CS170
[!NOTE]
本笔记主要由UC Berkeley CS170的课程资料汇总而来,参考了高效算法与棘手问题 CS170 2022,2025年的课程主页CS 170 Spring 2025和一个伯克利在校学生所做的课堂笔记CS170_Lecture_Notes.pdf。因为没有找到合适的中文笔记,至动态规划部分的笔记基本上都是自己写的,后部分只要参考了上述笔记进行汉化加上自己的思考。
分治法
分治法分为三步:
- 将大问题分解为小的同类问题
- 递归解决小问题
- 将小问题结合
加法与乘法
对于两个个N位的数字,
$$ 1234\cdots N + 1234\cdots N $$相加的时间复杂度最小是\(O(N)\),但是一般不会计算加法的时间复杂度,只有在一些数字位数极大的领域才会考虑数字位数的影响,如密码学等,否则将加法视为常数时间。
而对于乘法来说:
$$ 1234\cdots N \times 1234\cdots N $$使用小学教的竖式法,对于每一个位数都要乘以乘数的所有N位数,所以时间复杂度是\(O(N^2)\)。那有没有更快的方法呢。
实际上,用分治法将两个乘数分为两部分:
$$ 1234\cdots|\cdots N \times 1234\cdots|\cdots N $$将四部分分别视为a,b,c,d。则原式等于:
$$ \begin{aligned} AB\times CD=&(A\times 10^{\frac N2} + B)\times (C\times 10^{\frac N2}+D)\\ =&AC\times 10^N+(AD+BC)\times 10^{\frac N2} + CD \end{aligned} $$因为ABCD四个部分的位长都是\(\frac N2\),所以其时间复杂度为:
$$ T(n)=\begin{cases} C &n=1\\ 4\cdot T(\frac n2)+ C\cdot n &n>1 \end{cases} $$
从上往下拆分,每下降一级\(T(n)\)会变成四份\(T(\frac n2)\),并且加上一份与\(n\)线性相关的\(Cn\)项来计算求和等工作,每次拆分都会产生一份常数项,到最小的时候\(T(n)\)为常数项,利用数列求和公式算出其时间复杂度是\(O(n^2)\)。那这有什么用,如果分治法和最普通的方法时间复杂度相同的话。这时便是Karatsuba算法发挥作用到时候了:
$$ AD+BC = (A+B)(C+D)-AB-CD $$因为我们要计算\(AB\)和\(CD\)的大小,可以利用这个关系将计算四项乘法的目标改为计算三项\((A+B)(C+D)\)和\(AB,CD\)。于是可以将递推公式优化为:
$$ T(n)=3T(\frac n2)+Cn\quad n>1 $$则树的高度仍为\(\log_2n\),但是项数变为\(3^{\log_2{n}}\)
$$ \begin{aligned} T(n)&=3\times T(\frac n2) + CN \\&=3\times [3\times T(\frac{n}{4})+C\frac n2]+ Cn \\&\,\,\,\vdots \\&=3^{\log_{2}n}\times T(1)+Cn + \frac 32Cn + (\frac 32)^2Cn +\cdots (\frac 32)^{\log_2{3}}\cdot Cn\\ &=e^{\frac{\ln n}{\ln2}\ln3}+ Cn\frac{1-(\frac 32)^{\log_2n+1}}{1-\frac 32}\\ &=n^{\log_2{3}}+Cn(3\cdot(\frac32)^{\log_2{n}}-2)\\ &=n^{\log_2{3}}+Cn(3\frac{n^{\log_2{3}}}{n}-2)\\ &=n^{\log_2{3}}+3Cn^{\log_2{3}}-2Cn\\ &=O(n^{\log_2{3}})\approx O(1.59) \end{aligned} $$主定理
对于一个大小为\(n\)的问题,每份分为\(a\)个大小为\(\frac nb\)的小问题,需要耗时\(O(n^d)\)来结合,有主定理(Master Theorem)
$$ T(n)=\begin{cases} O(n^d) &d>\log_b{a}\\ O(n^d\log{n}) &d=\log_b{a}\\ O(n^{\log_b{a}}) &d<\log_ba \end{cases} $$证明:
$$ \begin{aligned} T(n)&=a\cdot T(\frac nb)+Cn^d\\ &=a[a\cdot T(\frac{n}{b^2})+C(\frac nb)^d]+Cn^d\\ &\,\,\,\vdots\\ &=a^{\log_bn}\cdot T(1)+Cn^d+Cn^{d}(\frac a{b^d})+\cdots+Cn^d(\frac a{b^d})^{\log_bn-1}\\ &=n^{\log_ba}+Cn^d+Cn^{d}(\frac a{b^d})+\cdots+Cn^d(\frac a{b^d})^{\log_bn-1}\\ \end{aligned} $$这导致了三种不同情况:
- 等比公式公比等于1,即\(\frac{a}{b^d}=1,d=\log_ba\)
-
等比公式不等于1,分两种情况。
$$ \begin{aligned} 原式&=n^{\log_ba}+Cn^d\frac{1-(\frac a{b^d})^{\log_bn}}{1-\frac{a}{b^d}}\\ \end{aligned} $$-
\(\frac{a}{b^d}<1\),即\(d>\log_ba\)。求和公式趋近于1,而且\(n^d>n^{\log_ba}\),所以\(n^d\)占主导地位
$$ \begin{aligned} 原式&=O(n^d) \end{aligned} $$ -
\(\frac{a}{b^d}>1\),即\(d<\log_ba\)。又注意到\((\frac{a}{b^d})^{\log_bn}=\frac{n^{\log_ba}}{n^d}\),又有\(n^d
-
真是一场酣畅淋漓的数列大题(逃)
有了这个公式,可以将绝大部分的分治法性能分析用套公式代替。
确定性算法
确定性算法(Deterministic Algorithm)指的是在相同输入下,总能按照预先设定好的算法步骤产生相同输出的算法,也就是说,它在执行过程中没有任何随机性或不确定性。有别于随机算法(如 Las Vegas 或 Monte Carlo 算法),Monte Carlo算法有可能有高性能但是有部分概率会失败,Las Vegas算法能保证算法正确但是时间可能有不同。
Quick Select就是一种确定性算法,目的是挑选第k大的数字。有着线性的时间复杂度。
步骤:将数列五五分为一个小组,取每组中的中位数,组成一个新的数组,再取其中的中位数,进行快排,大于这个pivot的进入R数组,小于pivot的进入L数组,此时:
$$ \begin{cases} \text{if}\,\,k \le |L|\text{: return Select(L,k)}\\ \text{if}\,\,k = |L|+1\text{: return pivot}\\ \text{else}\text{: return Select(R,k-|L|-1)}\\ \end{cases} $$这时这个pivot大于一般的数组的3个整数,即\(\text{pivot}>\frac 35\cdot \frac 12=\frac{3}{10}\)的数组,同理也小于30%的数组元素,此时
$$ T(n)\leq T(\frac{7n}{10})+T(\frac{n}{5})+Cn $$利用数学归纳法:假设\(\forall n, T(n)\leq Kn\),有:
$$ T(\frac n5)+T(\frac{7n}{10})+Cn\leq Kn \\\leq K\frac 5n+K\frac{7n}{10}+Cn\leq Kn\\ K\geq10C $$快速傅里叶变换
研究完整数乘法后,我们来研究多项式乘法,有多项式\(A(x)=a_0+a_1x+\cdots+a_dx^{d-1}\)和\(B(x)=b_0+b_1+\cdots+b_dx^{d-1}\)
对于两个多项式的乘法:\(C(x)=A(x)\cdot B(x)=c_0+c_1x+\cdots+c_{2d}x_{2d-1}\),我们研究
$$ c_k=a_0b_k+a_1b_{k-1}+\cdots+a_kb_0=\sum_{i=0}^{k}a_ib_{k-1} $$朴素多项式计算整个$C(n)\(需要\)\Theta(n^2)$的时间
多项式的另一种表述
一个d次的多项式可以表述为d+1个点,我们可以用两种表述确定一个多项式:
- 多项式的系数\(a_0,a_1,a_2\cdots,a_d\)
- \(A(x_0),A(x_1)\cdots,A(x_d)\)的值
快速傅里叶变换通过重叠的点来减少计算。
评估了一下,本处用到的数学工具不是不熟就是没学到,决定弃置于此,前面的知识以后再来探索吧。包含lec4后半部分和lec5前部分
图论
数学上来说,如何表述一个图?
图G是一个顶点V和边E组成的对\((V,E)\),如果这个图不包含自环(self-loop),则称这个图为简单图(simple graph)
-
有向图(Directed Graph)
\(E\subseteq V\times V\),来表示一个有向边
-
无向图
\(E\)是无向的点的集合
计算机如何表述一个图?
比如,对于一个有向无环图(DAG)要如何表示这个图
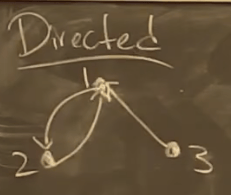
-
通过矩阵
$$ a_{ij}=\begin{cases} 1 \quad \text{如果存在边从}v_i\text{到}v_j\\ 0 \quad \text{其他情况} \end{cases} $$这样子一个图便可以通过一个一个矩阵来表示
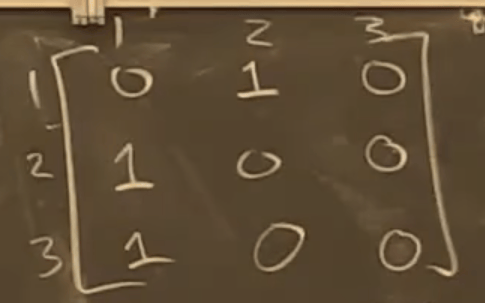 $$
a_{ij}=\begin{cases}
w_{ij} &(i,j)\in E\\
\infty & (i,j) \notin E
\end{cases}
$$
$$
a_{ij}=\begin{cases}
w_{ij} &(i,j)\in E\\
\infty & (i,j) \notin E
\end{cases}
$$ -
通过链表
性能分析
对于一个图,我们习惯用n表示顶点的个数,m表示边的个数,用\(d_u\)表示顶点\(u\)的链表长
| 矩阵法 | 链表法 | |
|---|---|---|
| 内存消耗 | \(n^2\) bits | \(n+m\) 字长 |
| 判断$(u,v)\in E( 的时间复杂度 | 1 | \(d_u+1\) |
| 遍历u的所有邻点的时间复杂度 | \(n\) | \(d_u+1\) |
如果一个图是稠密图,则一般来说矩阵法更内存友好,如果是一个稀疏图,如社交网络,则用链表法表示更内存友好
DFS
|
|
深度优先搜索在希腊神话中亦有记载,希腊神话中特修斯依靠阿里阿德涅给予的一团线走出复杂迷宫。这是一个有趣的类比,我们也可以使用粉笔和线来解决:
-
粉笔:在经过的路口(或者标志点)做记号,避免反复转圈或回到同一个地方时分不清是否来过。
-
团线:随着你的前进,线会不断从线团上“放出来”,这样一旦你要回头,你可以沿着线原路返回到上一个没探索过的岔路口。
在计算机中,我们可以用一个顶点的布尔值来表示是否被访问过,用栈来表示团线,模拟先进后出的性质。
在课上,我们用一个preorder和postorder序列来模拟栈,进入该点的时候将preorder设置为时钟值,遍历完该点所有的邻点后退出该点时设置postorder为时钟值,用preorder模拟先进,postorder模拟后出
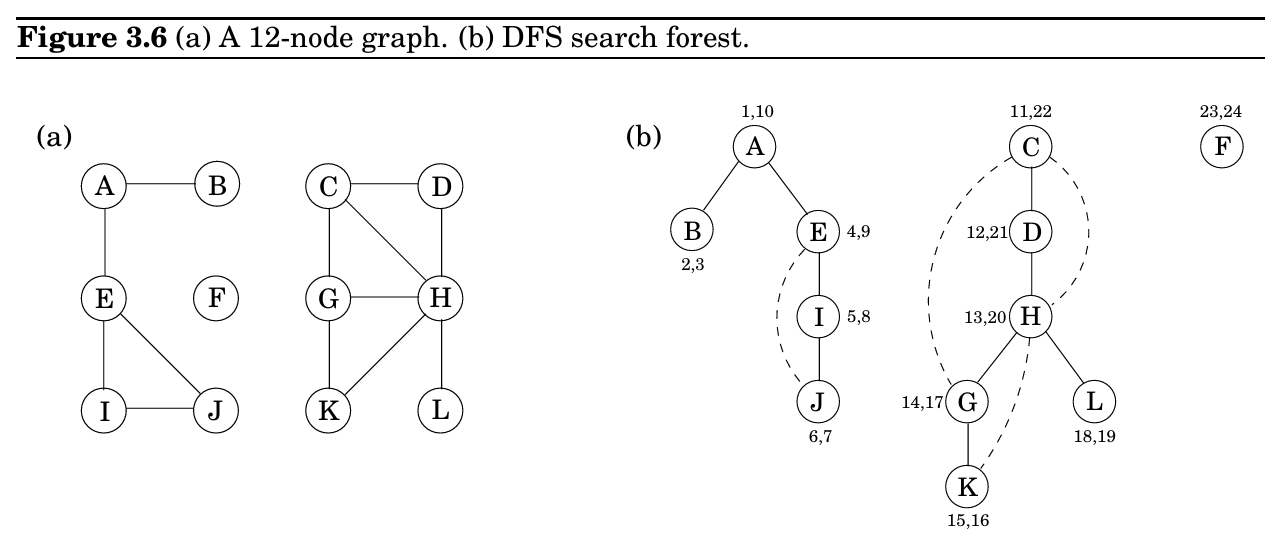
这个算法主要有两大操作:
- 固定时间的操作:更新preorder和postorder列表,将Boolean值修改为1
- 遍历每一个顶点的边
所以这个算法的时间复杂度是\(O(|V|+|E|)\)
Tree Edge是DFS森林的一部分
Forward Edge是从一个父节点指向非子节点的下游的树节点
Back Edge指向一个祖先(Ancestor)节点
Cross Edge是指向一个同级的节点
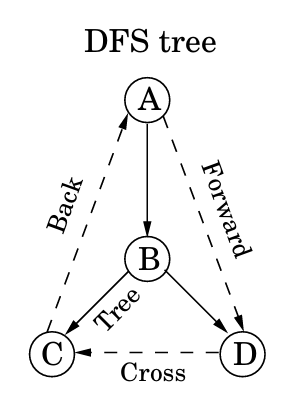
使用preorder和postorder数组还可用于拓扑排序(Topological Sorting),比如对于两个节点\(u,v\),假设\(u\)是\(v\)的祖先节点,则有:
\(
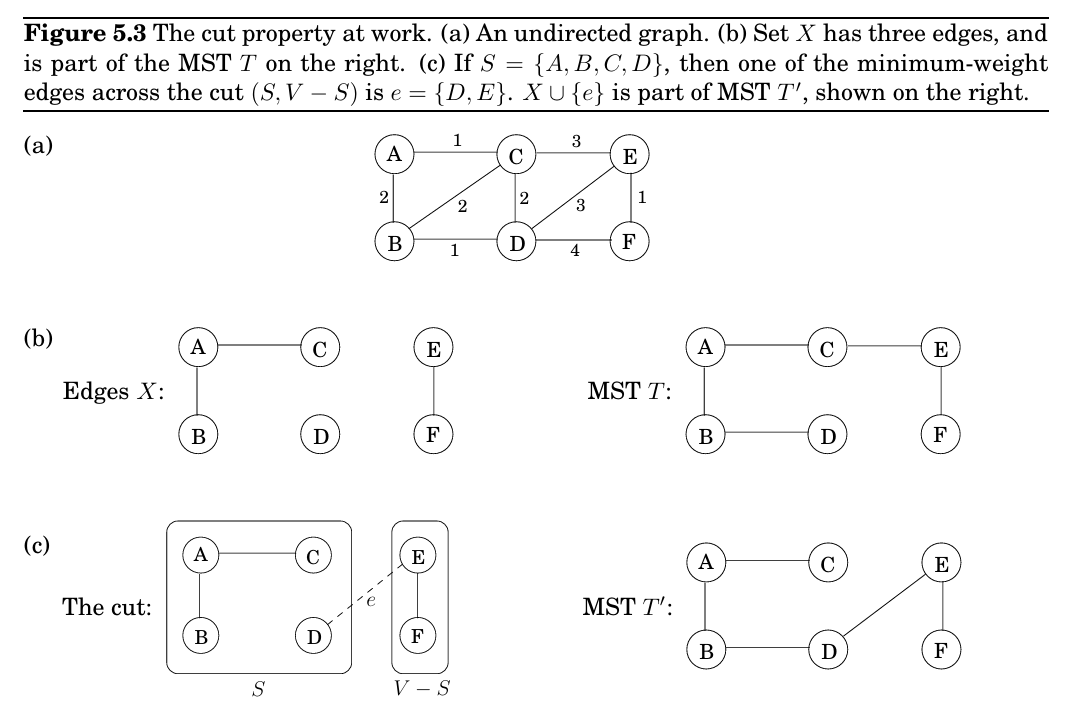
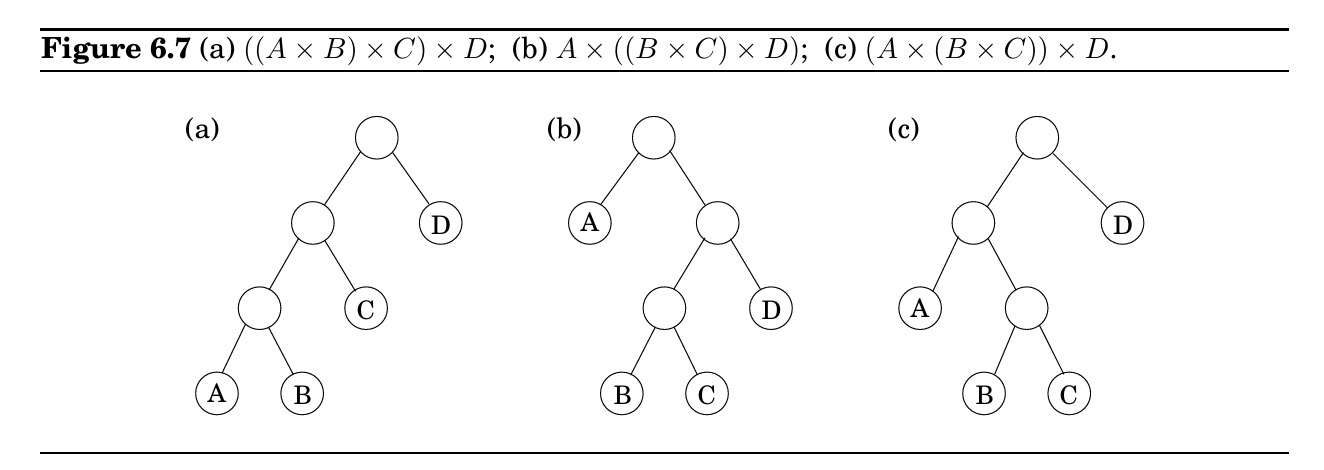
\text{pre(u) 由此,我们可以得出\(u,v\)的关系: 有向无环图(Directed acyclic graphs, dag for short)是指没有成环的简单图,可以将图简化为$v_0\rightarrow v_1\rightarrow \cdots\rightarrow v_n$ 一个有向图有环的充分必要条件是DFS找到了一条Back Edge。Dag 可用于表示层级结构,依赖关系等。Dag有诸多性质: 所以每个Dag中postorder最低的顶点是sink,将边方向反转,则可以求出source顶点 我们认为如果两个顶点\(u,v\)存在边从\(u\)到\(v\)和\(v\)到\(u\),我们称\(u,v\)是连接的(connected),可以组成一个Strongly Connected Component(SCC) 由此,我们可以将所有有向图转化为一个有向无环图。 该算法需要解决两个主要问题: 幸运的是,我们可以在线性时间内利用DFS将有向图转化为有向无环图,利用几个性质: 所以我们先对原图进行一次dfs,求postorder,然后遵循postorder从大到小遍历反向图。这样我们先会从原图的source scc出发,但是因为是反向图,所以source scc只有指向其自身的边,由此从最大postorder能遍历到的顶点即属于一个scc,依次从小到大,可以求出所有scc。因为该算法实际上是dfs重复多次,因此有线性\(O(V+E)\)的时间复杂度 见CS61B笔记,内容基本重合,此处不再赘述 算法逻辑CS61b也有讲述,此处强调Dijkstra算法分为两步,第一步是加入邻边,第二步是松弛priority queue中距离最小的顶点。一旦松弛了一个点后该点的距离一定是最小的,因为这个点已经是PQ中最小的点了,不会有别的更远的顶点加上边小于松弛的距离了。 而操作时间为: 所以时间最短为\( O((|V| + |E|) \log |V|) \) 这时,如果图不是无环图,则可能出现从一个顶点出发走过一个环回到原点的距离为负数的情况,这种时候没有最小距离,因为可以重复这个环无数遍得到一个负无穷大小。 而对于一个无环图,可以使用拓扑的方式(Bellman-Ford算法),CS61B有讲。 从高层次概括贪心算法就是找到该点的局部最优而不考虑全局,并且不使用暴力搜索的方式找到最优。贪心算法在一定情况下能找到最优解。本章将聚焦几个具体实现 输入一个加权图,通过那几条便即可找到成本最低的连接全部顶点的方式,可以用于降低网络延迟的网络链接等地方。 解决这个问题的贪心算法是Kruskal’s minimum spanning tree algorithm,该算法重复以下步骤: 树是无向图中的连接且无环的图形。正是因为这种简洁性使树十分强大。以下是树的一些性质: 割(Cut):假设边X是 证明: 边\(X\)是在MST上的一边,如果边\(e\)也是MST上的一边的话则直接成立,无需证明;
因为有\(w(e)\leq w(e'),\text{weight}(T')\leq \text{weight}(T)\),因为\(T\)是一个MST,所以两棵树一定都是MST。可见MST不一定是唯一的。 如上文所述,Kruskal算法的核心即是: 我们将图建模为并查集(Disjoint Sets)的集合,最开始所有node都是独立的组成 储存集合的一种方法使用有向树,树的节点是集合的元素,不存在固定顺序排列。根元素是该集合的一个便捷代表或名称(name)。它与其他元素的不同之处在于,它的父指针指向自身。 除了父指针\(\pi\),每个节点还具有一个性质rank,暂时代表在该点的子树(subtree)的高度 有如下性质: 对于任意\(x\),有$rank(x) 任何秩为\(k\)的根节点在其树中都至少有\(2^k\)个节点 证明: 对于 两个树融合时,设这两棵树都满足上述条件吗,有两种情况: 可见对于base case条件成立,推广至任何秩都成立 如果总共有$n\(个元素,最多有\)\frac{n}{2^k}\(个秩为\)k$的节点 有了上述数据结构,Kruskal算法的时间复杂度是对于每个边,找到这个边的两端端点在不在同一个树中,然后进行 这两种情况下数据结构会成为性能瓶颈,所以我们要寻找一种方法让时间复杂度优于\(\log{V}\)。此时,可以使用路径压缩,即每次调用 均摊成本(amortized cost) 在实际应用中,许多数据结构和算法在最坏情况下某个操作可能会花费较高的时间,但这种情况在连续的多个操作中并不频繁发生。均摊分析正是关注整个操作序列的总开销,然后将总开销均分到每一次操作上,得出“平均”成本。 并查集在不采用路径压缩等优化时,单次 Find 操作可能为 O(log n)(基于按秩合并)。但当引入路径压缩和其他优化后,均摊成本甚至能摊还到非常低的值,虽然单次操作的实际最坏成本可能较高,但经过均摊分析后,每次操作的平均成本变得十分低。 值得注意的是,路径压缩并不会改变一个节点和根的秩,此处的分析我还没看懂,暂时搁置,整体来说是Efficiency of a Good But Not Linear Set Union Algorithm这篇论文的思路,不知道有没有机会整理讲解出来。 见CS61B笔记 当在压缩一个文件的时候,该如何减少文件编码,比如一串由字母ABCD构成的字符,可以用00,01,10,11分别代表。“Can we do better?”,我们可以尝试用更小位的编码如0,1,01,11代表,但是我们就没有办法分清001是AC还是AAB了。 我们可以使用无前缀编码(prefix-free encoding)的一个特性——没有一个编码可以成为别的编码的前缀来实现这点 有\(n\(个字符的频率\)f_1,f_2\cdots f_n),可见这棵树的节点不是有两个子树就是叶子 断言:哈夫曼编码在前缀编码(即无歧义编码)的框架下,是针对给定符号概率分布平均码长最短的一种最优编码方案。 假设有$n\(个字符频率为\)f_1,f_2,\cdots f_n$,并且将除了根节点的值设为该点字符的频率。那么: 同时,我们可以将频率最小的两个兄弟节点\(f_1,f_2\)合并成一个“字符”,设合并前的哈夫曼树是\(T\),合并后是\(T'\),那么有
证明断言: Base case: 对于高度为1的树,必然是最优解 若\(T'\)是$\{(f_1+f_2),f_3,\cdots f_n\}\(最优解,那么将最小的节点拆为两个\)f_1,f_2\(节点,得到\)T$树,有: 设$\{f_1,f_2,f_3,\cdots f_n\}\(的最优树是\)T^*\(,合并后是\)T'^*$,有 两式相减得: 因为\(T^\*\)是最优树所以\(T\)是最优树,因为\(T'\)是最优树所以\(T'^\*\)是最优树 所以拆分完仍然为最优树,是最优编码。 参考哈夫曼树构造过程及最优证明_哈夫曼树证明构造,同时证明了哈夫曼树的展开和合并是互逆的。 对于这个赛马成绩,用哈夫曼编码来记录200次成绩,Aurora需要\(200\times 0.7\times 1 +200\times 0.15\times 2+ 200\times(0.05+0.10)\times 3=290\),Whirlwind需要380,Phantasm需要420,所以第一匹马有最短的编码,也更容易预测。所以 假设有$n\(个结果,分别是\)\{p_1,p_2,\cdots p_n\}\(,我们采样\)m\(次,第\)i\(种结果大概会出现\)mp_i\(次,为了简化,设\)p_i\(都是\)\frac 12$的幂。 则需要的总比特数是 信息熵为: 集合覆盖(Set Union)是有点集\(B\),集合$S_1,S_2,\cdots,S_n \subseteq B\(,问在完全覆盖点集\)B$的条件下选用集合个数最少的个数是多少的问题。 对于这个问题,贪婪的方法是选择覆盖没被选择过的点集中的点个数最多的集合\(S\),这个方法并不能给出完全理想的解法,但是能给出与理想解法\(k\)个集合数相差不远的解法,切确地说是不差于\(k\cdot \ln{n}\)个集合数 证明:令\(k\)是理想分配的集合个数,\(A_t\)是经过\(t\)次集合后的点集,共有\(n\)个点。 由于第\(k\)次选择后剩下点集\(A_t\)还可以选择\(k-t\)次,又因贪婪算法总是选择覆盖\(A_t\)最多点的集合,所以选择的集合一定大于\(\frac{1}{k-t}|A_t|\) 则\(A_0=n\),(|A_{t+1}|\leq(1-\frac{1}{k-t})|A_t|\leq (1-\frac{1}{k})|A_t|),便有: 又根据\(1-x\leq e^{-x}\)有 当\(|A_t|<1\)的时候即完全覆盖所有点集 $
n\cdot e^{-\frac tk}<1\\
\ln{n}-\frac tk <0\\
\ln{n}<\frac tk\\
k\ln{n} 动态规划有自顶向下(top-down)和自底向上(bottom-up)两种方法,主要适用于那些可以分解为重叠子问题和具有最优子结构的复杂问题。 自顶向下(top-down) 自顶向下是一种利用记忆体和递归的方法,先想出一个暴力搜索的递归方法,并且利用数据结构(如数组或者哈希表)储存子问题的结果,防止多次计算子问题 自底向上(bottom-up) 从最简单的子问题出发,逐步构造出大问题的解。这种方式通常通过循环结构实现,并且可能比递归更直观和高效。 **注意:**动态规划并不一定节约时间,而也可以节约空间 讲解递归的时候最经典的例子便是斐波那契数列。 但是这个算法具有$O(n^2)$的时间复杂度,非常不理想,稍微大点的输入都会计算很长的时间。那么我们可以使用什么方法来优化这个算法? 自顶向下 使用递归加上记忆体的方法。如果我们仔细观察这个函数,可以发现具有相当多的函数是被重复计算的,因此我们可以使用记忆体来优化算法,比如: 这样可以避免重复计算 自底向上 计算 给定一个序列$a_1,a_2,a_3\cdots ,a_n\(,一个子序列是\)a_{i_1},a_{i_2}\cdots ,a_{i_n}\(,其中\)i_1 例如,如果我们有数组 A = \(2, 8, 3, 4\),一种贪心策略是每次取下一个可能的元素。在这种情况下,我们会取到 \(2, 8\),之后就无法再取其他元素。但实际上最优解是 \(2, 3, 4\)。 首先来看一个暴力解法。我们可以定义 或者,我们可以先把数组 A 修改为: 这个递推关系是: 朴素的空间复杂度是$O(n^2)\(,但是因为每个栈帧只依赖于前一个栈帧,所以可以将空间复杂度优化到\)O(n)\(,但是时间复杂度依然是\)O(n^2)\(,因为我们仍然需要检验\)n^2$个值 这个问题和CS61A的hog project中的一个小问完全一样,但其实这是一个动态规划问题。对于两个单词,增加,减少和修改都会花费一次‘成本’。 遍历所有的可能来找最佳方案会极其费时,我们可以使用动态规划。 我们的目标是找到两个字符串 对于前缀问题,我们可以专注于最右侧的字符,总共只有三种情况: 第一种情况会为当前这一列带来 1 的代价,然后需要将 \(x[1 \cdots i - 1]\) 与 \(y[1 \cdots j]\) 对齐。但这恰好就是子问题 \(E(i - 1, j)\)!我们似乎正在逐步推进。 在第二种情况中,也需要代价 1,但这次我们需要将 \(x[1 \cdots i]\) 与 \(y[1 \cdots j - 1]\) 对齐。这同样又是另一个子问题 \(E(i, j - 1)\)。 而在最后一种情况中,代价为 1(如果 $x[i] \ne y[j]\()或 0(如果 \)x[i] = y[j]\(),此时剩下的就是子问题 \)E(i - 1, j - 1)$。 简而言之,我们将问题 \(E(i, j)\) 表达为三个更小的子问题: 但我们不知道哪一个才是“正确的”,因此我们需要三种都尝试一遍,并取最优的: 其中,为了简化表示,定义:
加上记忆体,我们有自顶向下的代码: 寻找合适的子问题往往需要创造力和反复试验。但在动态规划中,有一些标准的选择经常会被重复使用。 i. 输入是 $x_1, x_2, \ldots, x_n\(,一个子问题是 \)x_1, x_2, \ldots, x_i$。 因此,子问题的数量是线性的。 ii. 输入是 $x_1, \ldots, x_n\( 和 \)y_1, \ldots, y_m\(,一个子问题是 \)x_1, \ldots, x_i\( 和 \)y_1, \ldots, y_j$。 子问题的数量是 $O(mn)$。 iii. 输入是 $x_1, \ldots, x_n\(,一个子问题是 \)x_i, x_{i+1}, \ldots, x_j$。 子问题的数量是 $O(n^2)$。 iv. 输入是一个有根树。一个子问题是某个有根子树(rooted subtree)。 子问题的数量是$O(n)$ 背包问题(Knapsack)是指一个具有一定容量\(W\)的背包,面对具有重量$w_1,w_2,\cdots,w_n\(和价值\)v_1,v_2,\cdots,v_n$的物品,求如何用包装下最多价值的物品。 比如对于一个\(W=10\)的背包,有如下几种物品。 有两种版本的问题,第一种是每种物品有若干件可供选择,另一种是每种只有一件 但这是一个经典的\(P=NP\)问题,不是一个能于多项式时间内解决的问题。但是运用动态规划可以于$O(nW)\(,如果\)W\(相对较小的时候是一个较理想的时间,但是多项式时间是\)\log{W}\(,因为你只需要\)\log_2{W}$位来表示多项式时间。 像往常一样,动态规划中的主要问题是:子问题是什么?在这种情况下,我们可以通过两种方式缩小原问题规模:我们可以考虑较小的背包容量 \(w \leq W\),或者我们可以考虑更少的物品(例如,仅考虑第 \(1, 2, \ldots, j\) 个物品,其中 $j \leq n$)。通常需要一些实验才能准确找出什么方法有效。 第一个限制条件要求考虑较小的容量。因此,定义: 我们能用更小的子问题来表达它吗?如果 \(K(w)\) 的最优解包含第 \(i\) 个物品,那么从背包中移除这个物品会留下一个对 \(K(w - w_i)\) 的最优解。换句话说,\(K(w)\) 等于 \(K(w - w_i) + v_i\),对于某个 \(i\)。我们不知道是哪一个 \(i\),所以我们需要尝试所有的可能性: 就像往常一样,我们约定空集上的最大值是 0。算法已经自然地成型了,而且它一如既往地简洁而优雅。 需要维持一个长度为\(W+1\)的列表,每个都需要枚举$n\(个物品然后找到最大,所以需要\)n\(时间完成,所以时间复杂度是\)O(nW)$ 这可以类比成一个DAG,分析一下便可以发现这其实是构建一个DAG中最长的路径的类比算法。 在这种情况下有重复的背包问题没有用处,因为我们不知道你要选取的问题有没有被选取过,因此我们需要第二个参数$0\leq j\leq n$ 我们想找的答案便是$K(W,n)\(,我们应该如何拆分成小问题,这是一个比较简单的问题,要么第\)j$项物品在理想情况下被选上,要么不被选上: 我们需要填满一个二维矩阵,有\(W+1\)和$n+1\(列,矩阵每个格子都是常数时间复杂度,所以时间复杂度依然是\)O(nW)$ 对比自顶向下和自底向上两种方法,虽然自底向上可以大幅节约内存,但是在一些情况下自顶向下仍有其优势: 自底向上(Bottom-Up)DP 自顶向下(Top-Down)带备忘录 假设我们想要相乘四个矩阵 \(A \times B \times C \times D\),它们的维度分别为 \(50 \times 20\)、\(20 \times 1\)、\(1 \times 10\)、\(10 \times 100\)。这将涉及到反复地两两相乘。 又因矩阵乘法满足结合律不满足交换率,先计算哪个乘法会导致不同的计算开销。因此,我们可以通过不同的加括号方式,以多种方式来计算这四个矩阵的乘积。 那么,有些括号方式是否比其他的更好呢? 将一个 $m \times n\( 的矩阵乘以一个 \)n \times p\( 的矩阵,乘法次数为 \)mnp\((形成一个\)m\times p\(的矩阵,矩阵中每格都需要\)n$次乘法)。根据这个公式,我们比较以下几种不同的计算顺序来求: \(A \times B \times C \times D\) 正如你所看到的,乘法顺序对最终运行时间影响极大! 此外,自然的贪心策略(greedy approach)——总是选择当前最便宜的乘法来做,最终会导致第二种括号方式,而它是一个失败的选择(成本很高)。 我们如何确定最优顺序呢?假如我们希望计算 $A_1 \times A_2 \times \cdots \times A_n\(,其中每个 \)A_i$ 的维度分别是: $m_0 \times m_1, \quad m_1 \times m_2, \quad \ldots, \quad m_{n-1} \times m_n$ 我们首先要注意的一点是:一个特定的加括号方式可以很自然地表示为一棵二叉树,其中每个矩阵对应一个叶子节点,而根节点是最终的乘积结果。 在乘法树中,内部节点是中间乘积(如图6.7所示)。矩阵乘法顺序的所有可能情况,对应于具有 $n$ 个叶子节点的所有满二叉树,其数量是指数级的。我们显然不能暴力枚举每棵树,因此我们转而使用动态规划。 图6.7中的二叉树提示了一个思路:若一棵树是最优的,那么它的子树也必须是最优的。那我们如何定义子问题?子问题就是形如: 的乘积。我们定义: 子问题的规模是矩阵乘法的数量,即 \(|j - i|\)。当 \(i = j\) 时,表示只剩一个矩阵,无需相乘,因此: 对于 \(j > i\) 的情况,考虑如何构造最优子树。第一层的拆分会将乘积分为两个部分: 代价就是这两个子区间的最小乘法代价加上合并这两个结果的代价: 伪代码,其中变量 \(s\) 表示子问题的区间大小: 这些子问题构成了一个二维表格,每个表项的填充需要 $O(n)$ 时间,总的运行时间是: 对于图论中的负权重图的讨论的时候,可以用拓扑排序,这其实也是一种DP。 我们来尝试推导 Bellman-Ford 算法。这个算法会使用和我们为 DAG(有向无环图)使用的算法类似的思路:必须存在某条终边 \(u \to v\),所以我们会枚举所有进入 \(v\) 的边。但我们不能使用和 DAG 相同的递推式,否则会陷入无限递归。这意味着我们需要某种机制来避免这种情况。 假设我们处理的是没有负权环的图。我们知道,从 \(s\) 到 \(t\) 的任意最短路径最多只能包含 $n-1\( 条边;任何超过 \)n-1$ 条边的路径一定包含环。我们将利用这个事实以及前述观察来设计算法。 我们定义函数: 我们最终想要求的是 $f(t, n - 1)$。其递推关系为: 在递归的情况下,我们有两个选择:可以不使用任何当前的边(即继承 \(f(t, k-1)\)),或者我们可以枚举所有可能进入 \(t\) 的边,遍历它,并将边权加到 \(f(v, k-1)\) 上。所有这些情况中的最小值就是最优解。 从朴素角度来看,所需的内存是 $O(n^2)\(,因为 \)t\( 和 \)k\( 都会变化,每个都有 \)n\( 个可能的取值。我们可以通过观察 \)f(\cdot, k)\( 只依赖于 \)f(\cdot, k-1)\( 的值来优化内存:只需保留当前和上一轮的值,这样内存需求降为 \)O(n)$。 那么运行时间呢? 令 $\deg_{in}(t)\( 表示 \)t\( 的入度,总的工作量就是遍历所有边,即 \)\sum_{t \in V} \deg_{in}(t) = m$。 因此,总运行时间为: 那么我们要怎么检测负权环呢,我们断言当且仅当存在一个顶点\(v\)使得$f(v,n) 证明: 充分条件($\exist v \Rightarrow \exist \text{neg cycle}\():我们没有理由在最短路径中使用超过 \)n-1$ 条边,因为那样必然会重复经过某条边,而唯一从中获益的情况是存在一个负权环。 必要条件($\exist \text{neg cycle} \Rightarrow \exist v\():我们证明这个问题的逆命题,即\)\forall v,f(v,n)\geq f(v,n-1)\Rightarrow \forall \text{cycle C,} w(C)\geq 0$。 我们假定一个环\(C=v_1\rightarrow v_2\rightarrow \cdots\rightarrow v_r\rightarrow v_1\),我们知道对于所有 \(i\),有
$f(\nu_{i+1}, n-1) \le f(\nu_{i+1}, n)$。我们知道 这意味着 于是我们对整个环求和: 左边的求和中,每个 $f(\nu_i, n-1)\( 被恰好加一次又减一次,全部抵消掉,左边为 0,右边即为环 \)C\( 的总权重 \)w(C)$。 因此:
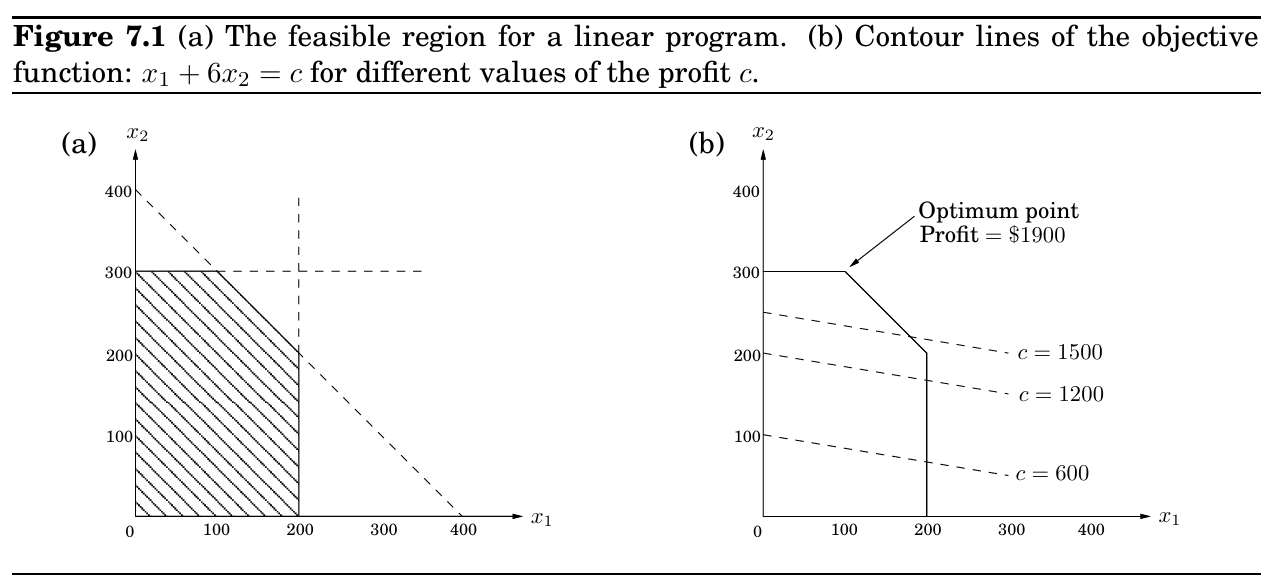
\(0 \le w(C)\quad\square\) 在线性规划问题中,我们给定一组变量,并希望为这些变量分配实数值,以便 比如一下这个例子: 一家精品巧克力店有两种产品:其主打的三角形巧克力系列,名为Pyramide,以及更奢华的Pyramide Nuit。为了最大化利润,它应该生产多少盒每种产品?假设它每天生产 \(x_1\) 盒 Pyramide,每盒利润为 \(1;以及 \)x_2\( 盒 Nuit,每盒利润更高,为 \)6;\(x_1\) 和 \(x_2\) 是我们希望确定的未知值。但这还不是全部;还有一些约束条件需要满足(除了显而易见的 \(x_1, x_2 \geq 0\))。首先,这些独家巧克力的日需求量最多为200盒 Pyramide 和300盒 Nuit。此外,当前的劳动力每天最多可以生产400盒巧克力。最优的生产水平是多少? 我们可以用一个线性规划来表示这种情况,如下所示。 目标函数 约束条件 在 \(x_1\) 和 \(x_2\) 中的一个线性方程定义了二维平面上的一条直线,而一个线性不等式则指定了一半空间,即直线一侧的区域。因此,这个线性规划的所有可行解集,即满足所有约束条件的点 \((x_1, x_2)\),是五个半空间的交集。这是一个凸多边形,如图7.1所示。 我们要在这个多边形中找到使目标函数——利润——最大化的点。利润为 \(c\) 美元的点位于直线 \(x_1 + 6x_2 = c\) 上,该直线的斜率为 \(-1/6\),并在图7.1中以选定的 \(c\) 值显示。随着 \(c\) 的增加,这条“利润线”平行于自身向上并向右移动。由于目标是最大化 \(c\),我们必须移动我们需要将这条线尽可能地向上移动,同时仍然触及可行区域。最优解将是利润线看到的最后一个可行点,因此必须是多边形的一个顶点,如图所示。如果利润线的斜率不同,则其与多边形的最后一次接触可能是一整条边而不是一个单一的顶点。在这种情况下,最优解将不是唯一的,但肯定存在一个最优顶点。 线性规划的一般规则是,最优解在可行区域的顶点处达到。唯一的例外是没有最优解的情况;这可以通过两种方式发生: 线性规划是不可行的;也就是说,约束条件如此严格以至于不可能满足所有约束。例如, 约束条件如此宽松以至于可行区域是无界的,并且可以实现任意高的目标函数值。例如, 线性规划可以用Simplex算法解决,其思路是从一个顶点开始,比如\((0,0)\),然后沿着多边形顶点寻找有更优的数值的顶点。当没有一个更好的邻居的时候,单纯形法(Simplex)宣布其为最优解并停止。为什么这种局部测试意味着全局最优性?对于一个凸多边形(即所有角都小于180°),想象一下穿过这个顶点的利润线。由于所有顶点的邻居都位于这条线之下,因此可行多边形的其余部分也必须位于这条线之下。 单纯形法主要求解两个问题: 正如我们将看到的,如果最优解所在的顶点刚好在原点,那么两个任务都很容易解决。如果顶点不在原点,我们可以通过变换坐标系将其移动到原点! 首先,让我们看看为什么原点如此方便。假设我们有一个通用的线性规划问题: 其中,\(x\) 是变量向量,即 $x = (x_1, \ldots, x_n)\(。假设原点是可行解,那么它就是一个顶点,因为它是唯一满足 \)n\( 个不等式 \)\{x_1 \geq 0, \ldots, x_n \geq 0\}$ 成为等式(tight)的点。 现在我们来解决两个任务中的第一个: 任务1:
当且仅当所有的 \(c_i \leq 0\) 时,原点是最优解;如果所有的 \(c_i \leq 0\),那么考虑到约束 \(x \geq 0\),我们就无法得到更好的目标值。
相反,如果存在某个 \(c_i > 0\),那么原点就不是最优的,因为我们可以通过增加 \(x_i\) 来提高目标函数的值。 因此,对于任务2,我们可以通过增加某个使 \(c_i > 0\) 的变量 \(x_i\) 来移动。那能增加多少呢?直到遇到另一个约束。
也就是说,我们释放原本紧绑定的约束 \(x_i \geq 0\),不断增加 \(x_i\),直到遇到另一个不等式来约束\(x_i\)。
在那个时刻,我们又恰好有 $n$ 个紧绑定的约束,因此我们到了一个新的顶点。
约束条件是: Simplex方法可以从原点开始,因为原点满足约束④和⑤。为了移动,我们释放紧绑定的约束 \(x_2 \geq 0\)。
随着 \(x_2\) 逐渐增加,第一个遇到的新约束是 \(-x_1 + x_2 \leq 3\),因此必须在 \(x_2 = 3\) 停止,此时这个新的约束被紧绑定。
因此新的顶点由约束③和④确定。也就是说有\(m\)个方程确定的具有$n\(个变量的LP问题可以有\)C_m^n$个顶点。 所以,当我们位于原点时,知道该如何操作了。但如果当前顶点 \(u\) 不在原点呢? 我的第一想法是移动一个\(c>0\)的不等式,然后将其他不等式固定,这样便可以保证增加,但是你并不知道这个顶点成不成立。比如你在\(x_1=200,x_2=200\)这个顶点,满足\(x_1+x_2\leq 400,x_1\leq 200\)这两个方程,是紧约束,下一步有可能选择\(x_2\leq300\)这个不等式,因为会使总数增大,但是这样却违反了\(x_1+x_2\leq400\)这个不等式。 这里的技巧是将 \(u\) 平移到原点,即将坐标系从通常的 $(x_1, \dots, x_n)\( 转换到以 \)u$ 为参考的“局部视角”。
这种局部坐标由 $n\( 个超平面(即定义并包围 \)u\( 的不等式)到 \)u\( 的(适当缩放后的)距离 \)y_1, \dots, y_n$ 组成。 更具体地说,如果某个包围当前顶点的约束是 \(\mathbf{a}_i \cdot \mathbf{x} \leq b_i\),那么点 \(\mathbf{x}\) 到该“墙面”的距离为: 这些墙面对应的 $n\( 条方程,将 \)y_i\( 表达为 \)x_i$ 的线性函数。
反过来,我们也可以将 \(x_i\) 表达为 \(y_i\) 的线性函数。
因此,我们可以用 \(y\) 来重新描述整个线性规划问题。
这不会从根本上改变问题(例如最优值仍然不变),但它在一个不同的坐标系下表达了同一个问题。
调整后的“局部”线性规划具有以下三个特性: 包含了不等式 \(y \geq 0\),这些就是定义原点 \(u\) 的不等式经过变换后的版本。 顶点 \(u\) 在新的 \(y\)-空间中就是原点。 目标函数变为
其中 \(c_u\) 是在 \(u\) 点目标函数的值,\(\tilde{c}\) 是变换后的代价向量。 简而言之,我们又回到了我们熟悉的情况! 归约 有时一个计算任务足够通用,以至于任何子程序都可以用来解决各种其他任务,这些任务乍一看可能似乎不相关。例如,在第6章中,我们看到如何使用一种算法来寻找有向无环图(DAG)中的最长路径,令人惊讶的是,这种算法也可以用于寻找最长递增子序列。我们通过说最长递增子序列问题可以归约为DAG中的最长路径问题来描述这一现象。反过来,DAG中的最长路径可以归约为DAG中的最短路径;以下是如何使用后者的子程序来解决前者: 让我们退一步,从稍微正式的角度来看待归约。如果任何用于任务Q的子程序也可以用来解决P,我们说P可以归约为Q。通常,P可以通过单次调用Q的子程序来解决,这意味着P的任何实例x可以转换为Q的一个实例y,使得可以从Q(y)推导出P(x): (你是否注意到从P = 最长路径到Q = 最短路径的归约遵循这个模式?)如果预处理和后处理过程是高效可计算的,那么这将基于Q的任何有效算法创建一个有效的P算法! 归约增强了算法的能力:一旦我们有了一个问题Q的算法(例如最短路径),我们可以用它来解决其他问题。事实上,我们在本书中研究的大多数计算任务都被认为是计算机科学的核心问题,正是因为它们出现在如此多不同的应用中,换句话说,许多问题都可以归约到它们。线性规划尤其如此。 正如我们的例子所示,一个一般的线性规划问题有许多自由度。 我们现在将展示这些各种LP选项可以通过简单的变换相互归约。以下是具体方法: 将最大化问题转换为最小化问题(反之亦然),只需将目标函数的系数乘以 \(-1\)。 第二种情况可以分为两种形式 将一个不等式约束如 $\sum_{i=1}^{n} a_i x_i \leq b\( 转换为等式,引入一个新的变量 \)s$ 并使用 这个 \(s\) 称为不等式的松弛变量。作为证明,观察到向量 $(x_1, \ldots, x_n)\( 满足原始不等式约束当且仅当存在某个 \)s \geq 0$ 使得它满足新的等式约束。 最后,处理一个符号不受限制的变量 \(x\),按照以下步骤进行: 这样,\(x\) 可以通过适当地调整新变量来取任何实数值。更精确地说,涉及 \(x\) 的原始LP的任何可行解都可以映射到涉及 \(x^+, x^-\) 的新LP的可行解,反之亦然。 矩阵-向量表示法 像 \(x_1 + 6x_2\) 这样的线性函数可以写成两个向量的点积: 记作 \(\mathbf{c} \cdot \mathbf{x}\) 或 \(\mathbf{c}^T \mathbf{x}\)。类似地,线性约束可以编译成矩阵-向量形式: 这里矩阵 \(\mathbf{A}\) 的每一行对应一个约束:它与 \(\mathbf{x}\) 的点积最多为 \(\mathbf{b}\) 中相应行的值。换句话说,如果 \(\mathbf{A}\) 的行是向量 \(\mathbf{a}_1, \ldots, \mathbf{a}_m\),那么 \(\mathbf{Ax} \leq \mathbf{b}\) 等价于 有了这些表示上的便利,一般的线性规划(LP)可以简单地表示为
线性规划有诸多应用,如规划网络流量,节省费用及分配学生教师等。 我们处理的网络由一个有向图 \(G = (V, E)\) 组成;两个特殊节点 $s, t \in V\(,分别是 \)G$ 的源(source)和汇(sink);以及边上的容量 \(c_e > 0\)。 我们希望从 \(s\) 到 \(t\) 发送尽可能多的油而不超过任何边的容量。一种特定的运输方案称为流,并且由网络中每条边 \(e\) 的一个变量 \(f_e\) 组成,满足以下两个属性: 它不违反边容量:对于所有 $e \in E\(,有 \)0 \leq f_e \leq c_e$。 对于除了 \(s\) 和 \(t\) 之外的所有节点 \(u\),进入 \(u\) 的流量等于离开 \(u\) 的流量:
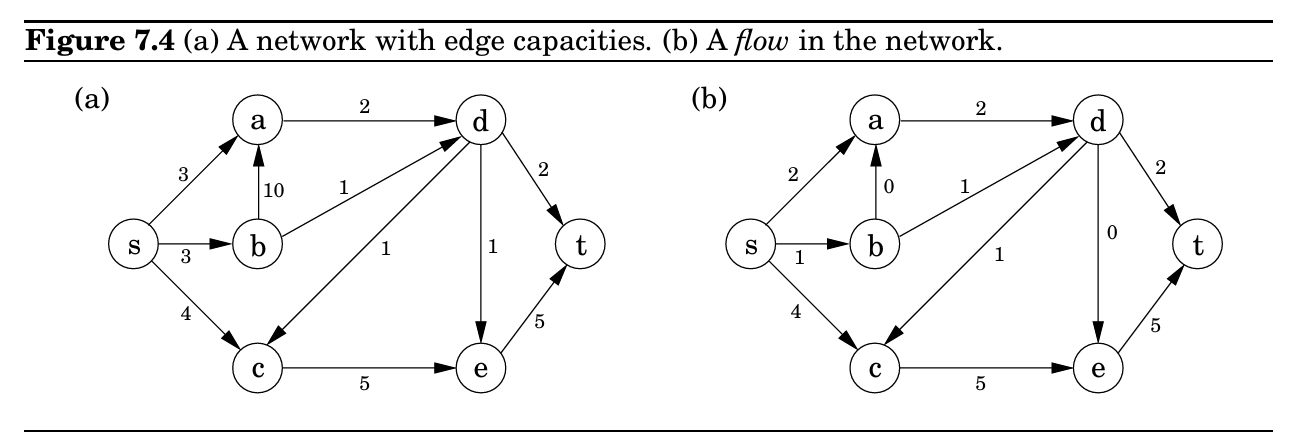
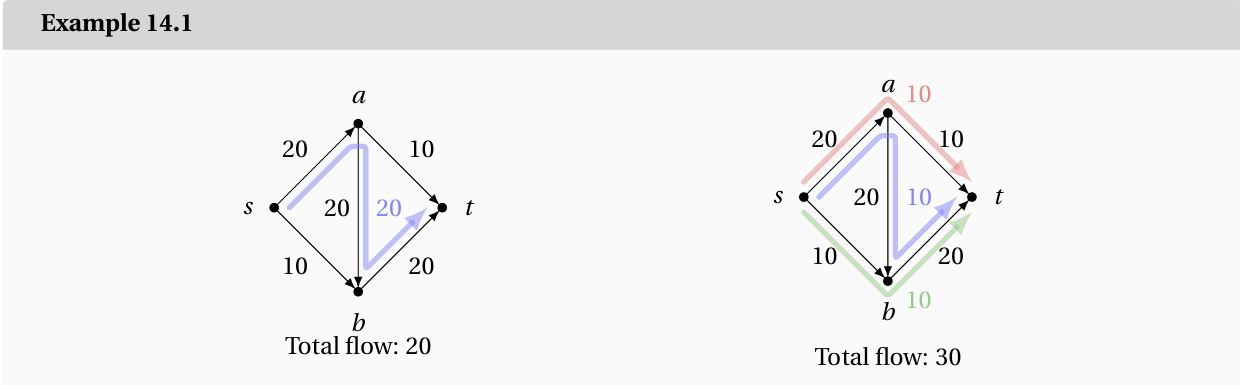
换句话说,流是守恒的。 流的大小是从 \(s\) 到 \(t\) 发送的总数量,并且根据守恒原则,等于离开 \(s\) 的数量: 简而言之,我们的目标是为 $\{f_e : e \in E\}$ 赋值,以满足一组线性约束并最大化一个线性目标函数。但这正是一个线性规划问题!最大流问题可以归约为线性规划。 例如,对于图7.4中的网络,LP有11个边,每个边一个变量。它试图在总共27个约束下最大化 \(f_{sa} + f_{sb} + f_{sc}\):11个用于非负性(如 \(f_{sa} \geq 0\)),11个用于容量(如 \(f_{sa} \leq 3\)),以及5个用于流守恒(每个除 \(s\) 和 \(t\) 之外的图节点一个,如 \(f_{sc} + f_{dc} = f_{ce}\))。单纯形法将毫不费力地正确解决这个问题,并确认在我们的例子中,大小为7的流确实是最佳的。 对于这个问题,我们可以使用一个直观上不太明显的算法——Ford-Fulkerson算法 在呈现Ford-Fulkerson算法之前,我们先使用朴素的贪心算法尝试构建,对于如下的一个图,我们可以尝试使用DFS,找到一个从源到汇的路径。找到之后将这个路径的每一条边减去这条路径上能通过的最大权重,否则可能多次计算,然后多次重复直到没有边从源到汇。 但是这样实际上是不行的,比如左图,可以发现如果第一次选择了这个路线并去除了所有路线上的边后这个图就没有连通性了,得到了20的总流量,但是如右图,实际上这个图可以实现总共20的总流量。因此Ford-Fulkerson改进了这个算法。 第一个伪多项式时间的最大流算法是由 Ford-Fulkerson 在1950年代构建的。 使用 Ford-Fulkerson 算法时,我们会假装对于每条边 \(e\),反向边 \(\text{rev}(e)\) 也存在于图中,且初始容量为0。然后,如果在 \(e\) 上有 \(f_e\) 的流量,我们会假装在反向边上存在 \(-f_e\) 的流量。这样,就允许我们“撤销”之前在正向边上做出的流动操作。 举个例子,在之前的例子中,如果我们没有完全断开图,而是保留了剩余容量为20的反向边,那么如果我们沿着反向边路由更多的流量,实际上就是减少了之前已有的流量。我们将这些残量图中的 \(s\)-\(t\) 路径称为增广路径(augmenting paths)。 因此,Ford-Fulkerson 本质上就是一个贪心算法,但加上了这些额外规则:不断寻找增广路径,直到再也找不到为止。 Ford-Fulkerson的时间复杂度是多少呢? 假定所有容量都是整数(无理数边会复杂些),那么所有残量图中的容量也都会是整数(因为瓶颈边的容量都是整数)。我们进一步知道,在每一次迭代中,瓶颈边的容量至少为1,因此每次至少可以推进1单位的流量。这意味着我们最多需要的迭代次数不会超过最大流量的数值。因此,算法的运行时间是 其中 \(\text{val}(f^\*)\) 是最大流的数值。换句话说,流量的最大可能值是源点流出的总容量;如果源点流出边中容量最大的边容量是 \(U\),那么源点最大流出的总流量就是 $(n-1)U$,因此运行时间为 那么,我们怎么知道这个略显奇怪的算法是正确的呢? 最大流-最小割定理(Max-flow Min-cut Theorem):\(\text{val}(f^\*)=u(S^\*)\) ,一个最大流 \(f^\*\) 的流量值 \(\text{val}(f^\*)\)。这个值等于最小割的容量 \(u(S^\*)\)。其中 \(f^\*\) 是最大 \(s \rightarrow t\) 流,\(S^\*\) 是最小的 \(s - t\) 割。\(\text{val}(f^\*)\) 是流的值,\(u(\cdot)\) 表示割的容量。 其中\(s\to t\)割是指一个割,其$s\in S\(且\)t\in T$,其容量如此表述:
即我们计算所有跨过这条割的边的权重。对于这个\(s\to t\)割,我们可以定义一个\(f(S)\)流:
即我们加上所有从\(S\)流向\(T\)的边并减去\(T\)流向\(S\) 对于所有 \(s \rightarrow t\) 割集 \(S\),都有 \(f(S) = \text{val}(f)\)。(其中 \(f\) 是函数 \(f(S)\) 中的流,\(\text{val}(f)\) 是该流的总值。) 证明。
我们对集合大小 \(|S|\) 进行归纳。 基本情况是 \(|S| = 1\),此时 \(S = \{s\}\)。
此时的净流 \(f(\{s\}) = f\),这正是 \(\text{val}(f)\) 的定义。 在归纳步骤中,我们现在有 \(|S| > 1\)。
这意味着在 \(S\) 中至少有两个顶点 \(s\) 和 \(v\)。
如果我们将 \(v\) 从 \(S\) 移动到 \(T\) 中(即从割的一边移到另一边),那么根据归纳假设,新的割集对应的净流值等于流的总值;
我们将证明:如果我们将 \(v\) 再移回来,那么流的值仍保持不变,整个 \(S\) 的净流也仍然保持不变。 如果我们观察与顶点 \(v\) 相连的边,会有四种情况: (图示:s 位于 S 内,v 与 S、T 两侧连通,分别表示流量 A、B、C、D) 我们知道,根据流量守恒:
此外,如果我们看 $f(S \setminus \{v\})\(,等于 “stuff + A - B”,其中 “stuff” 表示所有不包含 \)v$ 的部分的流;
而 \(f(S) = \text{stuff} + C - D\) 因此这两个流必须相等,因为 “stuff” 是一样的,而剩下的部分 \(A - B = C - D\) 也一样,这是由流量守恒保证的。 证毕。□ 我们想证明最大流-最小割定理,即\(\text{val}(f^\*)=u(S^\*)\),我们用两个不等式来约束:
接下来证明\(\text{val}(f^∗) ≥ u(S^∗)\):设 \(f\) 是一个最大流,并定义集合:
残余图(\(G_f\))是在给定流 \(f\) 的网络流模型下,用来表示“还可以增广多少流”以及“可以退回多少流”的辅助图。它的作用是帮助我们在残余网络中寻找增广路径,从而不断增大流量直到达到最大流。S可以用在运行可能多次DFS并逆转流大小的边后可以由源到达的顶点。 残留容量的含义 我们声称,流 \(f\) 的值正好等于这个割集的容量。 在这里可以看到,如果按照上述方式取 \(s-t\) 割,将会有流量从 \(S\) 流向 \(T\),以及从 \(T\) 流向 \(S\)。 根据之前的引理,\(\text{val}(f) = f(S)\)。结合上面的观察,我们可以得出: 理解上文中\(S = \{ v : \text{从 } s \text{ 出发在剩余图 } G_f \text{ 中可以到达 } v \}\)的定义即残留容量的含义既可以理解Ford-Fulkerson算法反复加减边的含义了。 我们已经看到,在网络中流量总是不超过割的容量,但最大流和最小割恰好相等,于是它们互为对方最优性的证明。虽然这一现象非常妙,我们现在将它推广到任何可以用线性规划解决的问题!事实证明,每一个线性最大化问题都有一个对偶的最小化问题,并且它们之间的关系正如流与割那样一一对应。 要理解对偶性的含义,先回忆我们关于两种巧克力的入门 LP: 单纯形法给出的最优解是 此时目标函数值为
有没有办法验证这个答案的正确性?不妨试试将约束作线性组合: 第一步:取第一条不等式,加上第二条不等式的 6 倍,得到 \(x_1+6x_2 ≤ 200+6⋅300 = 2000\).这说明利润不可能超过 2000。 第二步:进一步尝试其他组合。经过实验,我们发现将三条不等式分别乘以 0、5、1 后相加,正好给出 \(0⋅(x_1≤200) + 5⋅(x_2≤300) + 1⋅(x_1+x_2≤400)⟹x_1+6x_2 ≤ 1900.\) 于是我们得到一个更紧的上界 1900,恰好等于单纯形给出的最优值。 因此 1900 必然是该 LP 的最优值!系数 \((0,5,1)\) 奇妙地构成了一个最优性证明(certificate)。令人惊奇的是,这样的证明不仅存在,还能被系统地寻找——这就是线性规划对偶理论的核心。 让我们通过描述对这三个乘子(记作 \(y_1,y_2,y_3\))的期望来探讨这一问题。 首先,这些 \(y_i\) 必须是非负的,否则无法将不等式乘以它们(乘以负数会把“\(\le\)”翻成“\(\ge\)”)。在完成乘法并相加后,我们得到:
我们希望左边刚好是目标函数 \(x_1 + 6x_2\) 的形式,这样右边就成了对最优值的一个上界。 要让左边等价于 \(x_1 + 6x_2\),需要 \(y1+y3=1,y2+y3=6.y_1 + y_3 = 1, \quad y_2 + y_3 = 6.\) 事实上,如果 \(y_1+y_3\) 或 \(y_2+y_3\) 大于上述值,也不会出问题,只会得到更松的上界。 因此,只要满足 就有上界
我们可以很容易地通过取很大的 \(y\) 来使这些不等式成立,例如 \((y_1,y_2,y_3)=(5,3,6)\),此时上界是 显然太松,不够有意义。我们希望上界尽可能紧,就应当在上述约束下最小化右边的表达式: 这便是一个新的线性规划,对原问题的对偶问题进行了构造。 按照设计,任何这个对偶 LP(dual LP)的可行解所对应的值,都是原始原始 LP(primal LP)的一个上界。
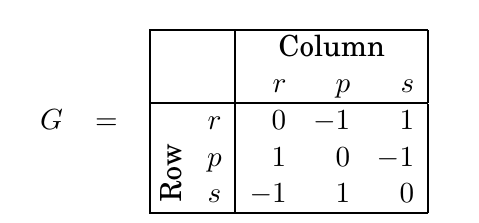
因此,如果我们找到了一个原始问题和对偶问题的可行解对,并且它们的目标函数值相等,那么这两个解就都是最优解。 下面就是这样的一对解: 它们的目标函数值都等于 1900,因此它们互为彼此最优性的证明。 在对偶问题中,对原始问题的每一个变量引入一个对偶变量,并要求其加权和大于等于该原始变量的目标系数。而优化对偶变量乘以原始右侧常数 \(b\) 的加权和——这种转换方式对任何线性规划问题都适用,如图 7.10 所示,甚至可以推广到图 7.11 中更一般的形式。 第二张图增加了一个值得注意的细节:如果原始问题中某个约束是等式约束,那么对应的乘子(即对偶变量)不需要非负,因为当等式两边乘以负数时,不等式方向不会被破坏。所以,对等式约束的乘子可以是任意实数。 还要注意原始和对偶之间的对称结构:矩阵 \(A = (a_{ij})\) 中的每一行对应一个原始约束,每一列对应一个对偶约束。 由于构造方式所决定,对偶问题的任何可行解都提供了原始问题可行解的一个上界。更重要的是: 对偶性定理(Duality Theorem) 当原始问题是最大流问题时,我们可以将对偶变量赋予特定的含义,表明其对偶实际上就是最小割问题。因此,最大流与最小割的关系只是对偶性定理在该问题下的一个特例。 事实上,对偶性定理的证明正是基于单纯形算法推导而来,就像最大流-最小割定理是从最大流算法的分析中“自然而然地掉出来”的一样。 我们可以用**矩阵博弈(matrix games)来表示生活中的各种冲突情境。例如,学校里玩的“石头剪刀布”游戏就由如下所示的收益矩阵(payoff matrix)**来指定。这里有两个玩家,称为行玩家(Row)和列玩家(Column),他们可以从集合 \(\{r, p, s\}\) 中选择一个动作。然后他们查找对应的矩阵项,Column 会支付该项的数值作为代价,也就是 Row 的收益、Column 的损失。 现在假设他们重复进行这个游戏。如果 Row 总是选择相同的动作,Column 很快就能察觉并始终选择相克的动作,从而每次都获胜。因此,Row 应该做些变换:我们可以通过让 Row 使用**混合策略(mixed strategy)**来建模,也就是她以概率 \(x_1\) 选择 \(r\),以概率 \(x_2\) 选择 \(p\),以概率 \(x_3\) 选择 \(s\)。这个策略由向量 \(x = (x_1, x_2, x_3)\) 指定,要求是三个正数之和为 1。同样地,Column 的混合策略是 \(y = (y_1, y_2, y_3)\)。 在游戏的某一轮中,Row 和 Column 分别以 \(x_i\) 和 \(y_j\) 的概率选出第 \(i\) 行和第 \(j\) 列的动作。因此,期望收益(平均收益)为: Row 想要最大化这个值,而 Column 想要最小化它。那么他们能在石头剪刀布中获得什么样的期望收益呢?例如,假设 Row 采用“完全随机”的策略 \(x = (1/3, 1/3, 1/3)\)。如果 Column 选择 \(r\),那么平均收益(即读取矩阵的第一列)为: 如果 Column 选择 \(p\) 或 \(s\),结果也是一样。而且任何混合策略 \((y_1, y_2, y_3)\) 的收益也只是对 \(r\)、\(p\)、\(s\) 的收益的加权平均,所以它也必须为 0。我们可以从前面的公式中看到这一点: 其中第二个等式来自这样的观察:矩阵 \(G\) 的每一列的元素之和都是 0。 因此,通过采用“完全随机”策略,Row 可以迫使期望收益变为 0——无论 Column 做什么。也就是说,Column 无法获得一个负收益(对自己有利的结果)。 回忆一下,Column 想让收益尽可能小。但是,对称地,如果 Column 采用完全随机的策略,他也能迫使期望收益为零,因此 Row 也不能获得正的(期望)收益。简而言之,最好的策略就是完全随机地玩游戏,期望收益为 0。我们已经数学上验证了你对“石头剪刀布”的直觉认知! 我们用另一种方式来看待这个问题,考虑两个场景: 我们已经看到,如果双方都最优地博弈,两个情形下的平均收益都是 0。但这可能是因为“石头剪刀布”具有高度对称性。在一般博弈中,我们会预期第一种选择(Row 先动)对 Column 更有利,因为他知道 Row 的策略,并可以充分利用它再选择自己的策略。同理,我们也会预期第二种选择对 Row 更有利。但令人惊讶的是:如果双方都采用最优策略,那么提前宣布策略对玩家并没有坏处!更妙的是,这一奇特的性质是线性规划对偶性(linear programming duality)的一种结果和等价表述。 让我们研究一个非对称博弈(nonsymmetric game)。设想一个**总统选举(presidential election)**的场景,两个候选人可以选择聚焦的竞选议题(字母代表 economy, society, morality, tax cut)。收益矩阵中的是 Column 候选人失去的百万选票数。 假设 Row 宣布她将采用混合策略 \(x = (1/2, 1/2)\)。Column 应该怎么应对?如果他选择 \(m\),他将遭受期望损失 \(1/2\);而如果选择 \(t\),他将遭受期望损失 0。因此,Column 最好的应对策略是纯策略 \(y = (0, 1)\)。 更一般地,一旦 Row 的策略 \(x = (x_1, x_2)\) 固定,总存在一个对 Column 最优的纯策略:要么选择 \(m\),其收益为 \(3x_1 - 2x_2\),要么选择 \(t\),其收益为 \(-x_1 + x_2\),二者取其小。因为任何混合策略 \(y\) 都只是这两个纯策略的加权平均,所以无法优于这两个中的最优者。 因此,如果 Row 被迫在 Column 之前宣布 \(x\),她知道他最好的应对方式将导致期望收益为: 她应选择能使这个最小值最大的 \(x\),即: 这是在 Column 的最优应对下 Row 所能获得的最大保障收益(best expected payoff)。 这个 \(x\) 的选择给予 Row 对她期望收益的最大保障(guarantee),而且我们很快就会看到它可以通过线性规划(LP)来求解!关键在于注意到对于固定的 \(x_1\) 和 \(x_2\),满足一下方程: Row 需要选择 \(x_1\) 和 \(x_2\) 以最大化 \(z\)。 这个问题可写为线性规划的标准形式: 对称地,如果 Column 必须先宣布他的策略,他最好的选择就是选择一个混合策略 \(y\) 来最小化在 Row 的最优应对下的损失。换句话说: 选择 \((y_1, y_2)\) 以最小化: 这是 Row 对于 \(y\) 的最优应对产生的结果。 将此写为线性规划形式: 关键的观察点是:这两个线性规划是对偶的(dual)!(参见图 7.11)因此,它们有相同的最优值,记作 \(V\)。 让我们总结一下。通过求解线性规划,Row(最大化者)可以确定一种策略,使得不论 Column 做什么,她都能确保至少获得 \(V\) 的期望收益。而 Column(最小化者)通过对偶线性规划,可以确保无论 Row 做什么,他的期望损失最多是 \(V\)。这意味着 \(V\) 是唯一确定的最优值(optimal value):事前并不能确定这个值是否存在。\(V\) 被称为该博弈的值(value of the game)。在我们的例子中,它是 \(1/7\),当 Row 使用最优混合策略 \((3/7, 4/7)\),Column 使用最优混合策略 \((2/7, 5/7)\) 时实现。 这个例子可以很容易地推广到任意规模的博弈,表明双方都可以采用混合策略,从而实现相同的值——这是博弈论中的一个基本结论,称为极小极大定理(min-max theorem)。它可以表示为: 令人惊讶的是,左边这一项中 Row 要先宣布策略,表面上看对 Column 更有利;而右边这一项中则是 Column 要先出牌。对偶性使两者值相等,正如最大流与最小割定理那样。
有向无环图
Strongly Connected Component
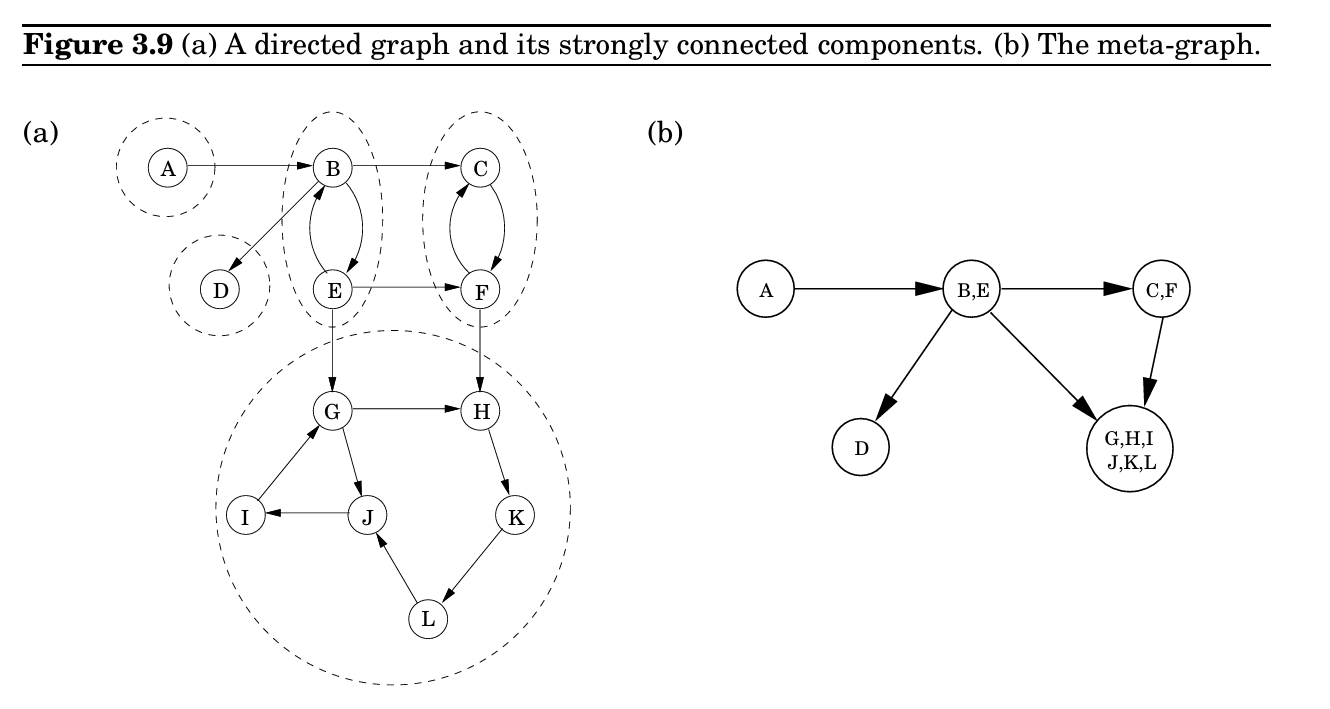
转化算法(Kosaraju)
Path in Graph
BST
Dijkstra algorithm
1
2
3
4
5
6
7
8
9
Q = MakeQ(V, dist)
while Q not empty:
u = DeleteMin(Q) // get closest node
for all edges(u, v):
if Dist[v] > Dist[u] + length(u, v):
// find short path to v via u
Dist[v] = Dist[u] + length(u, v)
Prev[v] = u // record new path to u
DecreaseDist(Q, Dist[v]) // record new dist for v
由负权重边时
贪心算法
Minimum Spanning Tree
mst G=(V,E)的一部分,选择节点S的任意子集,使边X不跨过S和V-S,并且令e是跨过这部分的最小边,那么\(X\cup \{e\}\)是MST的一部分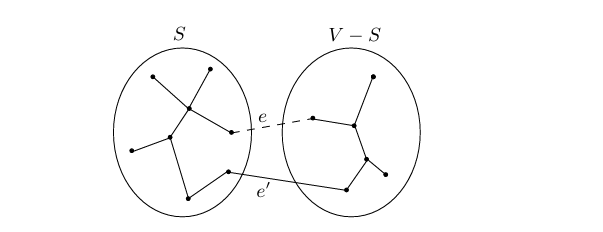
Kruskal’s algorithm
makeset(x):创建一个只包含x的单例集合find(x):x属于哪个集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
procedure kruskal(G, w)
Input: A connected undirected graph G = (V, E) with edge weights w_e
Output: A minimum spanning tree defined by the edges X
for all u \in V :
makeset(u)
X = {}
Sort the edges \( E \) by weight
for all edges {u, v} \in E , in increasing order of weight:
if find(u) ≠ find(v):
add edge {u, v} to X
union(u, v)
union(x,y): 融合包含x和y的两个集合Disjoint Sets的数据结构
Union by rank
1
2
3
4
5
6
7
procedure makeset(x)
π(x) = x
rank(x) = 0
function find(x)
while x≠π(x) : x=π(x)
return x
makeset是常数复杂度,find与树的高度成正比,树实际上还需要一个函数来构建uniun,我们必须要保证这个函数让树保持“浅”。当两个根融合\(r_x,r_y\)时,为了让树的高度尽可能矮,我们可以让更矮的树的根指向更高的树,通过这种方法,融合的树只有可能在两棵树等高的时候增加。
1
2
3
4
5
6
7
8
9
procedure union(x,y)
r_x = find(x)
r_y = find(y)
if r_x =r_y: return
if rank(r_x) > rank(r_y):
π(r_y) = r_x
else:
π(r_x) = r_y
if rank(r_x) = rank(r_y) : rank(r_y) = rank(r_y)+1
makeset产生的节点,秩为0,节点为1,满足\(|N|\geq 2^k\),对于基础情况成立
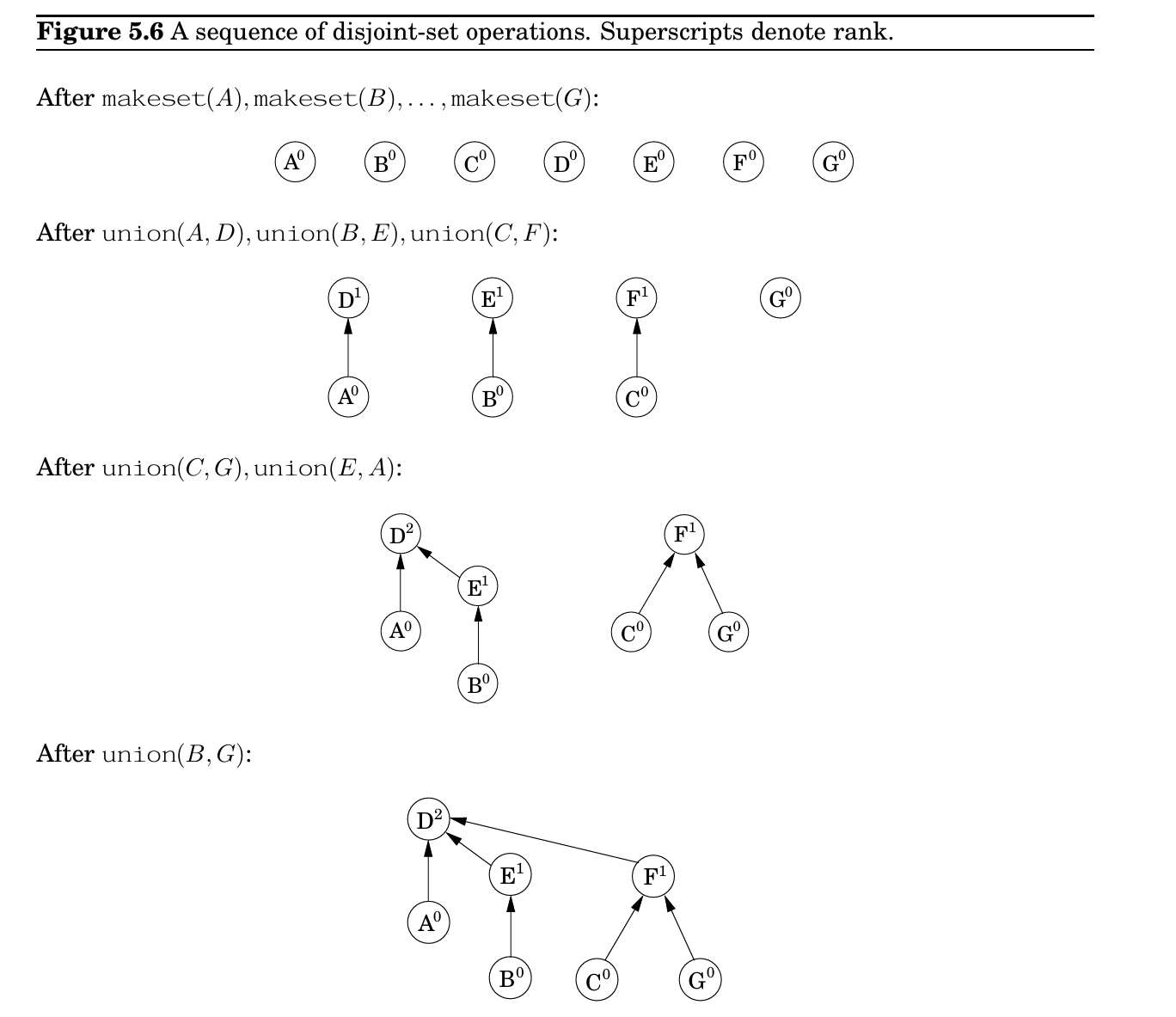
路径压缩
union,每次耗费最多\(O(\log{V})\),对每条边都要进行一次,所以时间复杂度是\(O(E\cdot \log{V})\)。这样的表现似乎已经足够好了,但是在
find函数的时候,将查找路径上的所有点的父节点改为这棵树的根
Prim’s Algorithm
Huffman encoding
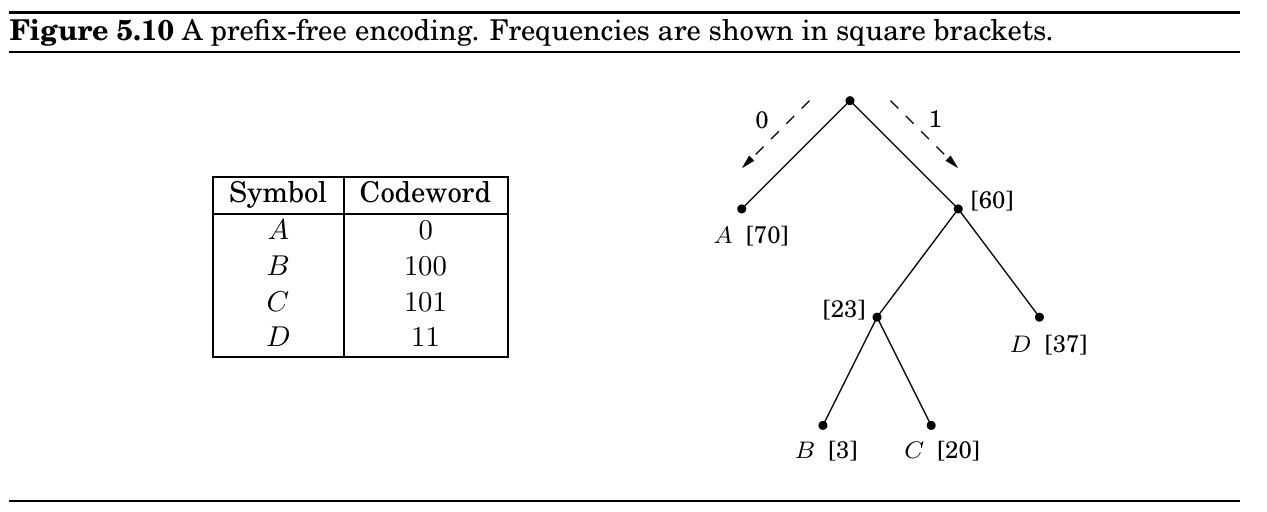
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
**procedure Huffman(f)**
Input: An array f[1 \cdots n] of frequencies
Output: An encoding tree with n leaves
let H be a priority queue of integers, ordered by f
for i = 1 to n:
insert(H, i)
for k = n + 1 to 2n - 1:
i = deletemin(H), j = deletemin(H)
create a node numbered k with children i, j
f[k] = f[i] + f[j]
insert(H, k)
从压缩的角度看待熵
Outcome
Aurora
Whirlwind
Phantasm
first
0.15
0.30
0.20
second
0.10
0.05
0.30
third
0.70
0.25
0.30
other
0.05
0.40
0.20
Set Union
动态规划
斐波那契数列
1
2
3
4
5
def fib(n):
if i <= 1:
return 1
else:
rertun fib(n - 1) + fib(n - 2)
1
2
3
4
5
6
7
8
9
10
11
12
def fib(n, memo=None):
if memo is None:
memo = {}
if n in memo:
return memo[n]
if n <= 1:
return n
memo[n] = fib(n - 1, memo) + fib(n - 2, memo)
return memo[n]
fib(n)的时候,可以发现我们需要从fib(1),fib(2)一直计算到fib(n),仔细分析拆解到最小步骤,即我们可以构造出大问题的解。并且对于fib(n)来说,只有fib(n-1),fib(n-2)有用,所以我们可以用常数级的内存储存所需数据。
1
2
3
4
5
6
7
8
9
def fib(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
最长递增子序列
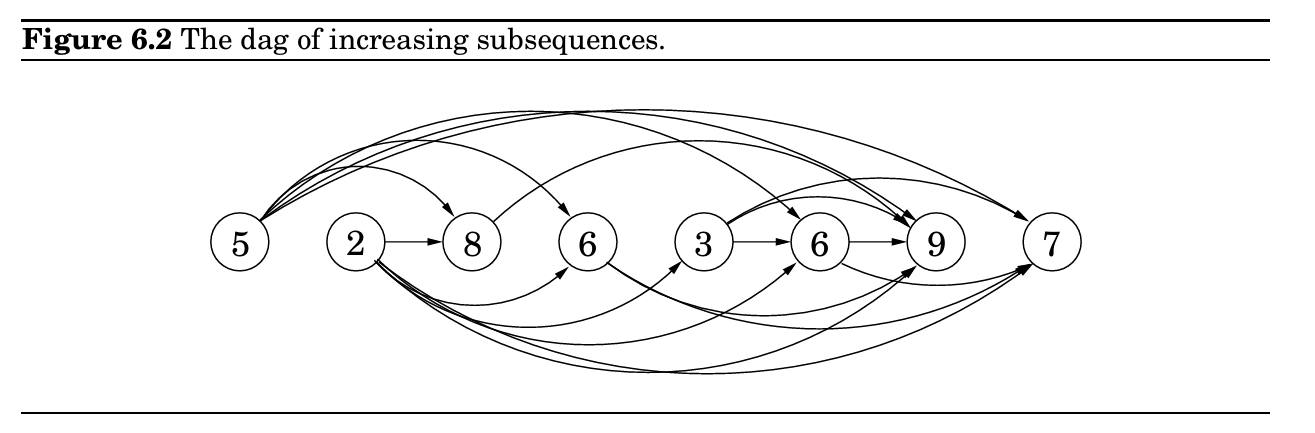
f(last, i) 为数组 A$i..n$ 中,以 A[last] 为上一个选择的元素,且后续所有选的元素都严格大于 A[last] 的最长递增子序列的长度。最终我们希望计算的是:
1
max_{i ≤ n} (f(i, i + 1) + 1)
[-∞] + A,也就是说假设我们永远先选了一个负无穷的元素。这样我们想要的最终结果就是 f(1, 2)(注意是 1-indexed),表示已经选了第一个元素(-∞),接下来在 A 的原始元素中选择。
1
2
3
4
5
6
f(last, i) = {
0 if i = n + 1
f(last, i + 1) if A[i] ≤ A[last]
max{f(last, i + 1),
f(i, i + 1) + 1} otherwise
}
拼写纠正
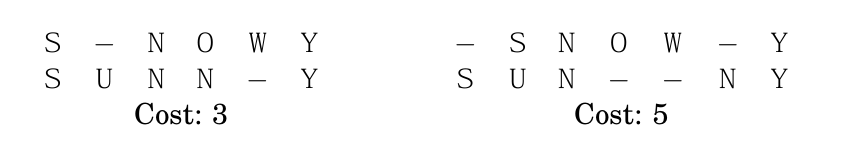
x[1 ... m]和y[1 ... n]的“编辑距离”。我们可以先研究小问题,比如研究两个单词的前缀x[1 ... i]和y[1 ... j],我们将这个问题称为E(i,j),因此我们的终极目标是求E(m, n)
x[i]对应空字符-y[i]对应空字符-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
memo = dict()
function EditDistance(i, j):
if (i, j) in memo:
return memo[(i, j)]
if i == 0:
return j
if j == 0:
return i
if x[i] == y[j]:
result = EditDistance(i - 1, j - 1)
else:
result = min(
EditDistance(i - 1, j) + 1,
EditDistance(i, j - 1) + 1,
EditDistance(i - 1, j - 1) + 1
)
memo[(i, j)] = result
return result
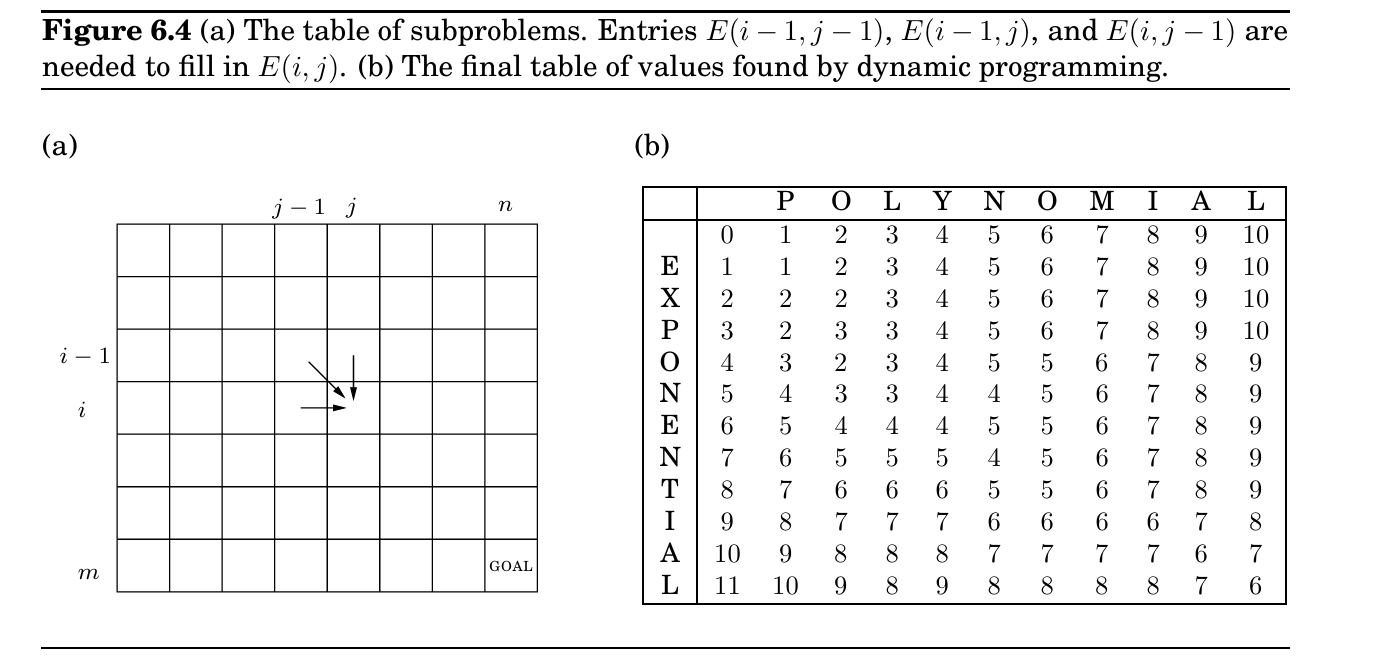
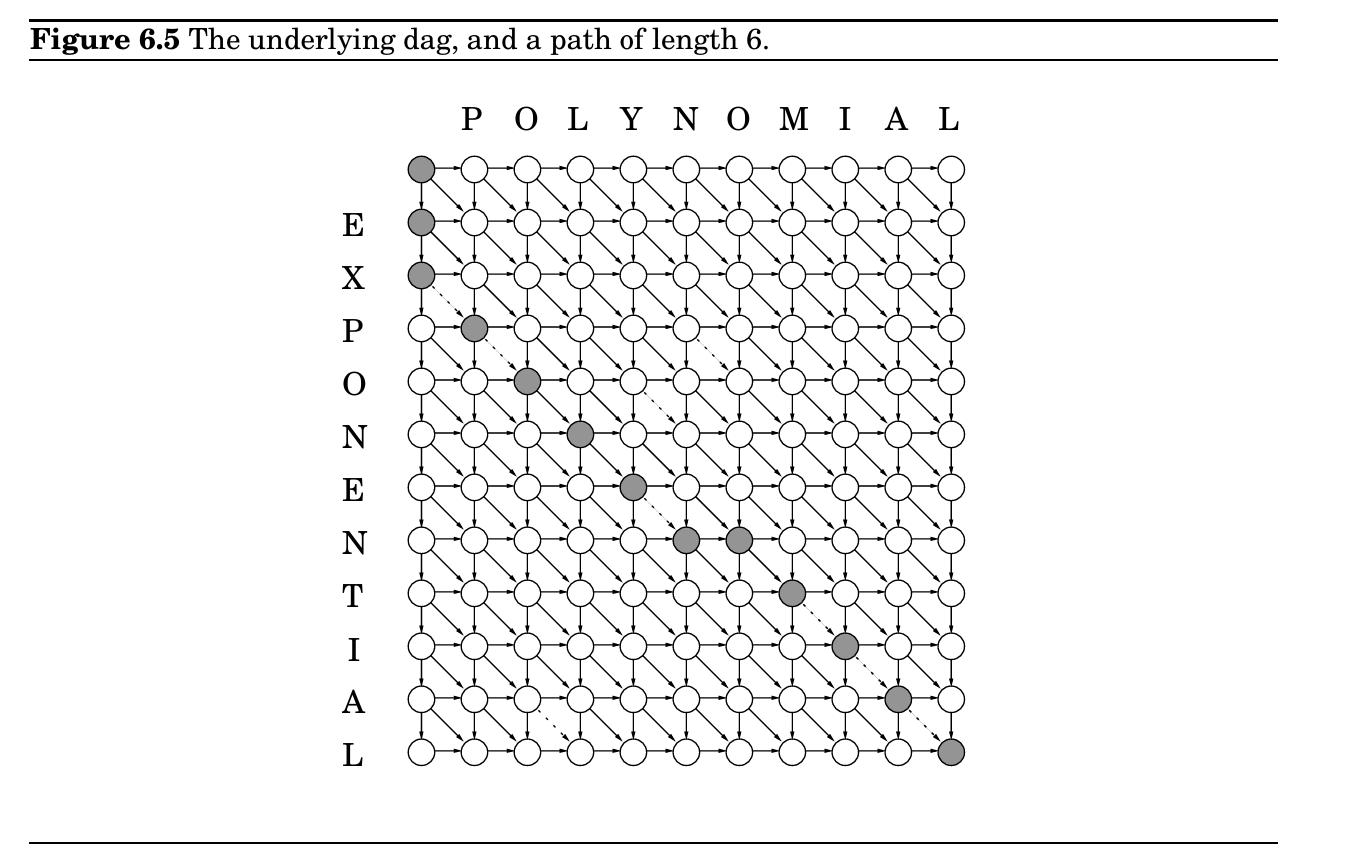
常见子问题
1
x₁ x₂ x₃ x₄ x₅ [x₆] x₇ x₈ x₉ x₁₀
1
2
[x₁ x₂ x₃ x₄ x₅ x₆] x₇ x₈ x₉ x₁₀
[y₁ y₂ y₃ y₄ y₅] y₆ y₇ y₈
1
x₁ x₂ [x₃ x₄ x₅ x₆] x₇ x₈ x₉ x₁₀
背包问题
物品
重量
价值
1
6
30蚊
2
3
14蚊
3
4
16蚊
4
2
9蚊
可重复的背包问题
1
2
3
4
K(0) = 0
for w = 1 to W:
K(w) = max{K(w − wi) + vi : wi ≤ w}
return K(W)
无重复的背包问题
1
2
3
4
5
6
Initialize all K(0, j) = 0 and all K(w, 0) =0
for j = 1 to n:
for w = 1 to W:
if w_j > w: K(w, j)=K(w,j − 1)
else: K(w, j) =max{K(w, j − 1),K(w − w_j, j − 1)+v_j}
return K(W, n)
记忆体的优势
矩阵乘法优化
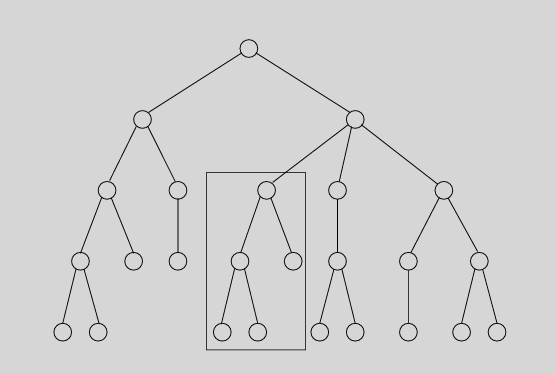
加括号方式
乘法计算过程
总花费
\(A \times ((B \times C) \times D)\)
\(20 \cdot 1 \cdot 10 + 20 \cdot 10 \cdot 100 + 50 \cdot 20 \cdot 100\)
120,200
\((A \times (B \times C)) \times D\)
\(20 \cdot 1 \cdot 10 + 50 \cdot 20 \cdot 10 + 50 \cdot 10 \cdot 100\)
60,200
\((A \times B) \times (C \times D)\)
\(50 \cdot 20 \cdot 1 + 1 \cdot 10 \cdot 100 + 50 \cdot 1 \cdot 100\)
7,000
1
2
3
4
5
6
7
8
9
10
11
12
for i = 1 to n:
C(i, i) = 0
for s = 1 to n - 1: # 子区间长度
for i = 1 to n - s: # 左端点
j = i + s # 右端点
C(i, j) = min { # 枚举分割点 k
C(i, k) + C(k+1, j) + m[i-1] * m[k] * m[j]
for i <= k < j
}
return C(1, n)
Bellman-Ford算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def BF(G, s):
# T[t][0] = 上一轮的最短距离,T[t][1] = 当前轮的最短距离
T[1..n][0..1] = all inf # 初始化为无穷大
T[s][0] = 0 # 源点 s 到自己的距离是 0
for k in range(1, n): # 最多进行 n-1 轮松弛
for t in range(1, n+1): # 初始化当前轮
T[t][1] = T[t][0]
for (v, t) in E: # 遍历每一条边 v → t
T[t][1] = min(T[t][1], T[v][0] + w(v, t)) # 松弛操作
for t in range(1, n+1): # 准备下一轮
T[t][0] = T[t][1]
return T[1..n][1] # 返回最终的最短距离(最后一轮的结果)
线性规划
Simplex算法
1
2
3
function LONGEST PATH(G)
将G的所有边权重取反
return SHORTEST PATH(G)
网络流
Ford-Fulkerson算法
正确性分析

对偶性
乘子
对应的不等式
\(y_1\)
\(x_1 \le 200\)
\(y_2\)
\(x_2 \le 300\)
\(y_3\)
\(x_1 + x_2 \le 400\)

零和游戏