论文原文:(H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation | PDF) 本文章希望能根据论文切入口的思路来完成。
论文动机
目前的各种模型都基本基于遥操作等学习的方法,导致可学习数据稀缺,且各类机械臂的形态各异,限制了数据的可获取性。
论文思路
对此,论文提出可以使用使用Egocentric的人手视频进行训练,相较于先前的研究,论文提出使用H-DRT模型——一个Diffusion Transformer模型来将人类行为转为机器人动作,以解决:
- 数据稀缺性
- Cross-Embodied-transfer困难
- 训练效率问题
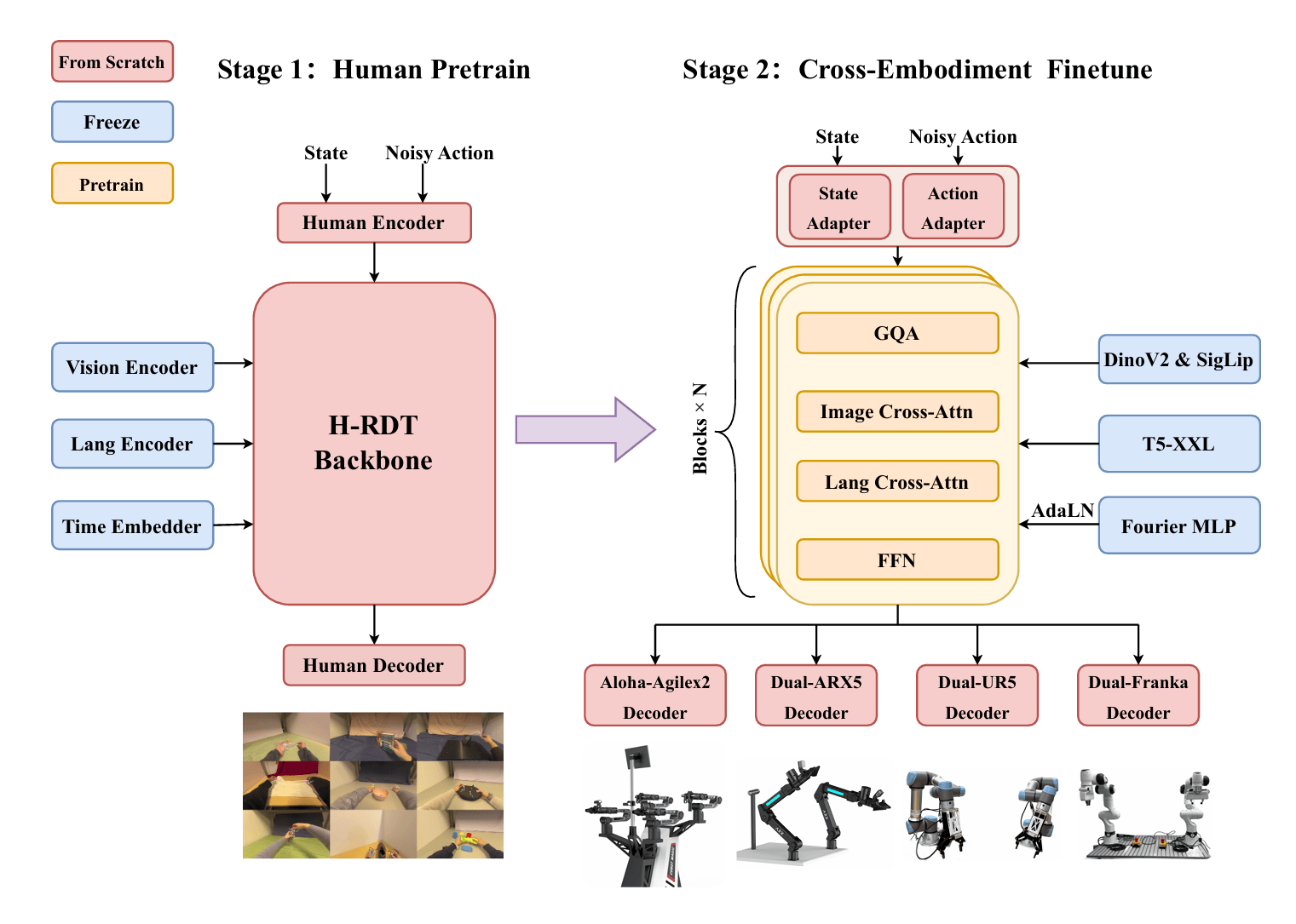
模型构造
研究使用了开源的DinoV2 & SigLip作为Vision encoder,T5-XXL作为Lang encoder, Fourier MLP作为时间embedder。在输入端同时采用了由因机械臂而异的State adapter和Action adapter用于将不同维度的机械臂数据转为同维度。同时只改变adapter使得预训练时期的人手数据可以得到较好保留。(Lang是Image和Language的corss attention) 在H-EDT Backbone采用了四个主要部分。其中GQA是attention.py中的改良版的多头注意力机制,即用多个Q和少量的K/V矩阵,减少性能消耗。之后使用两个corss-attention和一个前馈神经网络。最后接上因机械臂而异的. 模型使用了一个Diffusion Transformer作为模型的骨干网络,其中在Vision and Language Encoders, Modular Action Encoder, Transformer Backbone和Modular Action Decoder中采用transformer模型,并在动作生成处使用了flow matching模型来获得一个向量场。 在训练中,论文通过减小损失函数:
- :真实的动作序列(ground truth)。
- :由高斯分布采样的噪声。
- :在时间 的插值点,位于 与真实动作 之间。
- :条件(视觉、语言、机器人状态等)。
- :flow model 参数化的向量场预测器(由 Transformer 来实现)。
模型训练由两个阶段:第一个为接受人类的egocentric视频和动作描述,输出预测的向量场。随后进行fine tune——用多种机器人的数据进行训练,使得模型具有cross-embodiment。
代码学习
模型主要包含一下几个文件:
- encoder
- base_vision.py
- dinosiglip_vit.py
- t5_encodr.py
- hrdt
- attention.py
- blocks.py
- model.py
- norm.py
- pos_emb.py
- time_noise.py
- hrdt_runner.py 其中encoder中的三个文件主要负责对图像,文字等的encode和embed并输入模型。
观察代码发现现在的transformer设计思路和初代transformer有多处不同。 上述提到的GQA在attention.py中体现了改进的多头注意力,用repeat_kv来实现来实现多个Q矩阵和少量KV矩阵,因为KV矩阵含有的信息差异较小,如此可以减小计算量,与初代论文多个注意力复制而成的多头注意力机制有所不同。 而cross attention则是在block.py中。观察代码,发现多处与初代transformer不同的地方:比如本研究中的归一化是在计算注意力之前进行的。以及在block.py文件中:
h = x + gate_attn.unsqueeze(1) * self.attn(
modulate(self.attn_norm(x), shift_attn, scale_attn))
# Image cross-attention (always present)
img_c = cross_contexts.get('img_c')
if img_c is not None:
h = h + gate_cross.unsqueeze(1) * self.img_cross_attn(
modulate(self.img_cross_norm(h), shift_cross, scale_cross),
self.img_cond_norm(img_c), None)
# Language cross-attention
lang_c = cross_contexts.get('lang_c')
lang_attn_mask = cross_contexts.get('lang_attn_mask')
if lang_c is not None:
# Apply additional cross-attention for language using same modulation parameters
h = h + self.lang_cross_attn(
self.lang_cross_norm(h),
self.lang_cond_norm(lang_c), lang_attn_mask)在计算cross attention的时候会同时采用门控和调制的控制方法,让训练更好地适应diffusion模型。
然后在model.py中
def forward(self, x, t, img_c=None, lang_c=None, sentence_c=None, task_c=None, lang_attn_mask=None):
"""
Forward pass of H-RDT
Args:
x: (B, 1 + T, D), state and action token sequence, T = horizon
t: (B,) or (1,), diffusion timesteps
img_c: (B, S_img, D), image features for cross-attention, optional
lang_c: (B, S_lang, D), language tokens for cross-attention, optional
sentence_c: ignored (for backward compatibility)
lang_attn_mask: (B, S_lang), attention mask for language tokens, optional
Returns:
x: (B, T, D_out), predicted denoised action tokens
"""
# Embed timestep using sinusoidal embeddings
t_emb = self.t_embedder(t) # (B, D) or (1, D)
if t_emb.shape[0] == 1:
t_emb = t_emb.expand(x.shape[0], -1) # (B, D)
# Add position embeddings
x = x + self.x_pos_emb
if img_c is not None:
img_c = img_c + self.img_pos_emb[:, :img_c.shape[1]]
if lang_c is not None:
lang_c = lang_c + self.lang_pos_emb[:, :lang_c.shape[1]]
# Pass timestep embedding directly to blocks (no sentence token)
for i, block in enumerate(self.blocks):
cross_contexts = {
'img_c': img_c,
'lang_c': lang_c,
'lang_attn_mask': lang_attn_mask
}
if self.gradient_checkpointing and self.training:
x = torch.utils.checkpoint.checkpoint(block, x, t_emb, cross_contexts, use_reentrant=False)
else:
x = block(x, t_emb, cross_contexts)
# Final layer only uses timestep (no cross-attention)
x = self.action_decoder(x, t_emb)
# Extract action predictions
x = x[:, -self.horizon:]
return x所有数据先经过pos_emb之后传入block进行self和cross attention。之后传进action_decoder,完成向量场的预测。成功输出动作。
不足
现在感觉目前的认知和实践有一下不足:
- 对代码的架构不太明白。
- VLA, transformer等模型有些地方不是很理解。数学上的(比如说维度)概念上的,架构上的。可能通过实践或者多读论文来缓解
- flow model的数学原理读了多遍还是不懂(不是很急)
- 论文阅读还是太少。