TL;DR
本文讲解了 Diffusion 和 Flow model 的数学原理,包括 Diffusion 中的 DDPM 和 DDIM 模型。整体来说,DDPM 至 DDIM 再到 Flow model 呈现清晰的渐进发展的趋势,体现为逐渐舍弃带有随机性的高斯分布的影响,而是在反向过程和正向过程中引入确定性的步骤。推荐将三者作为一个脉络研究。 本文主要从概率角度理解,缺少了 ODE 和 SDE 的视角,未来如果有机会可以考虑补上。
Reference
Diffusion model
生成式模型的目标是:
从多个在未知分布中独立同分布的数据中,提取出一个新的样本,是从分布中提取的
Diffusion model也一样,它想从目标分布(如狗的图像)中采样出一个点。但是从初始的简单分布(如高斯分布)中推导到复杂的目标分布难以实现。所以Diffusion先反过来,研究怎么将一个多峰的复杂分布简化为一个简单的正态分布,再反过来研究怎么反向降噪,实现对复杂分布的采样。
Notation
在讲解数学原理前,先详细解释一下数学标号:
因为统一不同分步数量而导致的公式差异,所以将约束为在0到1之间的连续的数。
Gaussian Diffusion
Gaussian Diffusion作为一个正向Diffusion过程,假定作为一个在中随机变量,然后构建一系列随机变量,用表示在离散时间的,有:
对此,由于,有的分布:
为了让最终方差与最终设定的噪音强度相等,所以要求每一步的,因此,Gaussian Diffusion的最终表述为:
同理:
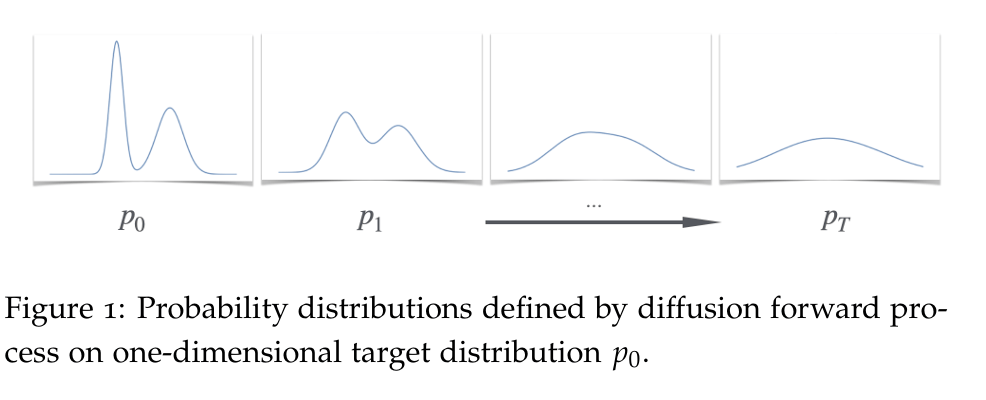 这张图展示了Gaussian Diffusion由一个多峰分布最终转化为一个正态分布的过程。
这张图展示了Gaussian Diffusion由一个多峰分布最终转化为一个正态分布的过程。
反向采样
有了怎么从一个目标分布到正态分布的正向过程,现在追求通过构建一个反向采样器来达到这个目的:给定一系列边际分布 ,步骤 t 的反向采样器是一个潜在的随机函数,这样如果 ,则 的边际分布恰好是 :
为了证明这个反向采样是存在且可行的,先用一个不严谨的例子给一点感觉(intuition): 对于较小的 σ 和正向过程中定义的高斯扩散过程,条件分布本身接近高斯分布。也就是说,对于所有时间 t 和条件 ,存在一些平均参数 使得:
注
和的分布是一个东西
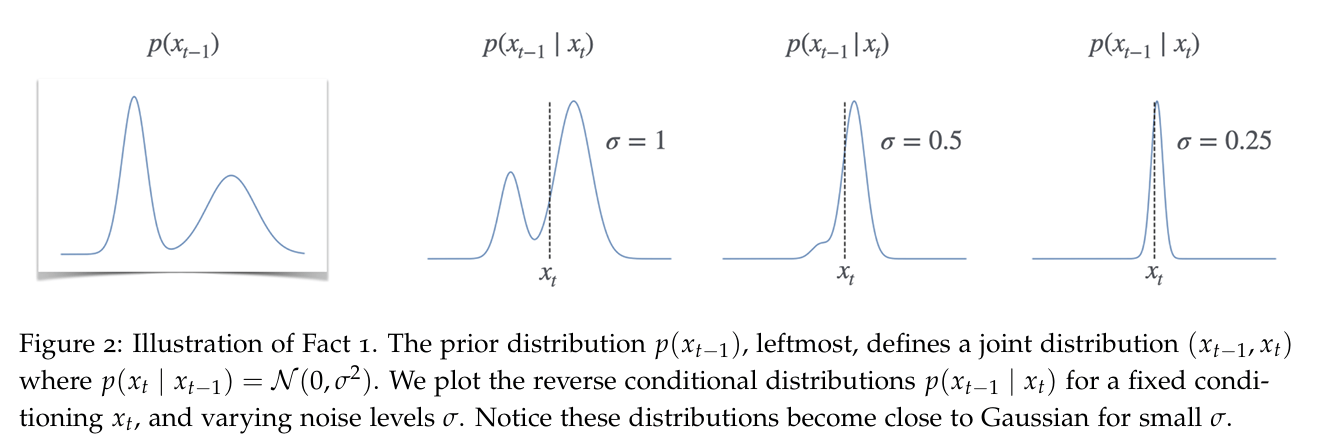
随机采样DDPM成立性证明
这个算法成立的基础是: Claim 1 (Informal). 令 为 上任意足够平滑的密度函数。考虑 的联合分布,其中 且 。那么,对于足够小的 ,下式成立。对于所有条件变量 ,存在 使得:
其中常数 仅取决于 。此外,取以下定义即可:
其中 是 的边缘分布。
注意
是Score函数,由Tweedie 公式,可以转化为
此处由神经网络等模型拟合。
Proof of Claim 1 (Informal). 这里有一个启发式论证,说明为什么“分数(score)”会出现在反向过程中。我们基本上只需应用贝叶斯定理,然后进行适当的泰勒展开。我们从贝叶斯定理开始:
然后对两边取对数。在整个过程中,我们将舍弃对数中的任何加性常数(它们会转化为归一化因子),并舍弃所有 阶的项。注意,在此推导中,我们应将 视为常数,因为我们想要了解作为 函数的条件概率。现在:
除了加性因子外,这与均值为 、方差为 的正态分布的对数密度相同。因此:
回顾这一推导过程,其核心思想是:对于足够小的 ,反向过程 的贝叶斯展开主要由前向过程中的 项主导。这在直觉上解释了为什么反向过程和前向过程具有相同的函数形式(此处均为高斯分布)。
训练目标
如此,可以把复杂的生成问题转为一个回归问题,只需要学习即可:
这些算法理论上成立,但是用神经网络拟合的时候,主要是高斯噪音,模型分不清哪些是要生成的特征,哪些是噪音。将训练目标改为预测可以有效减小方差(等效地估计所有先前噪声步骤的平均值,而不是估计单个噪声步骤,方差小得多)。 由于前向过程中每一步的噪音都是相互独立的,单步噪音是总噪音的,由此有:
或等价的:
但是Diffusion model的工作原理没变,只是预测每一小步的噪音。
确定性DDIM正确性证明
但是DDPM因为要细分成很多步,而每步都需要通过神经网络预测方向,这导致速度奇慢。这也提出了新的问题:
因此提出了确定性的DDIM算法:
注意: 是一个缩放系数,这个算法的逻辑是新位置 = 老位置 + 步长 移动方向
想要证明这个反向采样器是正确的,因为它是一个确定性的采样器,用类似DDPM那种从 随机采样是行不通的。只能通过证明这个方程表示了一个有效的映射,在边际分布 和 间。
这个证明等价于对于:
我们想证明:
注
- 和DDPM中的神经网络一致;
- 是一个从向量映射到向量的函数,分布中每一个向量通过映射获得新的向量集构成新的分布;
- 如果 那么 的分布就是 pushforward 测度 ;
- 此部分设计测度论,如果想深入了解可以参阅测度论的教材。
Case1: Single point
让我们首先尝试目标分布 是 中的单点质量的简单情况。不失一般性,我们可以假定那个点是 。为了验证DDIM算法是准确的,我们希望考虑任意步长 下 和 的分布。根据扩散前向过程,在时刻 相关的随机变量为:
的边缘分布是 ,而 的边缘分布是 。
让我们首先寻找某个确定性函数 ,使得 。虽然有许多可能的函数可行,但最明显的一个是:
上述函数 简单地重新缩放 的高斯分布,以匹配 高斯分布的方差。事实证明,这个 正好等价于算法 2 所采取的步骤 ,我们接下来将展示这一点。
断言 3. 当目标分布是一个点质量 时,更新 (如公式 35 所定义)等价于缩放 (如公式 37 所定义):
因此,算法 2 定义了针对目标分布 的反向采样器。 证明. 要应用 F_t,我们需要为我们的简单分布计算 。由于 是联合高斯分布,因此有:
其余部分即是代数运算:
因此我们得出结论:算法 2 是一个正确的反向采样器,因为它等价于 ,且 是有效的。
即使 是一个任意点而不是 ,算法 2 的正确性依然成立,因为所有事物都具有转移对称性。
可以把DDIM的更新视作速度场,使在 时刻的点向他们 时刻的位置移动,具体来说,可以把向量场定义为:
于是DDIM更新可以写作:
Case2: Two Points
现在让我们证明当目标分布是两点混合时算法 2 是正确的:
根据扩散的前向过程,在时间 的分布是一个混合高斯分布:
我们想要证明的是式(40)中的速度场 可以完成分布转换:。
首先我们尝试构建一个满足反向采样 的正确的速度场 。由于 Case1 的结果对单个点是成立的,那么速度场可以将 的每个混合分量进行转换。即存在一个速度场 :
可以对 进行转换:
同理 的速度场 也成立。
为了将两个速度场合并成 来表示:
直观地取速度场的平均是错的,应该是独立速度场的加权:
其中, 的权重是点从 中生成的概率,而不是从 的概率。
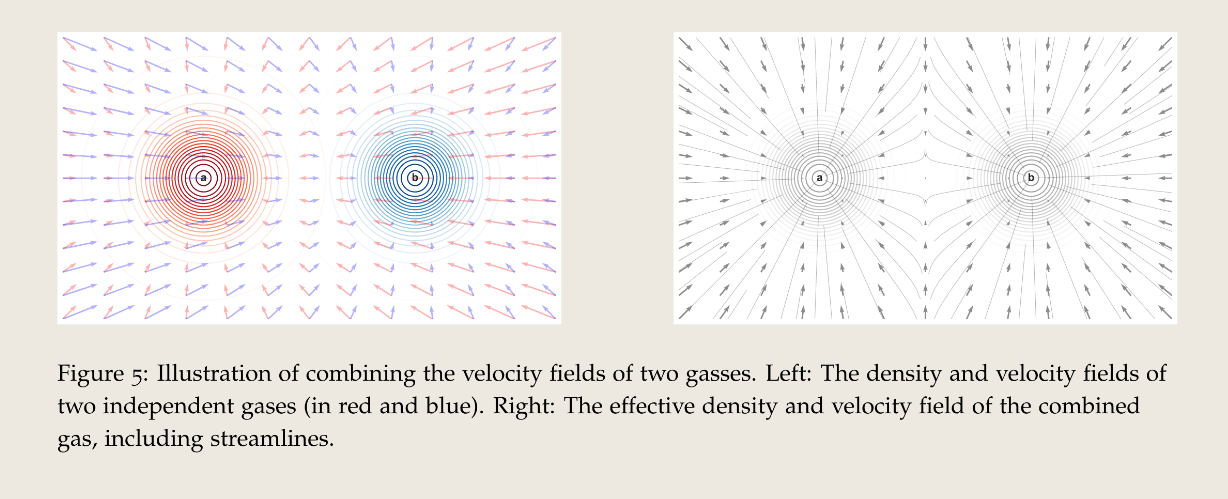 以气体为例子,左图中的左部点虽然针对 的速度大于 的速度(因为离 远,需要加速收敛到 的分布内),但是对 的权重低(离 远,在 生成的概率就低)。所以最后在右图生成了一个向 的速度。
以气体为例子,左图中的左部点虽然针对 的速度大于 的速度(因为离 远,需要加速收敛到 的分布内),但是对 的权重低(离 远,在 生成的概率就低)。所以最后在右图生成了一个向 的速度。
接下来我们需要证明式子 和 相同,首先考虑单个向量场 可以写作一个条件期望,根据式(45)中的定义 :
那么 可以写为一个条件期望:
Case3: 任意分布
现在我们知道如何处理两个点,我们可以将这个想法推广到 的任意分布。我们不会在这里详细讨论,因为一般证明将包含在后续部分中。事实证明,我们算法 2 的整体证明策略可以显着推广到其他类型的扩散,而无需太多的工作。这就产生了流匹配的想法,我们将在下一节中看到。一旦我们开发了流机制,实际上就可以直接从方程(37)的简单单点缩放算法直接导出 DDIM:请参见原论文附录 B.5
SDE视角下的扩散&概率流常微分方程
论文中说可选,暂时没读,或许以后还需要深入理解的时候会读。
DDPM和DDIM
回顾之前提出的公式和算法:
前面说到,从DDPM转到DDIM的主要动机是因为DDPM需要过太多次模型 了,但是又不能通过减小步数的方法,因为随机的性质导致减小步数会导致崩坏。而DDIM用确定性的方法规避了这个问题,可以通过减小步骤的方法来减小生成的时间。
Flow model
Flow model 其实是 DDIM 算法的一种泛化,Flow model的核心思想和 DDIM 中介绍的相差不大:
- 首先,我们定义了如何生成单点。具体来说,我们构建了向量场 ,当应用于所有时间步时,将标准高斯分布传输到任意 delta 分布 。
- 其次,我们确定如何将两个矢量场组合成单个有效矢量场。这让我们可以构建从标准高斯到两个点的传输(或者更一般地说,到点上的分布 - 我们的目标分布)。 其中任意一点都不需要高斯采样,所以可以完全舍弃高斯分布的正向分布,提出Flow model。
Flow
首先先定义 Flow 是啥:flow是一个随时间演进的向量场的集合 ,换成物理概念可以理解为是一个气体在不同时间 构成的集合。任何一个flow都定义了一条从初始点 到最终的点 的轨迹。 对于 flow 和初始点 ,考虑常微分方程(ODE)对应的离散时间迭代 :
在 初始点为 ,将:
看作 flow ODE 在时间 的解,终点是 。也就是说 RunFlow 是将 验着 flow 移动到时间 的结果。 flow 不仅定义了初始点和终点的映射,其实也定义了整个分布的转换。如果 是初始点的分布,那么经过 flow 终点的分布是:
在这个过程中,还是用气体来比拟,起点即初始状态是分子服从分布 的气体,然后气体中的每个分子的轨迹由 flow 来决定,那么这个气体(这些分子)最终的分布是 。 Flow Matching 的最终目标是:学习一个 flow 使得 ,其中 是目标数据分布, 是某个简单的基础分布(比如高斯分布)。如果拥有 ,我们可以这样从 生成样本:先从基础分布 中采样得到 ,然后通过得到的 flow 输入是 输出是最终的 。DDIM 算法这类方法的一个 case,现在我们如何构建更通用的 flow 呢?
Pointwise Flows & Marginal Flows
Flow的最基础单元室单点的flow,将一个点 移动到 。直观上,给定一个联系 和 的任意路径 ,一个 pointwise flow 描述了这个轨迹:由给定速度 下的每个点 构成,如下图所示:
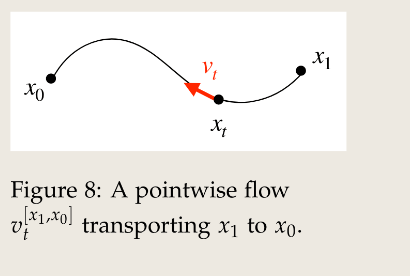 正式的表述:一个 pointwise flow 是起点为 、终点为 且满足式(59)的任意 flow ,记作 。这样的 pointwise flow 有很多,不是唯一的。
正式的表述:一个 pointwise flow 是起点为 、终点为 且满足式(59)的任意 flow ,记作 。这样的 pointwise flow 有很多,不是唯一的。
有了逐点的流后,我们可以像 DDIM 的双点的证明一样,我们需要一个 flow 来实现分布间的转换,可以采用加权平均的方式,权重是每个分子通过各自的pointwise flow 在 出现的概率,即
上面的期望关于联合分布 的期望:通过采样 然后得到 。
这提出了两个问题:
- 我们应该选择什么样的pointwise 和coupling
- 如何计算marginal flow ? 我们无法直接根据式(64)计算,因为需要在给定的 从 中采样,非常复杂。
这个问题的提出是很自然的:在完全舍弃高斯分布带来的随机性后,提出了两个问题:
- 要怎么选取原本正向过程会提供的训练集 ,简单的是独立采样,各采各的随机配对。但也可以用更聪明的配对(比如 optimal transport coupling),让轨迹更短、训练更高效。
- 以及 和 之间怎么走。最常用的是线性插值 ,但理论上可以是任意路径。
Pointwise flow的一种简单选择
考虑简单的情况,我们需要选择简单的 pointwise flow,基础分布 和 coupling 。虽然高斯分布是一个简单的基础分布但不是唯一的选择,也有其他的,比如的环形分布也是基础分布。
至于 coupling,最简单的选择是独立 coupling,即从 和 中各自采样。其中 和 是终点和起始点的分布。
对于 pointwise,最简单的是 linear pointwise flow:
如上式中,只是在 和 之间做了线性插值。linear pointwise flow 的一个 marginal flow 例子如下图所示:基础分布 是一个环状的均匀分布,目标分布 是位于 的狄拉克函数。灰色箭头描绘了在不同时间 的 flow 场。最左边是基础分布,最右边所有点坍缩到一个点即目标点上。这里 恰好是前面螺旋分布上的一个点。
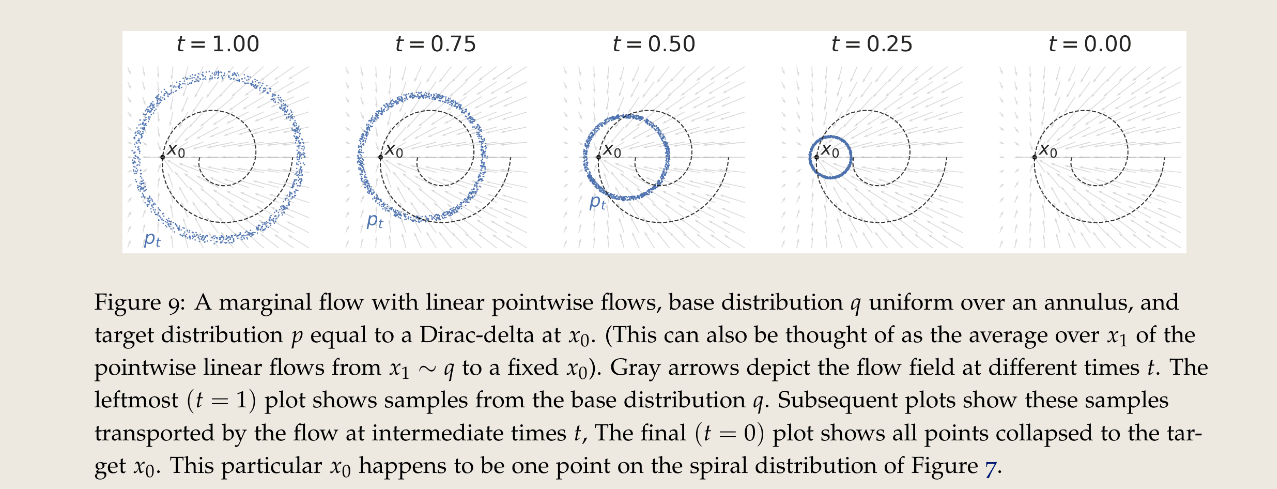
剩下的问题是:在这种情况下,如果所有训练点都是随机抽取的,要怎么实现在训练中的加权呢? 我们可以借鉴DDIM的解决方法,用我们可以从联合分布 中采样足够多的样本,然后作为回归问题来解决。类似DDPM中的处理,式(64)中的条件期望函数可以写作:
这样,我们就可以把训练集从 空间中选取点来学习每对 被采到的概率确实相等。但不同的配对在同一个时间 会产生不同位置的 。在某些位置,很多条轨迹汇聚经过,网络在那里收到大量不同方向的监督信号。在另一些位置,只有少数轨迹经过,监督信号方向比较一致。
最后模型通过神经网络实现了对加权的拟合,而不是通过建模的方式来实现加权。
最基础的 Flow matching 代码:
# code 1 Standalone Flow Matching code
# flow_matching/examples/standalone_flow_matching.ipynb
import torch
from torch import nn, Tensor
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
class Flow(nn.Module):
def __init__(self, dim: int = 2, h: int = 64):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim + 1, h),
nn.ELU(),
nn.Linear(h, h),
nn.ELU(),
nn.Linear(h, dim),
)
def forward(self, x_t: Tensor, t: Tensor) -> Tensor:
return self.net(torch.cat((t, x_t), -1))
def step(self, x_t: Tensor, t_start: Tensor, t_end: Tensor) -> Tensor:
# Euler's method with midpoint ODE solver in this example
# For simplicity, using midpoint ODE solver in this example
x_mid = (t_end - t_start) / 2
x_t += (t_end - t_start) * self(x_t + self(x_t, t_start) * x_mid, t_start + x_mid)
return x_t
# training
flow = Flow()
optimizer = torch.optim.Adam(flow.parameters(), 1e-2)
loss_fn = nn.MSELoss()
for _ in range(10000):
x_1 = Tensor(make_moons(256, noise=0.05)[0])
x_0 = torch.randn_like(x_1)
t = torch.rand(256, 1)
x_t = (1 - t) * x_0 + t * x_1
dx_t = x_1 - x_0
optimizer.zero_grad()
loss = loss_fn(flow(x_t, t), dx_t)
loss.backward()
optimizer.step()
# sampling
n_steps = 8
x = torch.randn(300, 2)
time_steps = torch.linspace(0, 1, n_steps + 1, device=x.device)
fig, axes = plt.subplots(1, n_steps + 1, figsize=(30, 4), sharex=True, sharey=True)
for i, t in enumerate(time_steps):
axes[i].scatter(x[:, 0], x[:, 1], s=10)
axes[i].set_title(f't = {t:.2f}')
axes[i].set_xlim(-3, 3)
axes[i].set_ylim(-3, 3)
for i in range(n_steps):
x = flow.step(x, time_steps[i], time_steps[i + 1])
axes[-1].scatter(x[:, 0], x[:, 1], s=10)
axes[-1].set_title(f't = {time_steps[-1]:.2f}')
axes[-1].set_xlim(-3, 3)
axes[-1].set_ylim(-3, 3)
plt.tight_layout()
plt.show()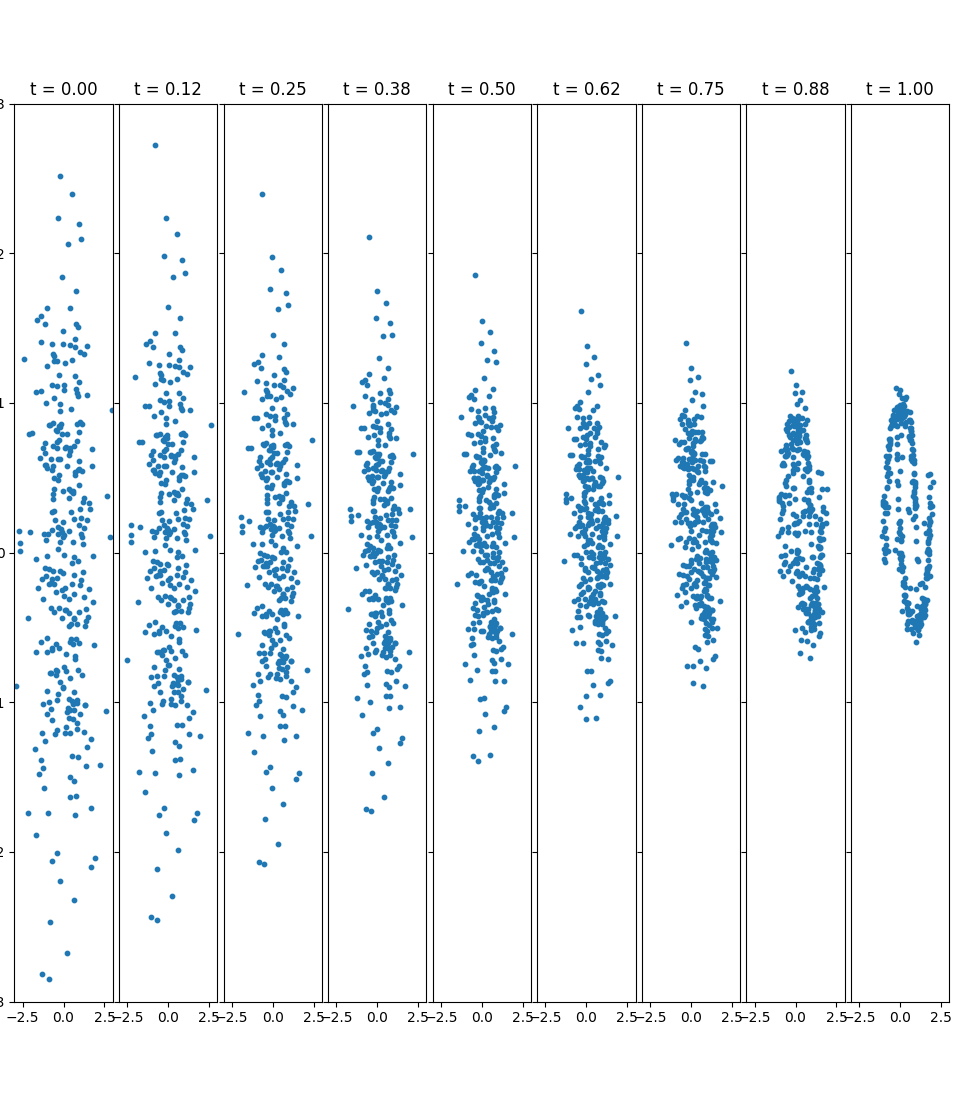 代码中流匹配函数的
代码中流匹配函数的step采用以下复杂形式的原因是不同于普通的欧拉法 ODE ,采用中点法的 ODE 求解器 可以获得更高的精度。
def step(self, x_t: Tensor, t_start: Tensor, t_end: Tensor) -> Tensor:
# Euler's method with midpoint ODE solver in this example
# For simplicity, using midpoint ODE solver in this example
x_mid = (t_end - t_start) / 2
x_t += (t_end - t_start) * self(x_t + self(x_t, t_start) * x_mid, t_start + x_mid)
return x_t