP 6 的状况,只读数据)
虚拟内存带来的另一个好处就是可以简化链接和载入的结构(因为有了统一的抽象,不需要纠结细节)
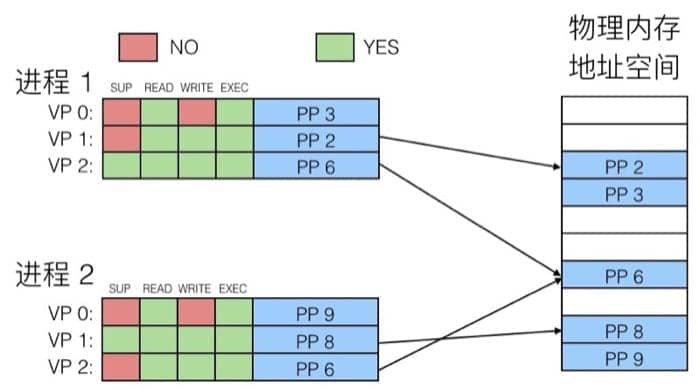
作为内存保护工具
页表中的每个条目的高位部分是表示权限的位,MMU 可以通过检查这些位来进行权限控制(读、写、执行),如下图所示:
地址翻译
开始之前先来了解以下参数:
N=2n,M=2m,P=2pN=2n,M=2m,P=2p
其中 N 表示虚拟地址空间中的地址数量,M 表示物理地址空间中的地址数量,P 是每一页包含的字节数(page size)。
虚拟地址(VA, Virtual Address)中的元素:
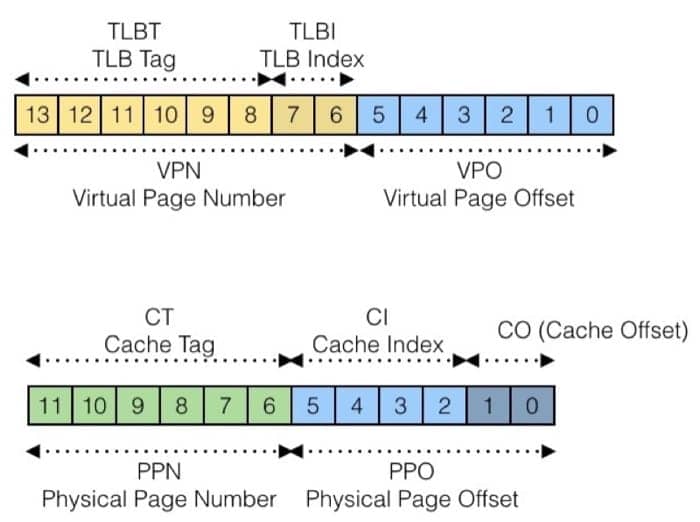
TLBI: TLB 的索引值TLBT: TLB 的标签(tag)VPO: 虚拟页偏移量VPN: 虚拟页编号
物理地址(PA, physical address)中的元素:
PPO: 物理页偏移量(与VPO的值相同)PPN: 物理页编号
然后我们通过一个具体的例子来说明如何进行地址翻译
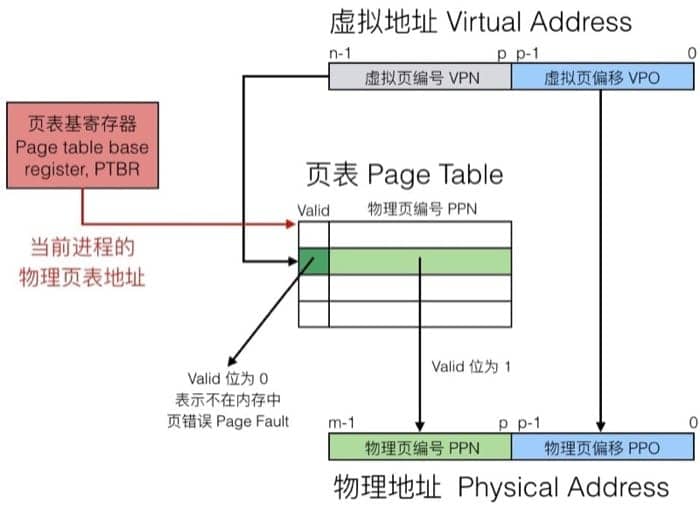
具体的访问过程为:
- 通过虚拟地址找到页表(page table)中对应的条目
- 检查有效位(valid bit),是否需要触发页错误(page fault)
- 然后根据页表中的物理页编号(physical page number)找到内存中的对应地址
- 最后把虚拟页偏移(virtual page offset)和前面的实际地址拼起来,就是最终的物理地址了
这里又分两种情况:Page Hit 和 Page Fault,我们先来看看 Page Hit 的情况
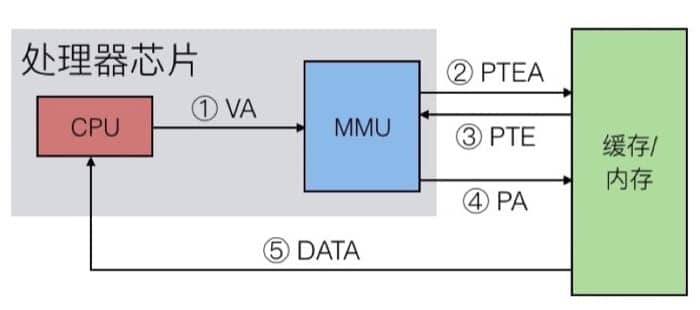
主要有 5 步,CPU 首先把虚拟地址发送给 MMU,MMU 检查缓存,并把从页表中得到对应的物理地址,接着 MMU 把物理地址发送给缓存/内存,最后从缓存/内存中得到数据。
而 Page Fault 的时候就复杂一些,第一次触发页错误会把页面载入内存/缓存,然后再以 Page Hit 的机制得到数据:
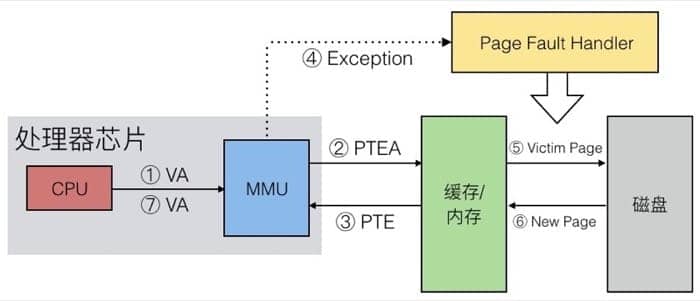
这里有 7 步,前面和 Page Hit 是一致的,先把虚拟地址发给 MMU 进行检查,然后发现没有对应的页,于是触发异常,异常处理器会负责从磁盘中找到对应页面并与缓存/内存中的页进行置换,置换完成后再访问同一地址,就可以按照 Page Hit 的方式来访问了。
虽然缓存已经很快了,但是能不能更快呢,为什么不能直接在 MMU 进行一部分的工作呢?于是就有了另外一个设计:Translation Lookaside Buffer(TLB)。TLB 实际上可以认为是页表在处理芯片上的缓存,整体的机制和前面提到的缓存很像,我们通过下面的图进行讲解:
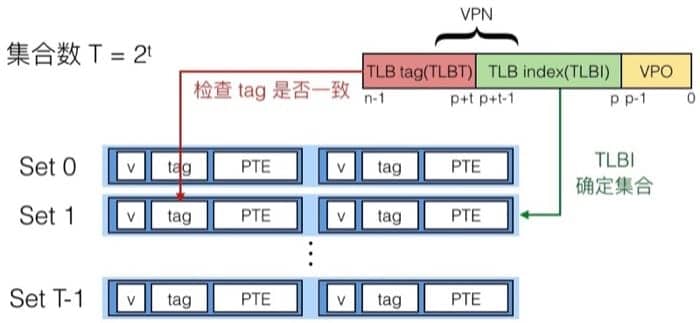
这里 VPN + VPO 就是虚拟地址,同样分成三部分,分别用于匹配标签、确定集合,如果 TLB 中有对应的记录,那么直接返回对应页表项(PTE)即可,如果没有的话,就要从缓存/内存中获取,并更新 TLB 的对应集合。
多层页表 Multi-Level Page Table
虽然页表是一个表,但因为往往虚拟地址的位数比物理内存的位数要大得多,所以保存页表项(PTE) 所需要的空间也是一个问题。举个例子:
假设每个页的大小是 4KB(2 的 12 次方),每个地址有 48 位,一条 PTE 记录有 8 个字节,那么要全部保存下来,需要的大小是:
248×2−12×23=239bytes248×2−12×23=239bytes
整整 512 GB!所以我们采用多层页表,第一层的页表中的条目指向第二层的页表,一个一个索引下去,最终寻找具体的物理地址,整个翻译过程如下:
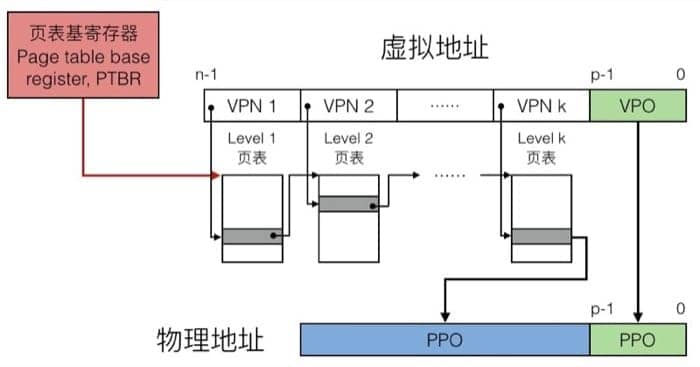
地址翻译实例
来看一个简单的例子,我们的内存系统设定如下:
- 14 位的虚拟地址
- 12 位的物理地址
- 页大小为 64 字节
TLB 的配置为:
- 能够存储 16 条记录
- 每个集合有 4 条记录
系统本身缓存(对应于物理地址):
- 16 行,每个块 4 个字节
- 直接映射(即 16 个集合)
TLB 中的数据为
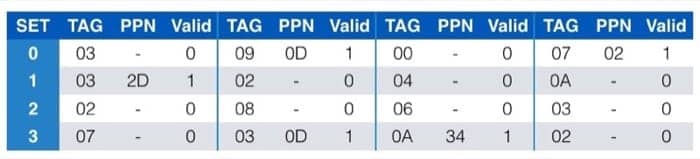
页表中的数据为(一共有 256 条记录,这里列出前 16 个)
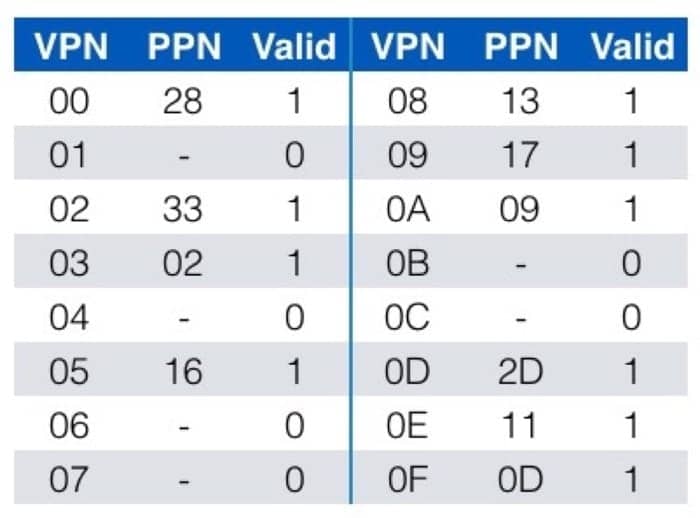
缓存中的数据为

一定要注意好不同部分的所代表的位置,这里我也会尽量写得清楚一些,来看第一个例子:
虚拟地址为
0x03D4
具体的转换过程如下图所示:
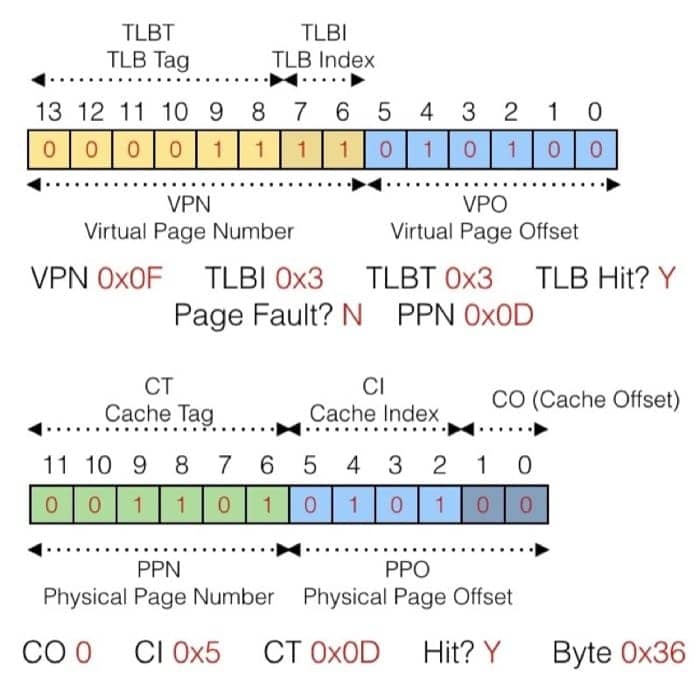
具体来梳理一次:
先看 TLB 中有没有对应的条目,所以先看虚拟地址的第 6-13 位,在前面的 TLB 表中,根据 TLBI 为 3 这个信息,去看这个 set 中有没有 tag 为 3 的项目,发现有,并且对应的 PPN 是 0x0D,所以对应到物理地址,就是 PPN 加上虚拟地址的 0-5 位,而具体的物理地址又可以在缓存中找到(利用 cache memory 的机制),就可以获取到对应的数据了。
下面的例子同样可以按照这个方法来进行分析
虚拟地址为
0x0020
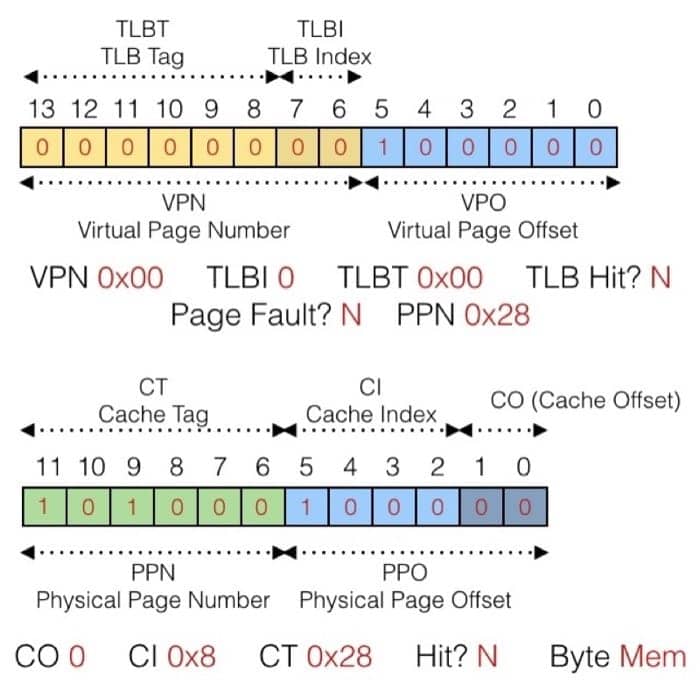
动态内存分配
前面了解了虚拟内存的相关知识,这一节我们来看看动态内存分配的基本概念,相信这之后就知道诸如 malloc 和 new 这类方法是怎么做的了。
程序员通过动态内存分配(例如 malloc)来让程序在运行时得到虚拟内存。动态内存分配器会管理一个虚拟内存区域,称为堆(heap)。
分配器以块为单位来维护堆,可以进行分配或释放。有两种类型的分配器:
- 显式分配器:应用分配并且回收空间(C 语言中的
malloc和free) - 隐式分配器:应用只负责分配,但是不负责回收(Java 中的垃圾收集)
先来看看一个简单的使用 malloc 和 free 的例子
|
|
为了讲述方便,我们做如下假设:
- 内存地址按照字来编码
- 每个字的大小和整型一致
例如:
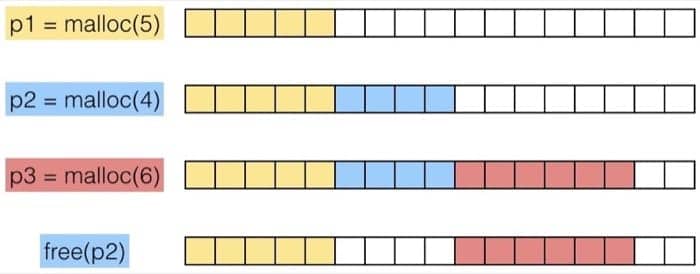
程序可以用任意的顺序发送 malloc 和 free 请求,free 请求必须作用与已被分配的 block。
分配器有如下的限制:
- 不能控制已分配块的数量和大小
- 必须立即响应
malloc请求(不能缓存或者给请求重新排序) - 必须在未分配的内存中分配
- 不同的块需要对齐(32 位中 8 byte,64 位中 16 byte)
- 只能操作和修改未分配的内存
- 不能移动已分配的块
性能指标
现在我们可以来看看如何去评测具体的分配算法了。假设给定一个 malloc 和 free 的请求的序列:
R0,R1,…,Rk,…,Rn−1R0,R1,…,Rk,…,Rn−1
目标是尽可能提高吞吐量以及内存利用率(注意,这两个目标常常是冲突的)
吞吐量是在单位时间内完成的请求数量。假设在 10 秒中之内进行了 5000 次 malloc 和 5000 次 free 调用,那么吞吐量是 1000 operations/second
另外一个目标是 Peak Memory Utilization,就是最大的内存利用率。
影响内存利用率的主要因素就是『内存碎片』,分为内部碎片和外部碎片两种。
内部碎片
内部碎片指的是对于给定的块,如果需要存储的数据(payload)小于块大小,就会因为对齐和维护堆所需的数据结构的缘故而出现无法利用的空间,例如:
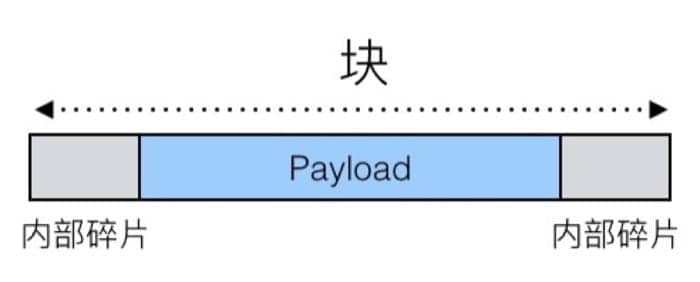
内部碎片只依赖于上一个请求的具体模式,所以比较容易测量。
外部碎片
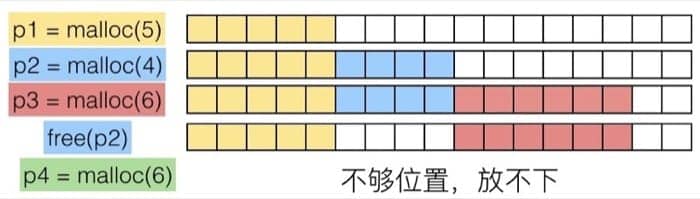
指的是内存中没有足够的连续空间,如下图所示,内存中有足够的空间,但是空间不连续,所以成为了碎片:
实现细节
我们已经知道了原理,现在就来看看怎么样能够实现一个高效的内存分配算法吧!在具体实现之前,需要考虑以下问题:
- 给定一个指针,我们如何知道需要释放多少内存?
- 如何记录未分配的块?
- 实际需要的空间比未分配的空间要小的时候,剩下的空间怎么办?
- 如果有多个区域满足条件,如何选择?
- 释放空间之后如何进行记录?
具体这部分书中提到了四种方法:
- 隐式空闲列表 Implicit List
- 显式空闲列表 Explicit List
- 分离的空闲列表 Segregated Free List
- 按照大小对块进行排序 Blocks Sorted by Size
因为涉及的细节比较多,建议是详读书本的对应章节(第二版和第三版均为第九章第九节),这里不再赘述(如果需要的话之后我在另起一篇做详细介绍)
这里提一点,就是如何确定哪部分空间合适,有三种方法:
- First Fit: 每次都从头进行搜索,找到第一个合适的块,线性查找
- Next Fit: 每次从上次搜索结束的位置继续搜索,速度较快,但可能会有更多碎片
- Best Fit: 每次遍历列表,找到最合适的块,碎片较少,但是速度最慢
更详细可以参考这两篇文章:Dynamic Memory Allocation - Basic Concept 和 Dynamic Memory Allocation - Advanced Concept
垃圾回收
所谓垃圾回收,就是我们不再需要显式释放所申请内存空间了,例如:
|
|
这种机制在许多动态语言中都有实现:Python, Ruby, Java, Perl, ML, Lisp, Mathematica。C 和 C++ 中也有类似的变种,但是需要注意的是,是不可能回收所有的垃圾的。
我们如何知道什么东西才是『垃圾』呢?简单!只要没有任何指针指向的地方,不管有没有用,因为都不可能被使用,当然可以直接清理掉啦。不过这其实是需要一些前提条件的:
- 我们可以知道哪里是指针,哪里不是指针
- 每个指针都指向 block 的开头
- 指针不能被隐藏(by coercing them to an
int, and then back again)
相关的算法如下:
- Mark-and-sweep collection (McCarthy, 1960)
- Reference counting (Collins, 1960)
- Copying collection (Minsky, 1963)
- Generational Collectors(Lieberman and Hewitt, 1983)
大部分比较常用的算法居然都有五十多年历史了,神奇。更多相关细节在维基百科[2]中都有详细介绍(中文版本质量较差,这里给出英文版)。
Segregated Free List
Due to lack of time, pleace check 9.9 in the book for more infomation.
内存陷阱
关于内存的使用需要注意避免以下问题:
- 解引用错误指针
- 读取未初始化的内存
- 覆盖内存
- 引用不存在的变量
- 多次释放同一个块
- 引用已释放的块
- 释放块失败
Dereferencing Bad Pointers
这是非常常见的例子,没有引用对应的地址,少了 &
|
|
Reading Uninitialized Memory
不能假设堆中的数据会自动初始化为 0,下面的代码就会出现奇怪的问题
|
|
Overwriting Memory
这里有挺多问题,第一种是分配了错误的大小,下面的例子中,一开始不能用 sizeof(int),因为指针的长度不一定和 int 一样。
|
|
第二个问题是超出了分配的空间,下面代码的 for 循环中,因为使用了 <=,会写入到其他位置
|
|
第三种是因为没有检查字符串的长度,超出部分就写到其他地方去了(经典的缓冲区溢出攻击也是利用相同的机制)
|
|
第四种是没有正确理解指针的大小以及对应的操作,应该使用 sizeof(int *)
|
|
第五种是引用了指针,而不是其指向的对象,下面的例子中,*size-- 一句因为 -- 的优先级比较高,所以实际上是对指针进行了操作,正确的应该是 (*size)--
|
|
Referencing Nonexistent Variables
下面的情况中,没有注意到局部变量会在函数返回的时候失效(所以对应的指针也会无效),这是传引用和返回引用需要注意的,传值的话则不用担心
|
|
Freeing Blocks Multiple Times
这个不用多说,不能重复搞两次
|
|
Referencing Freed Blocks
同样是很明显的错误,不要犯
|
|
Memory Leaks
用完没有释放,就是内存泄露啦
|
|
或者只释放了数据结构的一部分:
|
|